


CLIP、DINO、SAM 基座的重磅问世,推动了各个领域的任务大一统,也促进了多模态大模型的蓬勃发展。
然而,这些经过图像级监督或弱语义训练的基座,并不是处理细粒度密集预测任务的最佳选择,尤其在理解包含密集文字的文档图像上。
为解决这一限制,上交联合美团实现了图文对齐粒度的新突破,其具备三大核心优势:
-
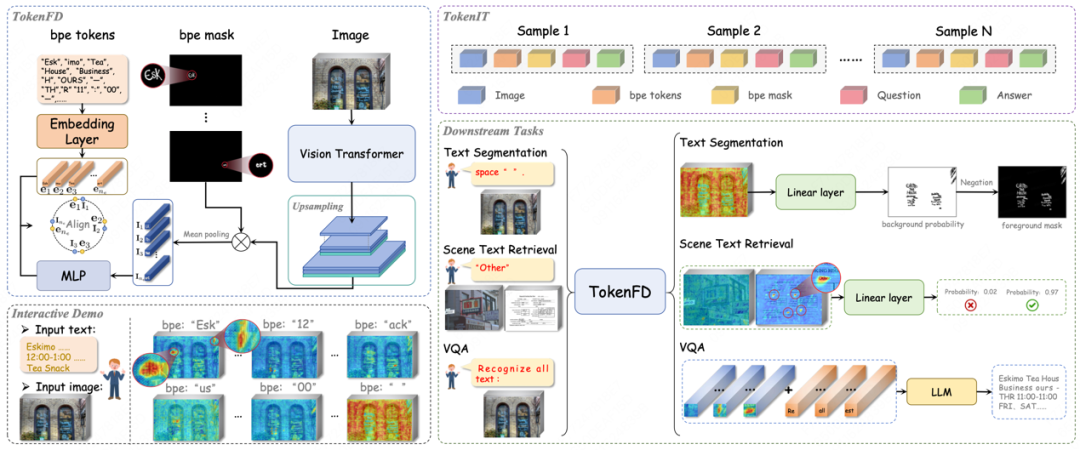
构建业内首个 token 级图文数据集 TokenIT:该数据集包含 2000 万条公开图像以及 18 亿高质量的 Token-Mask 对。图像中的每个 BPE 子词均对应一个像素级掩码。数据体量是 CLIP 的 5 倍,且比 SAM 多出 7 亿数据对。
-
构建图文领域首个细粒度大一统基座 TokenFD:仅需通过简单的一层语言编码,依托亿级的 BPE-Mask 对打造出细粒度基座 TokenFD。真正实现了图像 Token 与语言 Token 在同一特征空间中的共享,从而支持 Token 级的图文交互和各种下游任务。
-
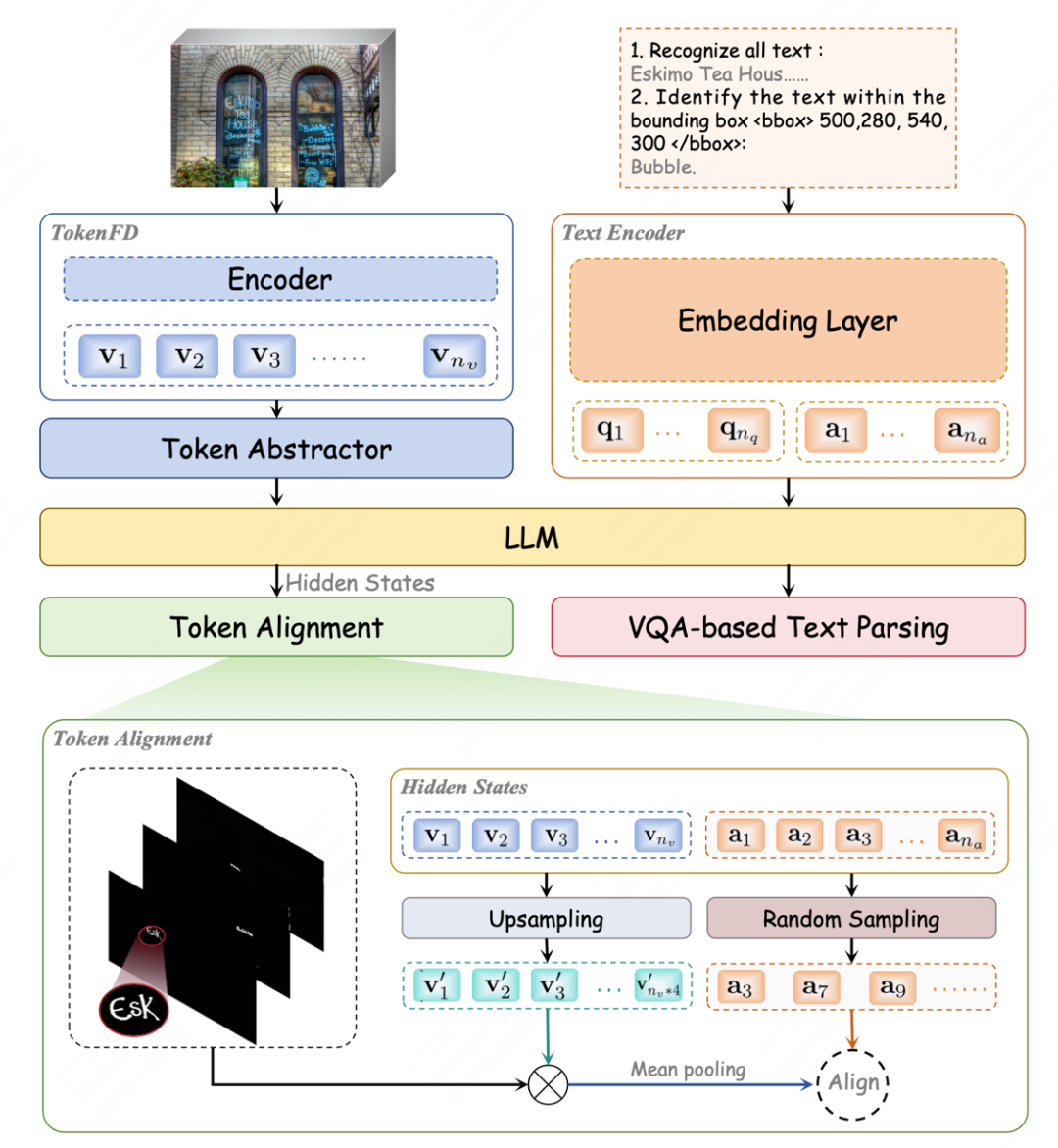
TokenVL 打通模态 GAP:进一步开放图像即文本的语义潜力,首次实现在大语言模型中进行 token 级的模态对齐,赋能密集型的多模态文档理解任务。

-
项目主页:https://token-family.github.io/project_page/ -
体验地址:https://huggingface.co/spaces/TongkunGuan/Token-level_Text_Image_Foundation_Model -
GitHub:https://github.com/Token-family/TokenFD -
论文地址: https://arxiv.org/pdf/2503.02304


-
包含 2000 万张图像与 18 亿 Token-Mask 对,覆盖自然场景、文档、图表、代码截图、图形用户界面等全场景文本图像类型。
-
数据量远超 CLIP(5 倍)、SAM(多 7 亿),提供更丰富的语义信息。
-
首创 BPE 分词 + 像素级掩码标注:将文本分割为 BPE 子词(如「un-」、「-able」),每个子词(token)精确对应图像中的局部区域。
-
支持「图像即文字」的语义映射,为多模态大模型理解字符、公式、表格等复杂结构奠定基础。
-
文本分割(Zero-Shot 性能提升 18.78%)
-
文本理解(Zero-Shot 性能提升 1.48%)
-
文本检索(Zero-Shot 性能提升 50.33%)
-
未来盼望他们支持可控文本生成/擦除等更多任务
-
赋能多模态大模型(例如 TokenVL)细粒度文字感知能力,显著提升 OCR、文档解析等任务表现。
-
图像安全审查
-
基于文字的图像检索(适用于搜索引擎、电商平台、社交平台)
-
知识检索增强的大模型

-
基座适配度百分百
-
文档理解多模态大模型对齐新范式
©
(文:机器之心)