
AGI-Eval团队 投稿
量子位 | 公众号 QbitAI
今年,CVPR共有13008份有效投稿并进入评审流程,其中2878篇被录用,最终录用率为22.1%。
录用论文上来看,多模态相关内容仍是关注重点。
![]()
上海交通大学-美团计算与智能联合实验室发布的论文也被录用,论文提出了Q-Eval-100K数据集与Q-Eval-Score评估框架。

论文致力于解决以下问题:
-
现有的文本到视觉评估数据集存在关键评估维度缺乏系统性、无法区分视觉质量和文本一致性,以及规模不足等问题;
-
评估过程复杂、结果模糊,难以满足特定评估需求,限制了基于大模型的评估模型在实际场景中的应用
相关实验也表明数据集和方法在评估结论和泛化性方面都做到的当前业界的领先水准。
在下表中可以看到数据集Q-Eval-100K的实例数量和人工标注数量远超其他数据集,可以说Q-Eval-100K是当前最大的AIGC评估数据集。

同时跨数据集验证显示,在Q-Eval-100K上训练的模型在GenAI-Bench数据集上表现出色,远超当前先进方法,充分证明了Q-Eval-100K数据集的泛化价值。
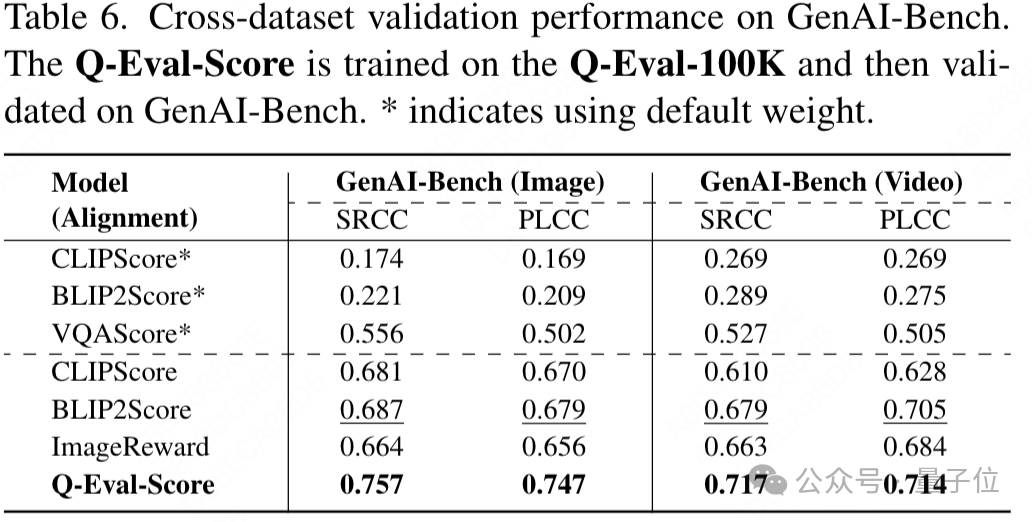
数据集Q-Eval-100K开启了文本到视觉内容评估的新时代,同时Q-Eval-Score提供一个开源的较为准确客观的AIGC打分框架,可用于对AIGC图片视频生成类模型的评估。
Q-Eval-100K数据集共计包含了100K的AIGC生成数据(其中包含60k的AIGC图片以及40k的AIGC视频)。
接下来,将对Q-Eval-100K数据集与Q-Eval-Score评估框架进行详细介绍。
数据集构建
在数据集构建上,团队确保遵循三个原则:
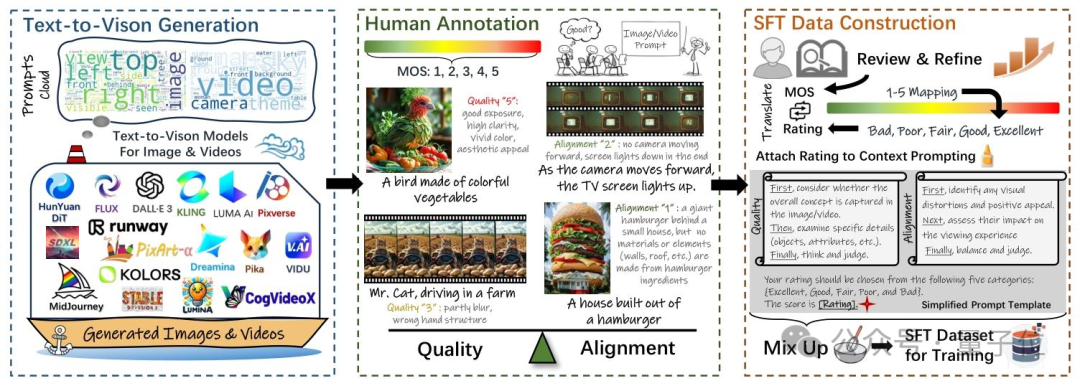
1)保证数据多样性。为了收集到接近真实场景下多样性的数据集,团队从三个大的维度出发构建了对应的prompt集,这三个大的维度可以被划分为实体生成(people,objects,animals,etc.),实体属性生成(clothing,color,material,etc.),交叉能力项(backrgound,spatialrelationship,etc.),通过对于不同维度数据的比例控制,确保了prompt数据的多样性。同时,团队还使用了当前SOTA开源或者API的AIGC模型进行数据生成,从而确保了生成数据的高质量。这些AIGC模型包括FLUX,Lumina-T2X,PixArt,StableDiffusion 3,CogVideoX,Runway GEN-3,Kling等。
2)高质量的数据标注。团队招募了200多名经过培训的人员进行人工打分标注,从这些人员手中收集了超过960k条相关数据的打分信息。经过人工严格的筛选和过滤后,最终得到了这100k AIGC数据以及其对应的一致性/质量标注数据。通过这样的方式,可以确保标注数据与人类偏好的高度一致性,从而提升了Q-Eval-Score评估框架的一致性与泛化能力。
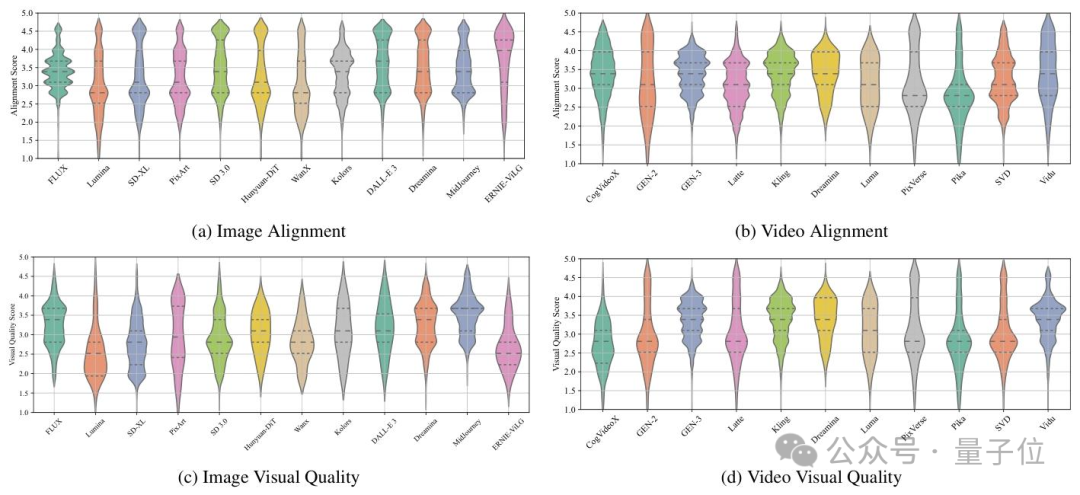
3)视觉质量和文本一致性解耦标注。团队观察到当前对于AIGC模型质量的研判主要聚焦于视觉质量和文本一致性两个方面,因此,在数据集构建的过程当中将两个维度拆分开标注,以确保Q-Eval-Score可以同时对这两个维度进行评估。如下图所示,在统计了多个AIGC模型的视觉质量和文本一致性mos分后,团队发现两个维度上模型的表现存在一定的差异性,因此也说明了将两个维度解耦的必要性。
以上数据集已在AGI-Eval社区评测集专区上线。

统一评估框架
在Q-Eval-100k的基础上,团队训练得到了Q-Eval-Score评估框架,该框架将数据集转换为监督微调(SFT)数据集,以特定上下文prompt格式训练大语言模型(LMM),使其能够独立评估视觉质量和文本一致性。
模型训练
首先,团队构建一个上下文prompt数据集用于大模型的SFT过程,模版如下:

再将人工标注打分按照1-5分分别映射到5个档位{Bad,Poor,Fair,Good,Excellent}上,以确保数据可用于大模型SFT,人工标注打分映射的过程如下所示。

通过将五档得分的logits概率与权重加权得到最终得分,权重1-0分别表示从Excellent到Bad的得分映射。

在模型上,团队选择了当前在图像视频理解上性能较为优异的Qwen2-VL-7B-Instruct模型进行SFT微调,在微调时同时启用CE Loss和MSELoss,用于监督模型打分能力的提升。
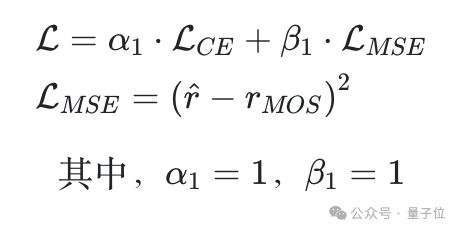
长prompt对齐问题

在文本一致性上,团队发现在处理长prompt(超过25个词长)的场景时,常会低估对应的分数,这通常是由于训练集当中出现的较长提示词占比较少导致。
因此,针对长提示词对齐评估难题,团队创新性地提出“Vague-to-Specific”策略,将长提示词拆分为模糊提示词和多个具体提示词分别评估,再综合计算最终得分。
对于模糊提示词,团队按照常规方式计算对齐度得分。
然而,对于特定提示词来说这个策略并不合适,因为每个特定提示词只涉及视觉内容的一部分。
受VQAScore方法的启发,团队将问题修改为更温和的形式,例如“Doestheimage/videoshow[prompt]?”,以此来评估每个特定提示词的对齐度。
最后,团队使用加权方法结合模糊提示词和特定提示词的结果,计算最终的对齐分数:
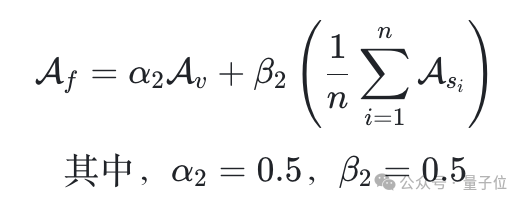
实验结论
在视觉质量评估方面,Q-Eval-Score在图像和视频的测试中均表现优异,其预测得分与人工打分的斯皮尔曼等级相关系数(SRCC)和皮尔逊线性相关系数(PLCC)超越了当前所有的SOTA模型。
在文本一致性上,Q-Eval-Score同样优势显著,在图像和视频的测试中,其Instance-level的SRCC分别领先其他的sota模型6%和12%。

消融实验表明,研究中提出的各项策略和损失函数对模型性能提升贡献显著。
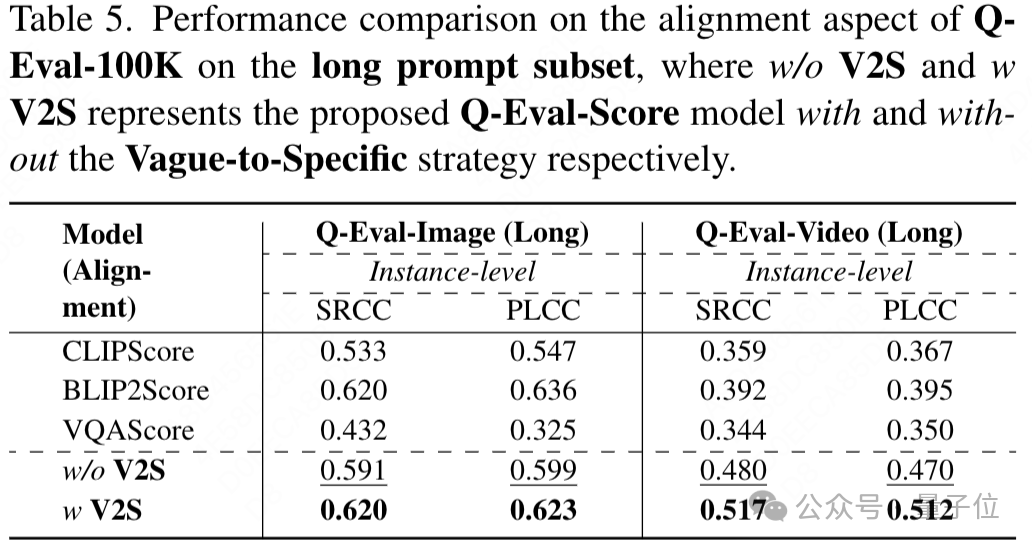
在长提示词子集测试中,“Vague-to-Specific”策略有效提高了评估性能;
Q-Eval-100K和Q-Eval-Score的出现意义重大。它们为文本到视觉模型的评估提供了更可靠、全面的方案,有助于推动生成式模型的进一步发展和实际应用。未来,这一研究成果有望为相关领域的发展奠定坚实基础,助力文本到视觉技术迈向新高度。
AGI-Eval评测社区也一直致力于共创如“Q-Eval-100k数据集”这样优秀的数据集,在模型评测领域深耕,旨在打造公正、可信、科学、全面的评测生态以“评测助力,让AI成为人类更好的伙伴”为使命。
在评测集社区板块有行业公开学术评测集,支持用户下载使用;官方自建评测集,涉及多领域的模型评测;以及用户自建评测集,平台支持用户上传个人评测集,共建开源社区。
论文链接:
https://arxiv.org/abs/2503.02357
AGI-Eval评测集专区: https://agi-eval.cn/evaluation/Q-Eval-100K?id=55
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
(文:量子位)