

本文来自港科与 MIT 教授团队。本文有两个共同一作:张鉴殊为武汉大学本科四年级,本篇为其在港科大访问期间完成,将于 2025 秋季前往美国西北大学攻读 CS PhD。姚栋宇目前就读于 CMU CS 系下的 MSCV 项目。

-
论文链接:https://arxiv.org/pdf/2502.12084 -
项目主页:https://vlm2-bench.github.io/
当前,视觉语言模型(VLMs)的能力边界不断被突破,但大多数评测基准仍聚焦于复杂知识推理或专业场景。本文提出全新视角:如果一项能力对人类而言是 “无需思考” 的本能,但对 AI 却是巨大挑战,它是否才是 VLMs 亟待突破的核心瓶颈?
基于此,该团队推出 VLM²-Bench 来系统探究模型在 “人类级基础视觉线索关联能力” 上的表现。
本文将如下的两点作为本工作的出发点:
-
什么能力对于人类来说是在日常生活中非常重要,且这种能力还得是对人们来说非常容易的,不需要庞大的知识储备也能完成。
我们在浏览不同的照片时可以找到出现在多张照片的同一个人,但是我们并不需要在之前就见过这个人,叫得出名字或者对这个人很了解,而是简单的在不同的图片间通过脸部特征在视觉上的比对和关联。同理我们还会拿着喜欢球鞋的图片去线下门店比对挑选出一样的款式(如下图),而不需要知道这个鞋的具体产品型号,只需要把鞋的花纹这一视觉特征给关联起来即可。这种视觉关联的能力显然是不依赖于先验知识,是纯粹基于视觉侧的关联。

日常生活中我们经常利用“视觉关联”,比如图中这个男孩正拿着手机上的图片去线下门店一一比对,来挑选出一样的球鞋款式(图片由AI生成)
-
为什么这种能力对于现在 VLMs 也是非常重要的?
随着 VLMs 从单图处理扩展到多图、视频输入,其视觉感知的广度和深度显著提升。然而,视觉内容的扩展并未带来对视觉线索关联能力的同步提升,而 VLMs 时需要具有 “回头” 关联视觉线索的能力来帮助在其更一致且和谐的理解世界。
VLM²-Bench 的设计
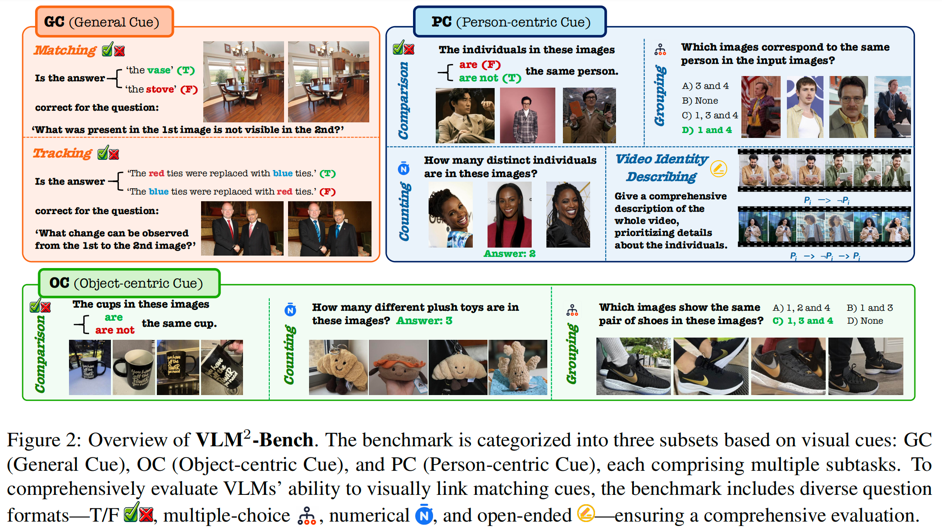
-
全面考察 VLMs 对于通用线索 GC(General Cue)、物体线索 OC(Object-centric Cue)和人物线索 PC(Person-centric Cue)三个大类的基础关联能力,总共可分为 9 个子任务,同时涵盖多图和视频的测试数据,共计 3060 个测试案例。 -
评测问题的形式包含了判断题、多选题、数值题、开放题,其中对于每种形式我们都设计了特定的评估方式来更好的反应模型的性能。 -
结合人工验证与自动化过滤,同时确保数据质量与挑战性。
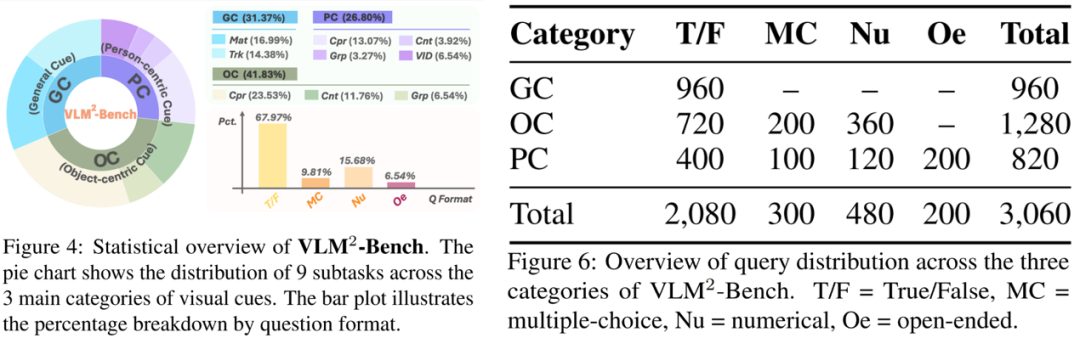
以上是 VLM²-Bench 统计数据。
实验与发现
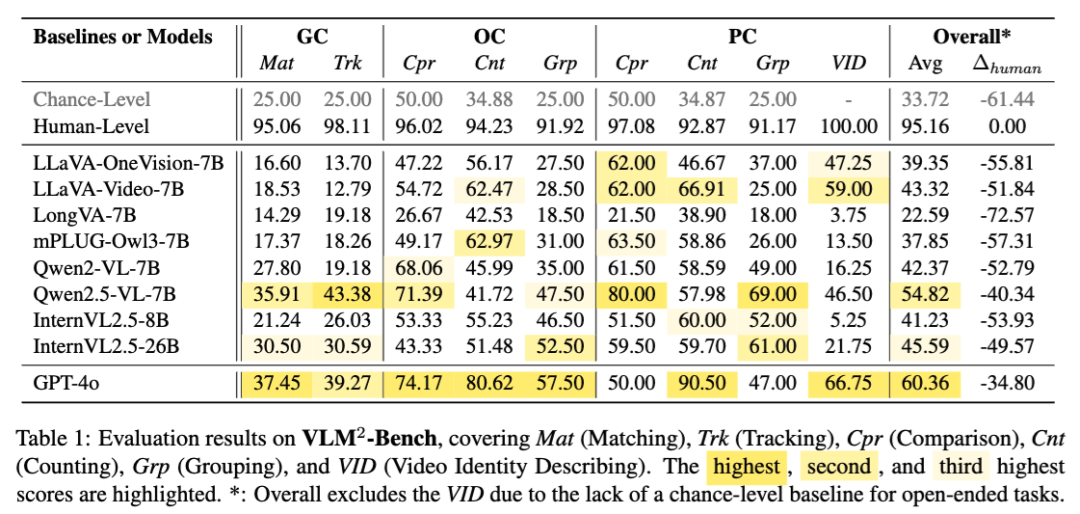
这里我们引入了蒙题(Chance-Level)和人类做答(Human-Level)的两个基准来更好的衡量 VLMs。根据表 1,可以发现 VLM²-Bench 对于人类来说几乎没有什么难度,但绝大多数模型的准确率甚至比不上乱蒙,和人类表现差距甚大。尤其是在描述视频中出现的人(VID)这一任务上,模型很容易把变化的人当作同一个来描述,把第二次出现的人当作一个新出现的人介绍。
同时我们还观察到模型在关联人物线索 PC 上的表现比物体线索 OC 更好,这个可能是因为关于人的图文数据上有提供区分度较大的不同的人名作为人物视觉线索的文本锚点,而在物体有关的数据上训练时往往都是用宽泛的类别这一作为锚点,从而模型更擅长区分不同人。
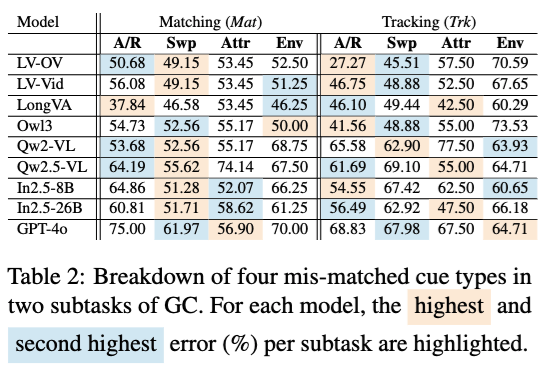
通过在通用线索 GC 这个大类中的进一步的分析,可以看到在匹配线索(Matching)这一子任务上,模型匹配两个由于替换(Swp)导致的不一致的能力较弱;而在跟踪线索(Tracking)这一子任务上,模型匹配两个由于添加或去除(A/R)时很难给出线索的变化顺序。这一发现说明模型在视觉线索关联任务中的短板存在一定的共性 —— 过度依赖于线索的 “连续可见性”,缺乏全局关联这一动态视觉理解的能力。
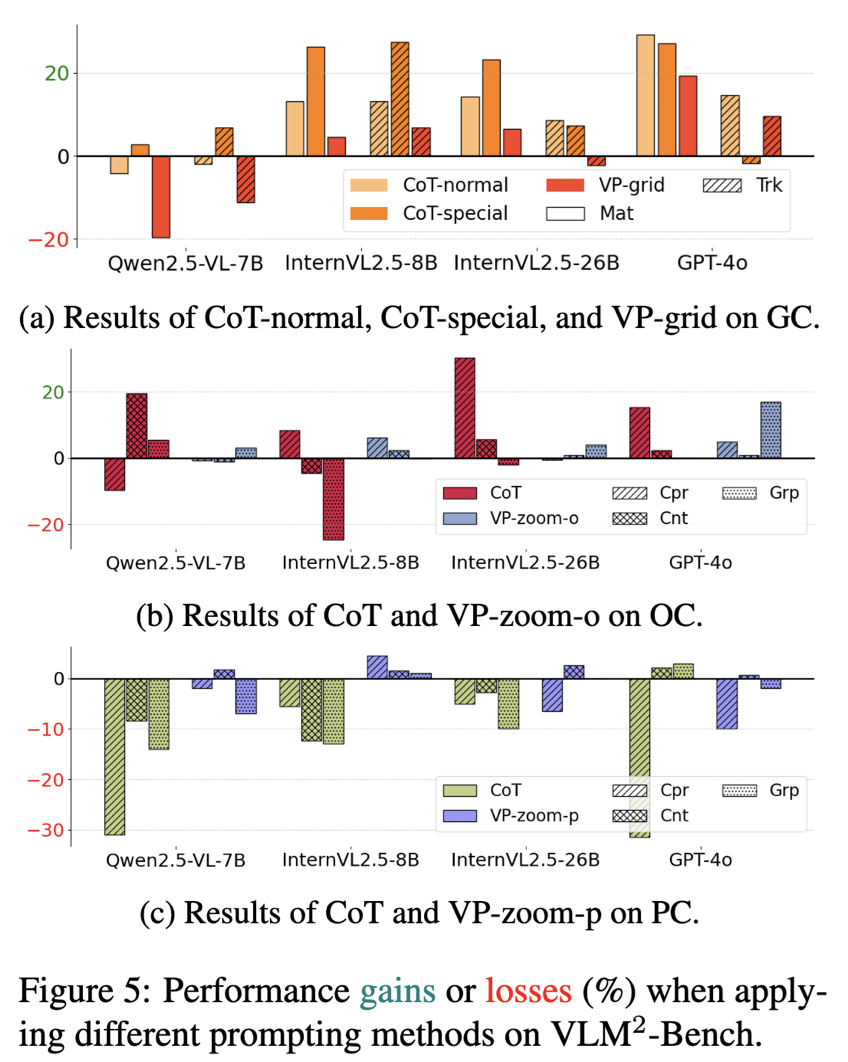
不仅仅局限于简单的评测,本文还探究了以语言为中心(CoT-)和以视觉为中心(VP-)的 prompting 方法能否促进模型在这种视觉关联能力。有以下的几点发现:
-
将语言为中心的推理(如逐步说出解决问题的过程),可以在一定程度上促进关联时的逻辑,但是前提是视觉线索适合用语言进行表达,对于抽象的视觉线索,以语言为中心的推理会因为表达的开放性从而严重影响表现。 -
将视觉为中心的提示(如放大关键的视觉线索),在物体线索 OC 的场景下帮助较大,而在人物线索 PC 上反倒会 “帮倒忙”。 -
以视觉为中心的提示带来的效果和模型的视觉基础能力呈现正相关的关系。只有在模型能够先后理解视觉提示带来的额外的辅助信息以及图中本身的信息时,视觉为中心的提示才能起到较好的效果。
未来方向
-
增强基础视觉能力:提升模型的核心视觉能力不仅能直接提升性能,还能增强适应性。更强的视觉基础可以最大化视觉提示的效果,并减少对先验知识的依赖,使模型在以视觉为核心的任务能够实现独立和可拓展。
-
平衡基于语言的推理在视觉任务中的作用:在视觉任务中引入语言推理需要谨慎调整。未来研究应明确哪些情况下语言推理可以增强视觉理解,哪些情况下会引入不必要的偏差,以确保模型合理地利用语言侧的优势。
-
新的训练范式:当前的训练方法主要关注视觉和语言的关联,但随着模型视觉上下文窗口的扩展,单纯在视觉域内进行推理的能力变得越来越重要。未来应优先发展能够在视觉线索之间进行结构化、组织和推理的模型。
©
(文:机器之心)