


作为一个热爱反复折腾个人知识体系的笔记人,
AI 知识库像是个不可能三角,
想要完全存在本地,本地运行的模型会占电脑资源,想要完全存在盘,会因为网速等额外原因导致搜索不出结果,
类似 Notion 等文档工具加上 AI 之后,我又会希望我写的、收集整理好的内容能够跟某些领域的资料相互隔离开。我可以自由限定范围,一个文件、多个文件、一个目录就都可以是知识库。
随着 AI 搜索们自带知识库之后,知识库现在已经进化成了可分享资源,这时候我就希望可以带上视频、图片、音频等各种文件的支持,真正意义上做到分享一切。
上面提到的需求点,今天首个大模型驱动的多模态知识库–纳米AI知识库都满足了,同样支持上了我们的老朋友 DeepSeek R1。
既然是首个支持多模态(文件、图片、音视频、网页)的知识库,那我们的测试一定是要升 Level 的。这次我花了一周末的时候收集各种刁钻资料,是平时都不愿意碰,一键收藏然后吃灰的那种,按照资料的形式分为:
长视频、长音频、混合格式文档、各类网页链接
覆盖场景是针对日常看超长视频、超长音频的信息总结和提问;同一信息的不同格式文档(PDF、PPT、Word、TXT、Markdown)合并;以及从日常网页浏览记录里提取并归类有用信息。
都是我需要高频使用 AI 场景,Here we go!
一、长视频
我们先来看看如何使用,
访问:“bot.n.cn”,目前支持Windows、Mac和移动版。
毕竟每次都要熬夜看 OpenAI 发布会,针对一个视频就要反复提问,之前是将视频里的音频做文字识别,再用大模型总结汇总,
现在可以直接丢给多模态知识库,直接开问!
Q1:OpenAI deep research更新有什么新鲜之处?

R1在视频里可以捕抓到多个发言人表达的观点,从视频描述和字幕两部分互相印证出信息,还可以读取里面的报告。最6的是,总结出来了在发布会里模型用了11分钟完成29个信息源的深度分析。简直是自媒体人的福音。
Q2: deep research怎么使用?

为了防止在字幕里面的信息作弊,我直接问问看deep research怎么用,还真的被 R1 通过多模态知识库在视频画面里识别出来了,而且其实不存在联网搜索作弊的可能性,毕竟现在 deep research 已经开放给普通用户使用,这里面引用的信息还是 pro 的。
当然,贴心的 R1 还给我推荐了几道 deep research 专属的问题,以及推荐理由。
二、长音频
说起长音频的第一时间想到就是上周印象深刻的Manus没有秘密的播客,时长73分51秒。

因为平时听都是断断续续的,所以很需要听完之后来一个快速总结或者通过提问来重温一下,之前是用通义听悟来完成这个工作,现在也是直接丢到纳米多模态知识库,
Q3: ‘AI搜索的问题有哪些’?

这是一个迷惑性非常非常高的问题,因为 AI 搜索在模型本身也有答案,如果没有成功完成阅读完 MP3 里的内容,很容易就理所当然了。
从答案里面可以看到,播客里面提到了AI搜索的技术路径、行业竞争和产品形态上的差异。这也是搭建专属知识库的优点,你可以将优秀的、以及浓缩好的信息点一下子提取出来。
Q4: ‘为什么说manus没有秘密?’

这波是回收标题,直接用音频的标题作为提问,实际上是想考验一下知识库对音频的切割方式,是不是可以完整地将信息传送给 R1。从答案里面也是可以看到,Manus 之所以没有秘密,是因为核心架构透明化和复用成熟技术栈。
三、混合格式文档
既然上面的播客用了70分钟来讲解70页PPT,
那PPT本身也可以作为信息源,
文本类已经比较成熟的知识库素材了,所以我做了两种形式的对比,
-
单个文件多页总结 -
多个文件单点总结
Q5: “GAIA是什么?”

了解 Manus 的大家应该对 GAIA 这个测试集不陌生,
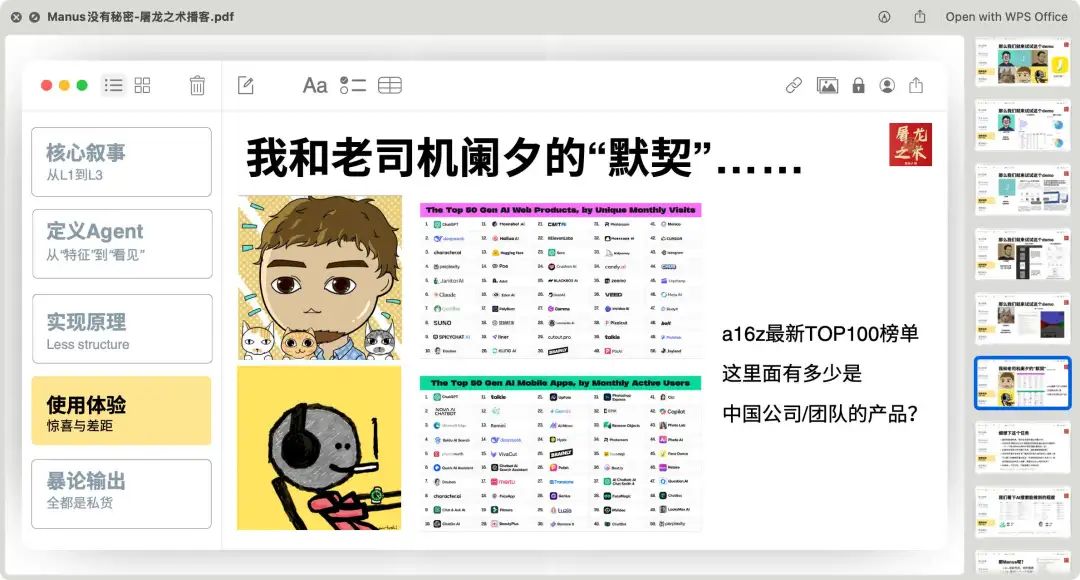
R1 能从 PPT 里面看到用户让 Manus 处理 a16z 的 Top100 榜单分析的全过程,并将这个归类到 GAIA 任务例子,比起直接看图更加容易理解,也是充分利用了模型可以横跨多页 PPT 总结信息的优势了。
再来一个多文档测试,我把 pdf、txt、markdown、word 都放在了一起。问出这一句,普通联网搜索模式下,很多模型都会懵的问题:
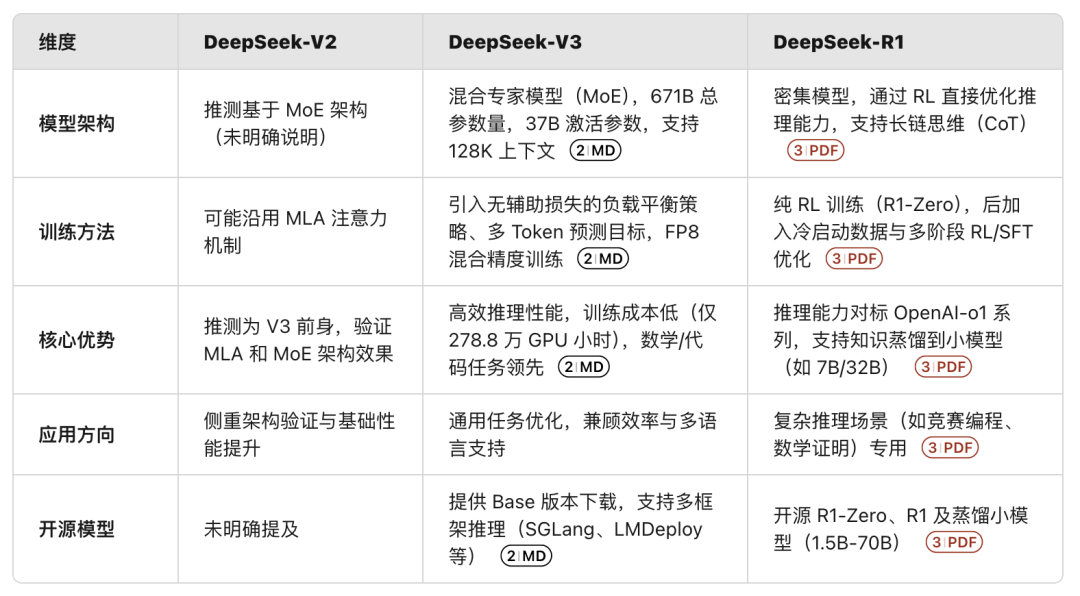
Q6: “deepseek R1、V3、V2,有什么相同点和差异点?”
R1成功检索到了清华大学出的 DeepSeek R1 的 pdf、deepseek v3 的 github 项目 readme 文件以及 DeepSeek V2 的论文,输出了对比表格,V3、R1的信息基本都没有,V2 的信息稍微有点欠缺。
更6的是,
如果这时候你点开每一个文件,就会发现纳米多模态知识库给每个文件单独加了简介、重点、翻译、分析、讨论模块,做到了一个文件也是单独一个知识库的操作。
四、各类网页链接
我这里用了OneTab插件来模拟一下日常网页浏览的时候,搜索某个新闻的时候,一段时间就会打开几十个网页,这时候为了避免卡死,就会一键将它们收藏起来。

方便是方便,但同时还会带来两个新的问题:
信息分类和信息去重汇总
最近 Manus 带起了 MCP(Model Context Protocol),又或者说 Claude 通过 MCP 一口气完成3D建模破圈了,
所以借这个机会,我搜索了一大堆关于 Manus 的网页,现在就来问问结果,
Q7: “MCP到底是什么?有什么用?”

一口气总结了8个网页后,R1 给出的答案是这个,
MCP(Model Context Protocol,模型上下文协议)是由 Anthropic 提出的开放标准协议,旨在为大模型与外部数据源、工具之间建立安全、统一的双向通信桥梁。其核心价值是解决 AI 应用中的数据孤岛问题,同时提升安全性和开发效率
还可以进一步得到 MCP 目前有意思的案例,

一句话完成3D建模(BlenderMCP)、 自动化编程(Cursor IDE + GitHub/Slack)、科研助手(arXiv论文检索)和跨平台工具链(Composio集成服务),
我个人觉得将多个网页收录到知识库最大的好处就是,能清晰构建一个集合包含所有我想知道的信息,也能得知我对一个事物了解的程度有多深,通过提问来回顾我曾经看过的内容,或者来重新理解我看过但没 get 到的知识。
写在最后
长上下文和RAG并不是对立关系,而是一对互补CP。
实际上,多模态RAG就相当于给AI额外装了眼睛耳朵,
把你的日常见闻、灵感碎片统统收进知识库。
想象一下,那些年熬夜攒的工作经验、深夜读书的顿悟,
现在都能打包直接扔进知识库里,随时揉碎了造出新东西,
这才是真的效率翻倍。
到这里,其实想说我们都在见证一次双向进化:
AI在倾听我们,
我们也在教它如何更懂自己。
这个过程真的太酷了。
@ 作者 / 卡尔 & 阿汤 @ 动手学AI知识库 / learnprompt.pro
(文:卡尔的AI沃茨)