


那么 Deep(Re)Search 具体是什么呢?在正式介绍它之前,我们先来思考两个问题。

为什么我们需要 DeepSearch,它和之前的 AI Search 有什么区别?
24 年主流的 AI Search 一般只有一次联网搜索,将搜到的内容返回给大模型后快速生成答案。但如今越来越多的开始用 AI 来做 SEO/GEO,导致互联网上充斥了大量 AI 生成的同质化内容,进而一定程度上污染了互联网信息源,会直接影响 AI Search 的结果。
试想一下,当你在繁杂的互联网上搜寻某个问题的答案的时候,也需要花费一些精力去查看不同渠道和网页,思考回复是否正确,最终才可能得到一个满意的答案。DeepSearch 也是如此设计的,为了更好的去伪存真,DeepSearch 旨在能让模型能一边搜索一边思考,不断推理反思,直到找到最好的答案。
那 DeepSearch 和 DeepResearch 又有什么区别?
DeepResearch 是在 DeepSearch 的基础上,通过引入结构化框架来实现长篇研究报告(或其他类型文档)的自动化生成。
以研究报告的生成为例,其工作流程首先从创建报告目录开始,随后系统性地将 DeepSearch 应用于报告的各个组成部分:从引言部分、相关工作综述、研究方法论到最终结论,每个部分都经过 DeepSeach 来内容生成。
最后,通过 LLM 对各个部分进行整合与优化,确保最终生成的研究报告具有高度的内容连贯性和逻辑完整性。

图源 Jina AI
DeepResearch 的形式很多,各家的实现形式和最终效果也会相差许多。比如直接用 LLM + 搜索插件,理论上也可以是一个 DeepResearch(在模型强大的未来,或许这最朴素的形式是最常见的形式),Manus 也可以是一个DeepResearch(实际上 Manus 非常适合做这个事)。以下特工们抛砖引玉一下,告诉大家可以怎么样实现一个效果还行的 DeepResearch。

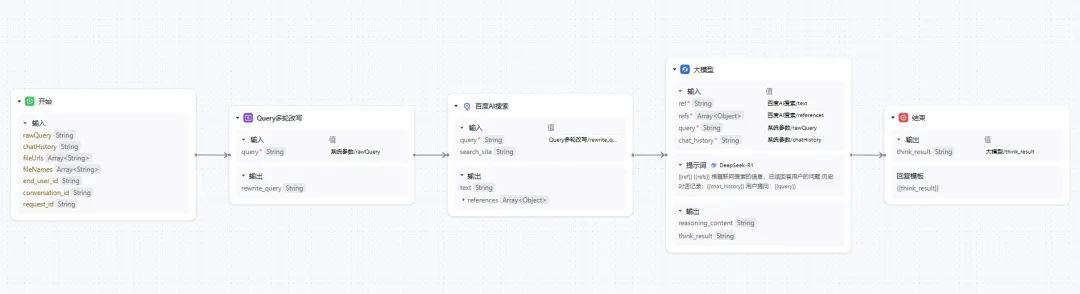
我们基于 DeepSeek-R1 作为核心模型,整体具体流程图如下。
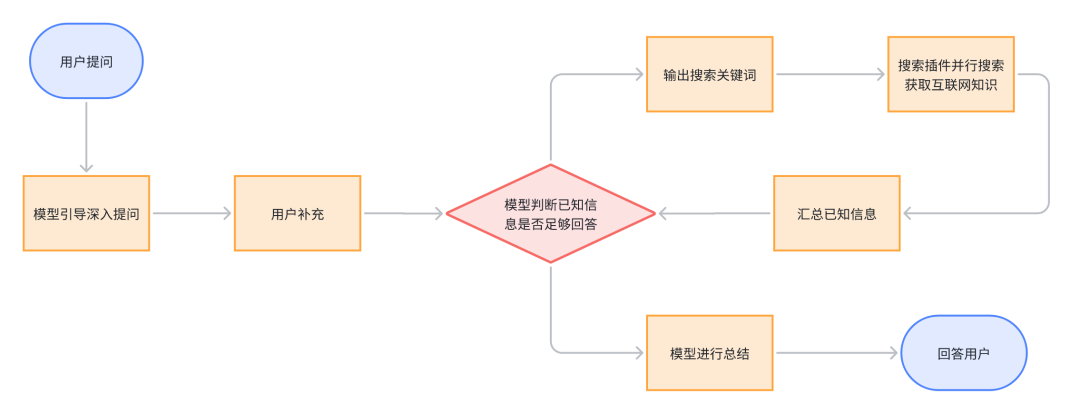
我们在搜索关键词生成和当前状态推理,以及总结部分都选择相同的 DeepSeek R1 模型,是因为我们认为模型很多时候的幻觉问题来源于预训练时候缺少的知识(如大模型并不知道最近的 Manus 产品,而会认为是 VR 产品)或与当下时空不匹配的知识(如一些产品曾经和现在的价格差异)。不同的大模型其预训练的知识不同,如果选择不同的模型,可能会导致对当前状态的误判,A 模型认为信息充足,因为其预训练知识加上搜索结果已完备,而 B 模型在总结时并没有相关信息,从而容易产生较大幻觉。
由于之前在百度智能云千帆 AppBuilder 平台上体验 DeepSeek 比较丝滑流畅,因此我们接下来将基于该平台,通过搭建工作流进行具体复刻,在整个工作流搭建过程中来切身感受 DeepResearch 的运行流程。
‼️包含提示词和代码节点代码的详细教程,可以参阅下面这个文档:
https://qianfan.cloud.baidu.com/qianfandev/topic/685761
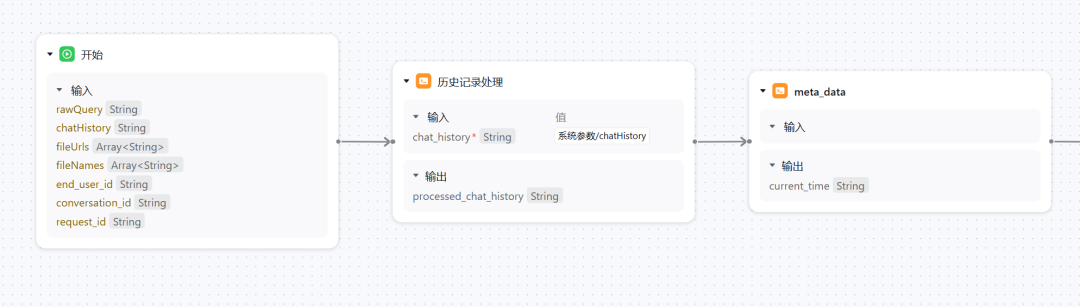
「开始」节点用于接收用户的输入,作为一个对话型工作流的 Bot,此处接收的就是用户的提问以及历史对话记录。
「历史记录处理」节点用于处理历史记录,从复杂的历史记录中,删掉不必要的部分,减少干扰,让模型对问题的思考能更加集中。这里具体是因为后续我们在输出时,为了方便用户查看具体进程和搜索结果,将搜索的内容全都输出。
「meta_data」节点的功能很简单,为后续 LLM 提供基础的环境信息(这里为当前时间)。但该节点对最终效果的提升是非常明显的,如果缺少,则 LLM 非常容易在与当前时空不匹配的环境下进行推理。
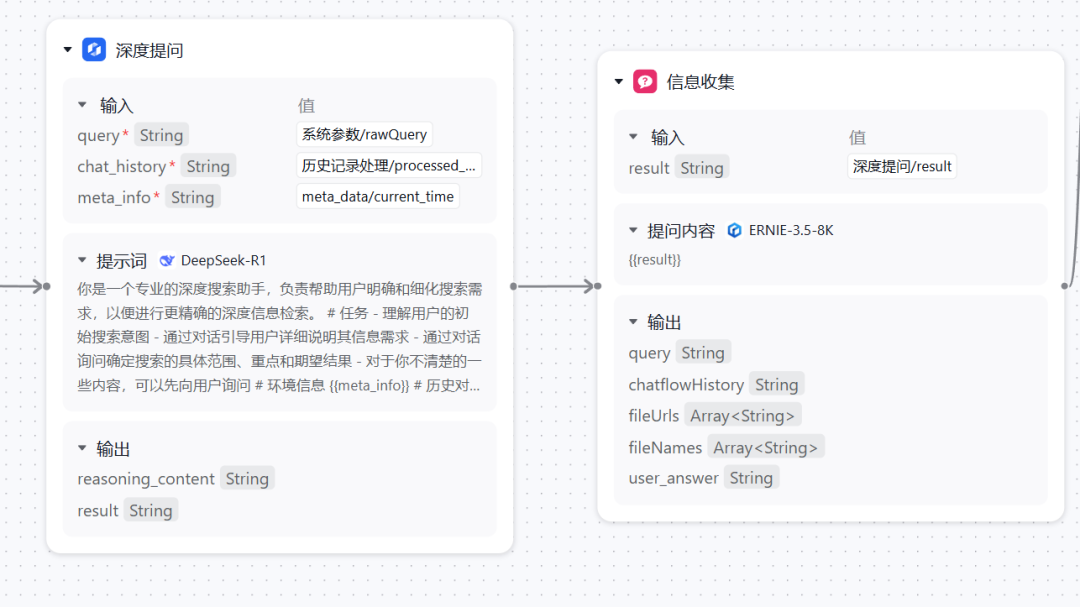
「深度提问」和「信息收集」节点用于向用户进行更深入的提问。因为在绝大部分情况下,想要模型有更好的结果需要详细的信息和用户指引,但让用户在第一次输入时提供所有信息并不自然。这个节点可以让模型和用户进行第一次初步交互,确定需要研究和搜索的具体方向,以及对模型的幻觉进行极其重要的第一次纠正。
接下来是一个循环体,其内部可能初看比较复杂,但实际功能非常直接。让大模型循环查看当前搜索到的资料是否足够回答用户问题,如果不够,继续进行搜索。
因为 DeepSeek R1 的 Action 能力暂时还不太够,所以这里配合搜索插件,R1 模型判断信息是否充足,如果不够则输出需要搜索的关键词,而输出的关键词交给搜索组件进行搜索和总结。

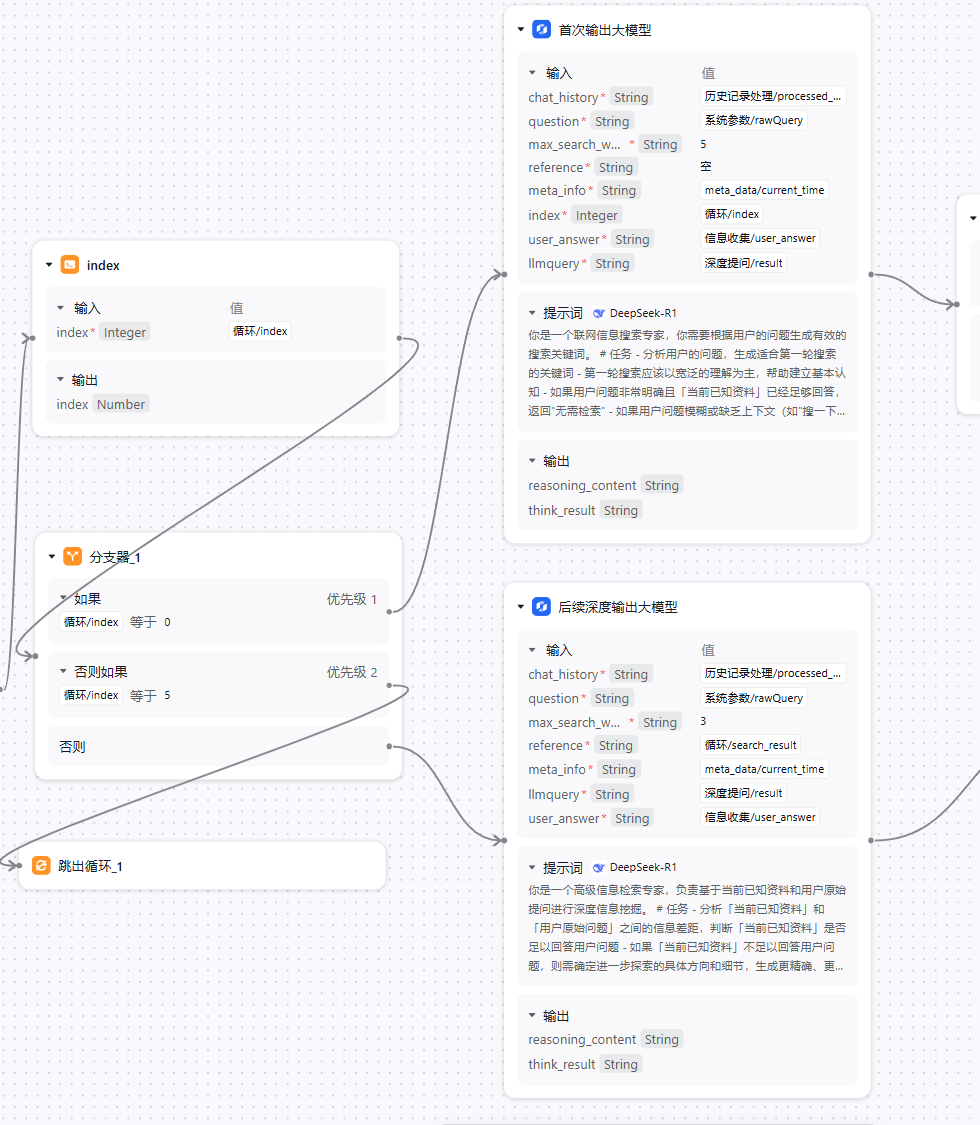
「index」节点用于计算当前实际循环轮次(因为默认的 index 是从 0 计数,需要 +1,从而方便最后输出给用户)
「分支器」节点主要功能是避免陷入死循环和超出模型上下文,设定了搜索次数上限。而这里的首次搜索和后续搜索,两个分支实际上是几乎相同的内容,有能力的小伙伴可以将二者优雅的聚合在一个分支内。
「首次输出大模型」和「深度输出大模型」节点的功能都是判断当前已知信息是否可以回答用户提问,如果缺少,则输出需要搜索的关键词,而如果已经足够,则输出无需搜索,跳出循环,进入总结环节。
不过这两个节点的具体提示词还是有些许区别,对于问题处理来说,人类的搜索过程往往是一开始不清楚具体信息,从而进行比较宽泛的搜索,如“Manus 是什么”,接着才是深度的具体检索“Manus ai 产品的实现细节”。因此首次搜索的大模型在提示词方面会告知需要一定的定义搜索,而后续深度搜索大模型在提示词方面则会告知需要使用一定的搜索策略(如识别信息缺口、多维度探索、多语种搜索等)。
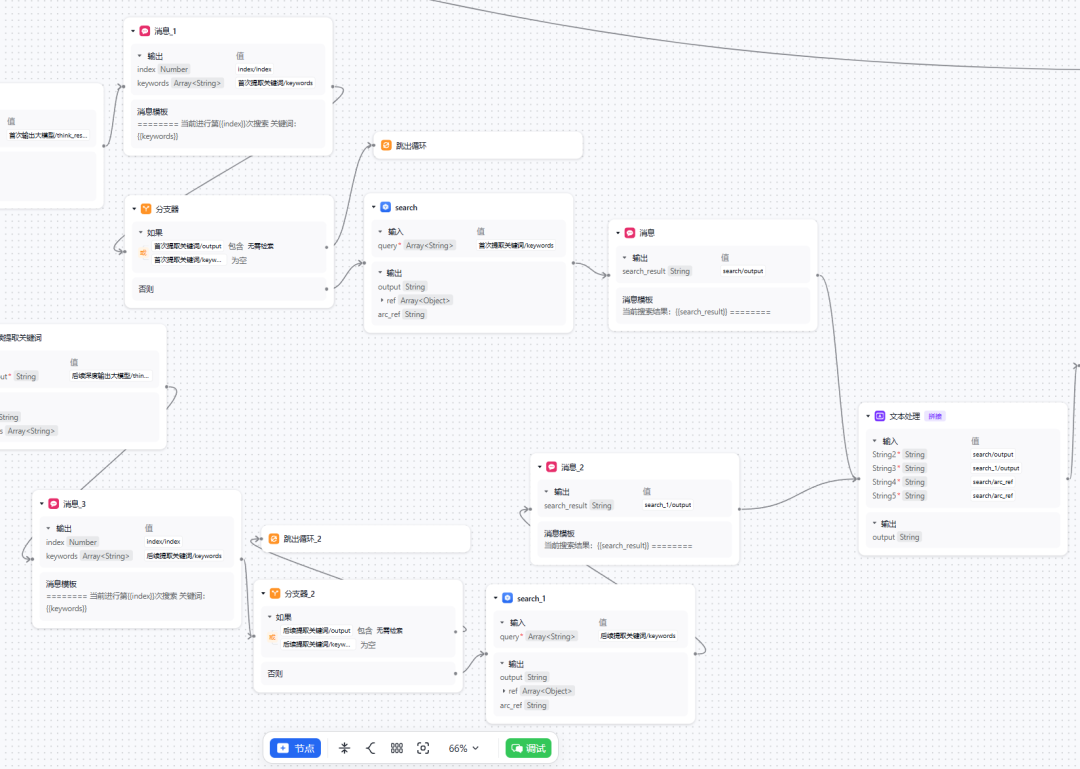
「消息」节点主要用于输出搜索过程(当前检索的关键词和具体搜到的内容)
「search」组件用于接收模型输出的搜索关键词,然后进行并行检索,其具体内部实现如下。
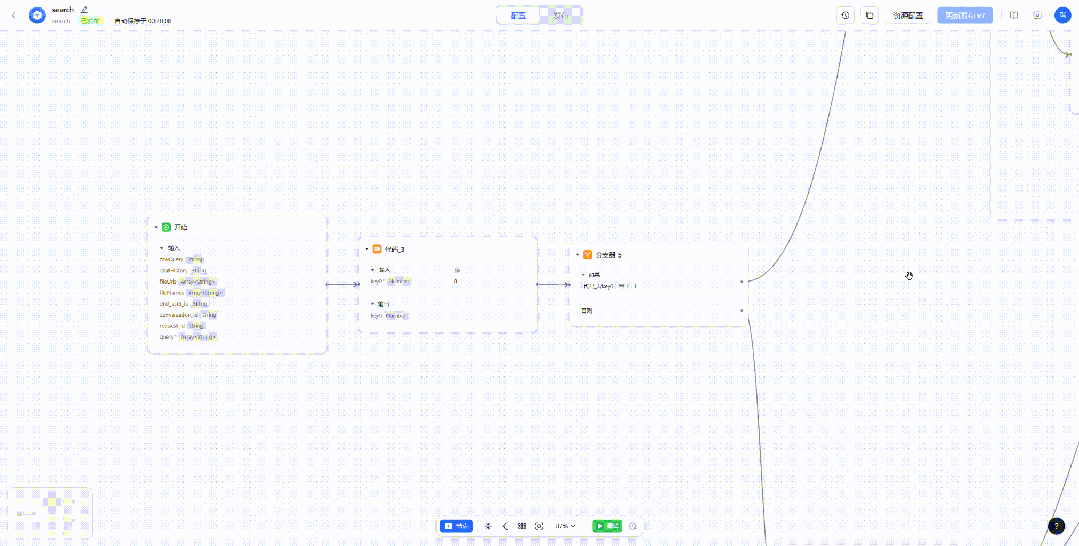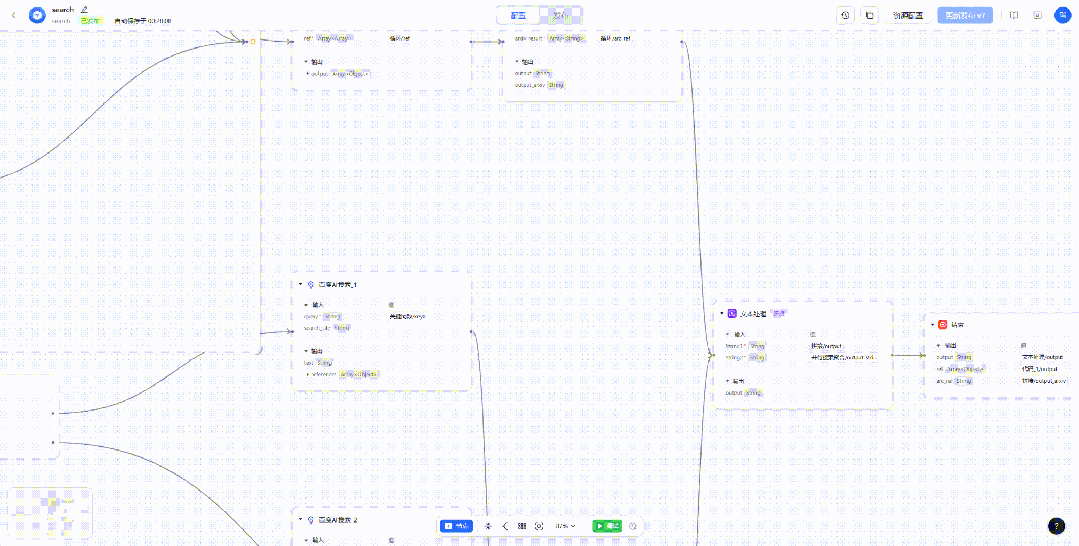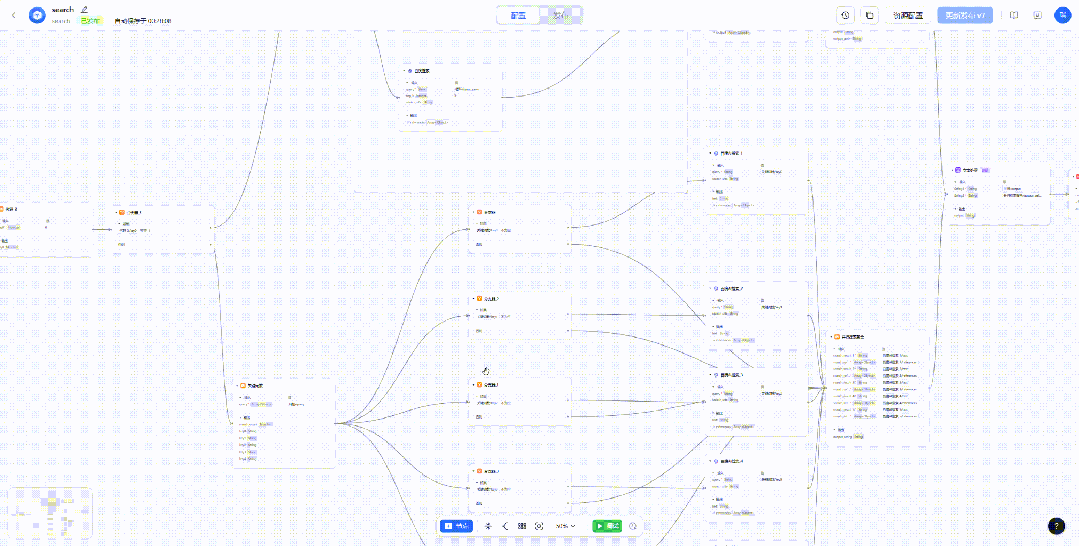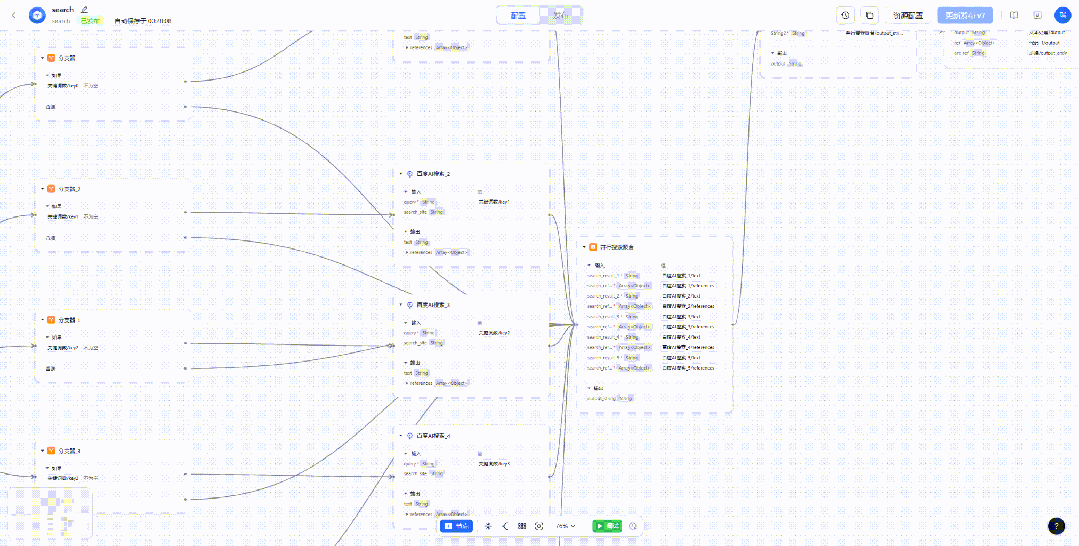
这里有两个分支,上面为循环搜索,也是最开始做的一个版本,底下为并行搜索,也是实际最终使用的版本。
其次,这里的百度 AI 搜索插件,由于并不需要进行复杂的推理,因此使用的是文心 3.5 模型,不过仍然需要一定时间,如果追求搜索时间的小伙伴,可以选择其他搜索插件或者自行接入比如博查 AI 搜索插件。
最后在结束循环搜索后,即可结合搜索的内容以及用户提问,进行一个总结回答。
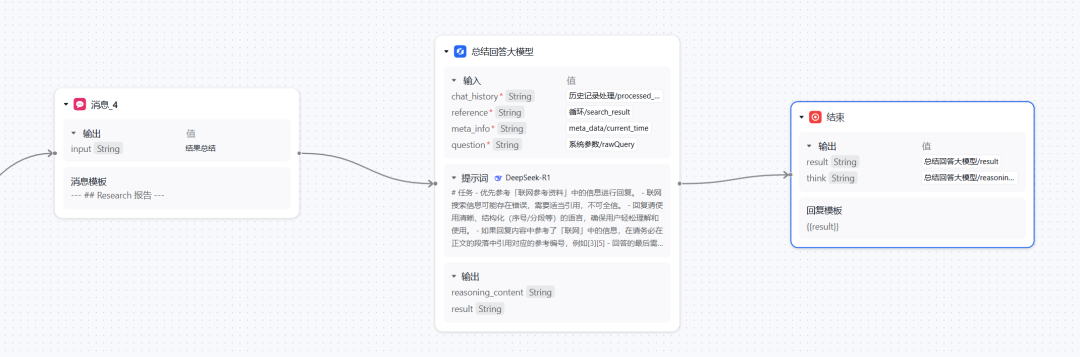
到这就完成了基本的 DeepResearch 实现过程。

最终搭建好的 Demo 链接如下:
https://console.bce.baidu.com/ai_apaas/examplePage/ed6b1a31-6e52-48bc-ac86-95b887c2c574

移动端可以扫描二维码通过小程序体验(退出小程序不影响生成过程~)
我们以“生成最新一个月 AI 资讯报告”为例,实际测试效果如下。
以下是每次每次搜索+思考+总结的过程。
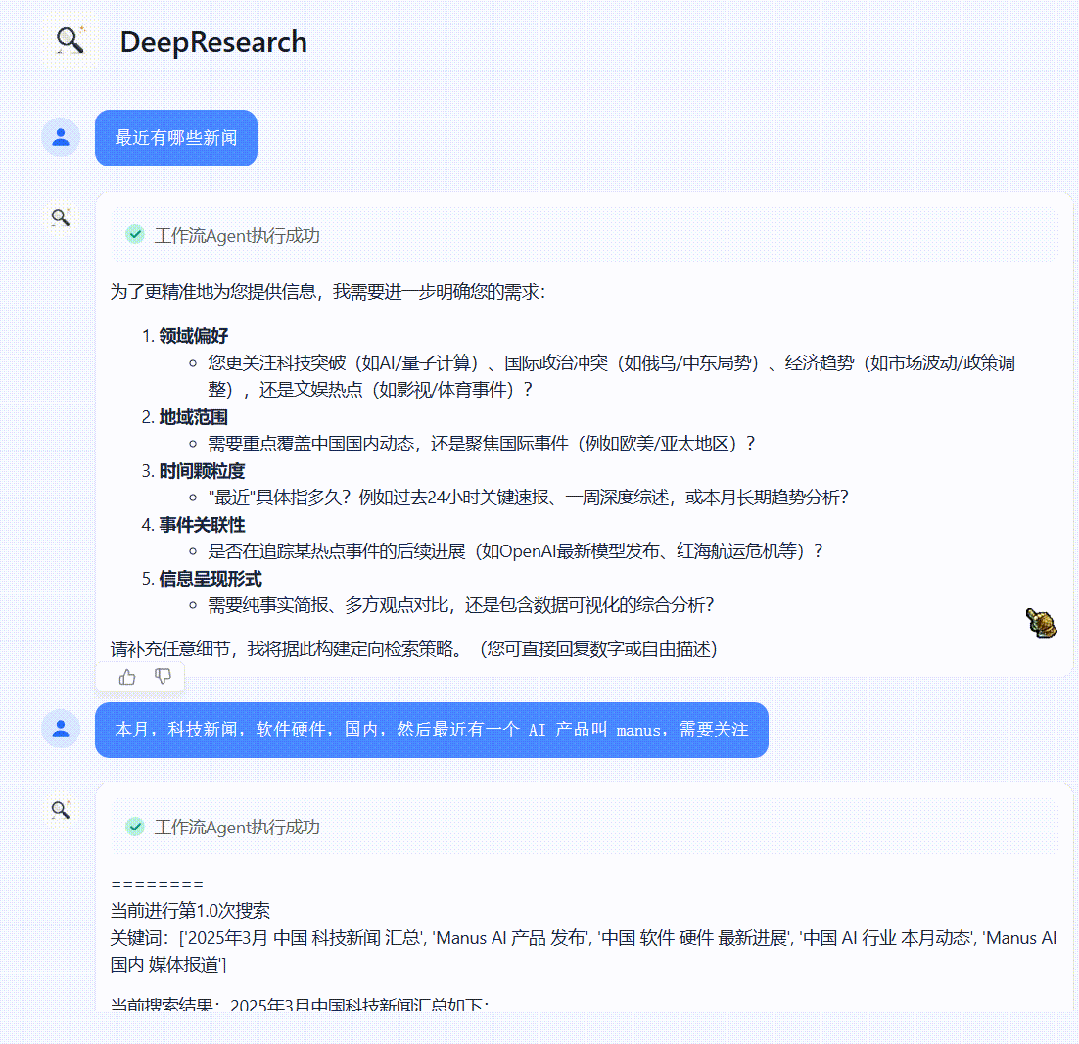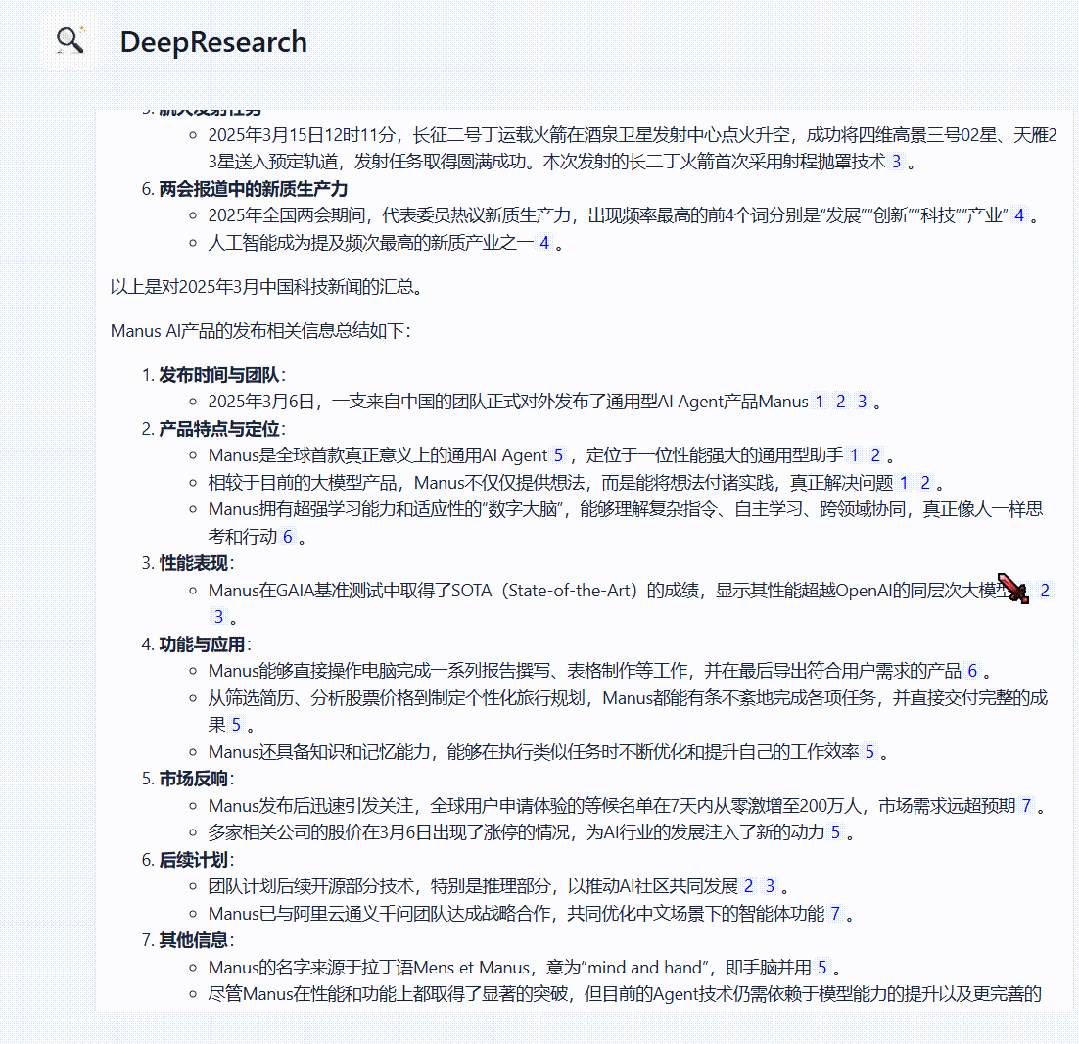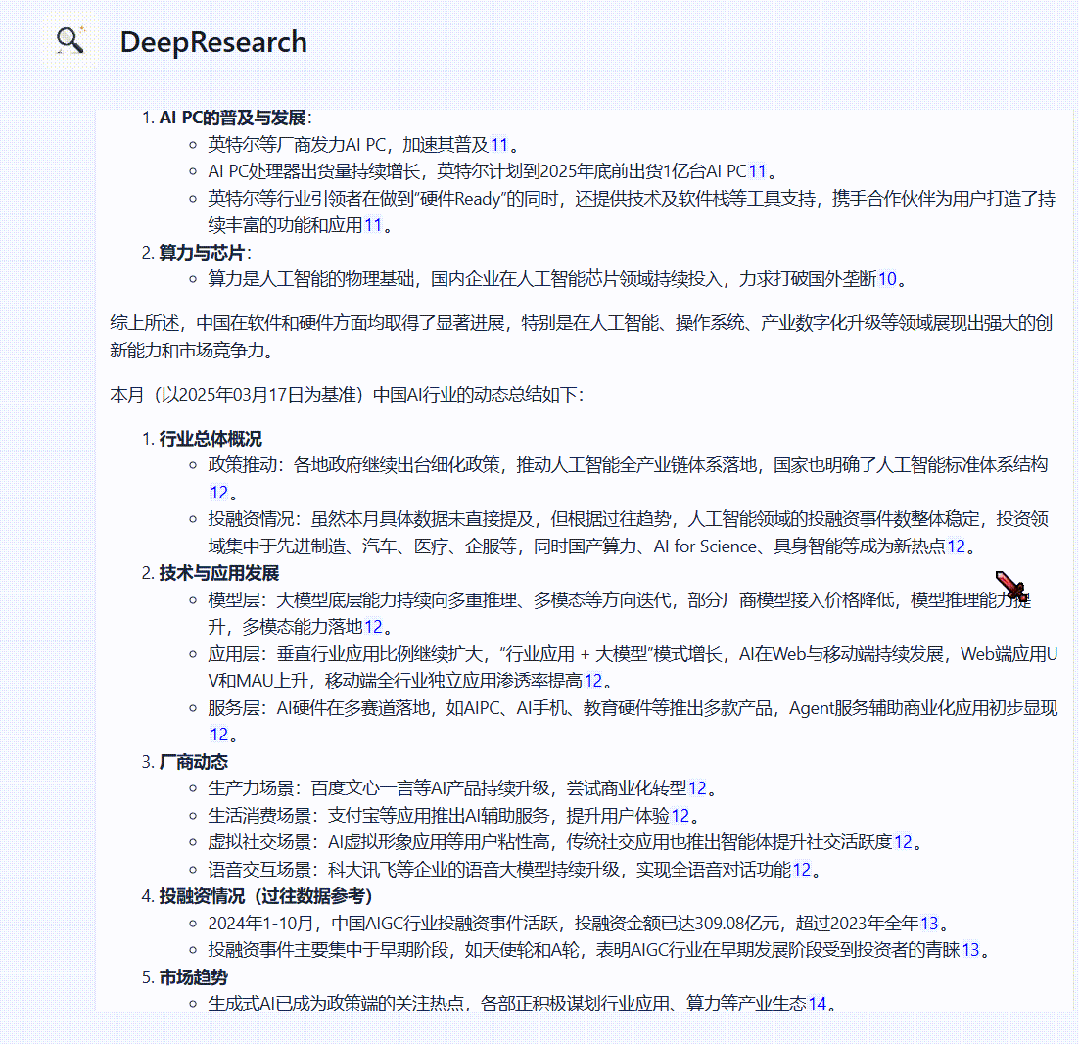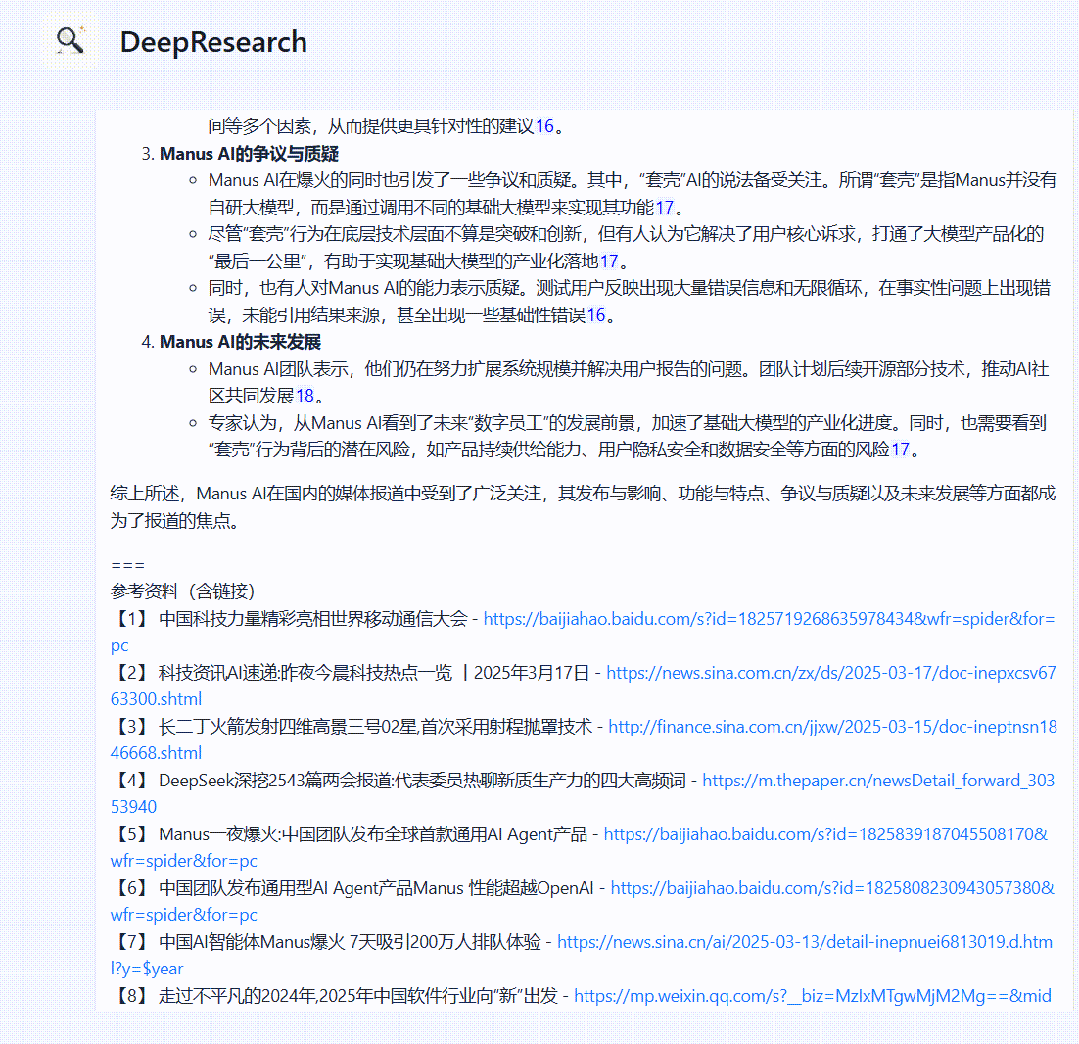
以下为最终报告内容展示。

可以看到相比于传统 AI Search 的实现方式,DeepResearch 得到的结果会更加详细、多维。
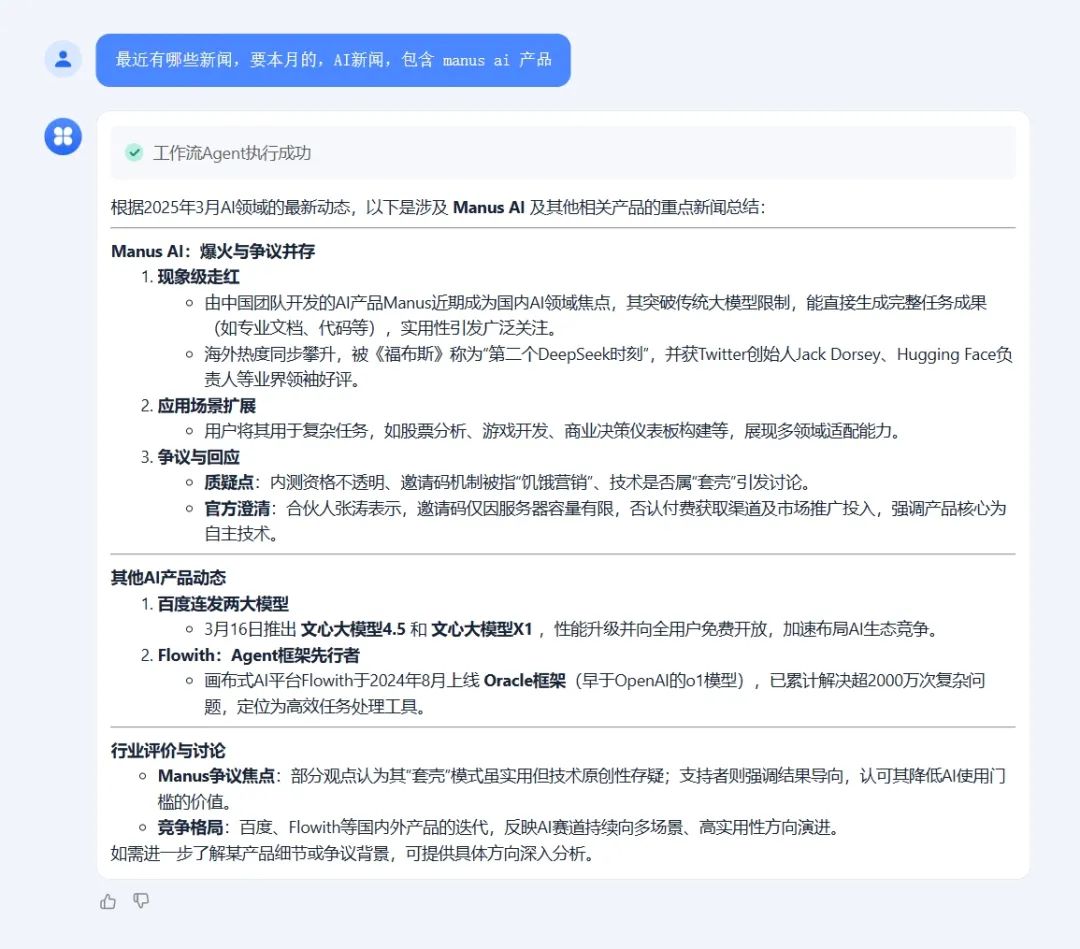
不过,如果想要效果更加出色的 DeepResearch,提升速度和深度等,可以考虑优化具体提示词,切换搜索插件,切换其他模型等(但基于我们前面的原理,我们尽可能要保持搜索和总结模型的一致性,不过因为 R1 是基于 V3 RL 训练而来,其预训练知识存储上差不太多,因此为了速度可以考虑将关键词生成部分切换为 V3)。
千帆 AppBuilder 目前已经接入文心 4.5,开发者们也可以尝试来千帆用最新的模型,来搭建多模态原生应用。


(文:特工宇宙)