


上海交通大学洪亮教授团队近期完成了一项重要研究:VenusMutHub——迄今为止首个针对真实应用场景蛋白质突变小样本数据集,并就此提出蛋白质功能零样本预测评测标准。
全球首个蛋白质突变工程真实应用场景小样本数据集及AI模型评测标准
上海交通大学洪亮教授团队近期完成了一项重要研究:VenusMutHub——迄今为止首个针对真实应用场景蛋白质突变小样本数据集,并就此提出蛋白质功能零样本预测评测标准,该研究发表在 Acta Pharmaceutica Sinica B 期刊上。
论文链接:
https://www.sciencedirect.com/science/article/pii/S2211383525001650?via%3Dihub
VenusMutHub 蛋白质突变小样本数据集:
https://go.hyper.ai/JFvt1
这项研究的重要性
蛋白质工程,特别是突变工程,是现代生物技术的核心支柱,广泛应用于工业酶、体外诊断大分子试剂与药物大分子的开发。然而,优秀蛋白分子的实验发现特别是工业化产品的实验发现成本高周期长,严重阻碍行业发展。近年来,AI 辅助定向进化与蛋白功能预测技术发展迅速,正在颠覆该工程方向的研究范式。然而,相关 AI 算法和模型种类繁多,研究人员难以抉择。
一个领域的 AI 模型的进步高度依赖黄金评测标准的建立,正如没有 CASP 竞赛就不会有 AlphaFold 一样。在蛋白质突变工程领域,当前 AI 模型的评测标准主要依赖高通量突变湿实验公开数据集,如哈佛医学院建立的 ProteinGym 数据集与评测体系。然而,这些高通量数据集存在明显局限性。
首先,它们通常采用荧光信号或细胞凋亡等表型读数来反应蛋白质核心功能(活性,稳定性,亲和力,选择性),虽然两者有一定相关性,但没有必然的正比关系。
其次,这类实验数据的测量精度往往不够,同一实验不同批次相关性较低;
第三,ProteinGym 榜单上先进模型的零样本预测与实验结果的相关系数高达0.5,而已发表的大模型蛋白突变任务湿实验研究中,相关系数通常仅为 0.2-0.4[1, 4],存在显著差距。
第四也是最重要的,对于大多数蛋白质功能表征,尤其是产业化应用场景,由于样品需求量大或实验设计复杂,难以实现高通量筛选,通常仅能测试几十至几百个突变体(有时更少)。
因此,高通量湿实验测试数据集对适合高通量方法的蛋白存在选择偏向,无法真实反映通用情况。这些问题都表明当前蛋白质突变工程 AI 模型的实验测试集存在诸多局限性,制约了行业发展,亟需建立一套适用于明确测量蛋白功能的小样本突变数据集及模型评测标准。
VenusMutHub:小样本数据集及相应评侧标准
针对行业痛点,洪亮教授团队推出了 VenusMutHub。他们精心整理了 905 个真实应用场景的小样本实验突变数据集,覆盖 527 种蛋白质 (其中 98% 的蛋白的突变数量在 5-200 个之间),涵盖了稳定性、活性、结合亲和力与选择性等多种功能测量数据。所有数据均采用直接生化测量,而非替代性荧光读数,确保了评估的准确性。
此外,团队还测试了 23 种前沿计算模型(AI 和非 AI 模型),涵盖利用蛋白质序列、三维结构与进化信息的多种方法,全面评估了这些模型在真实应用场景小样本数据上预测能力。
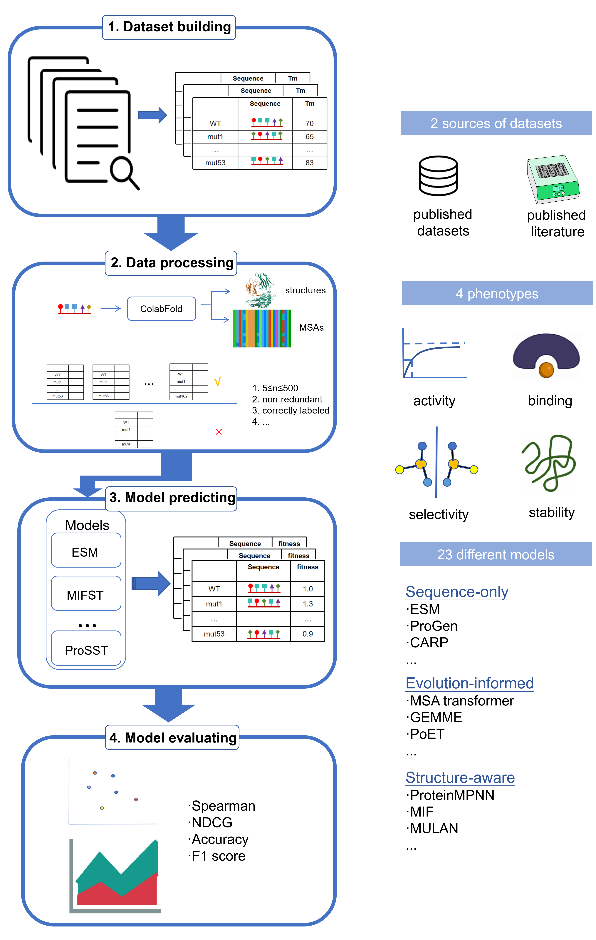
图 1. VenusMutHub工作流程总览
研究揭示了预测工具的表现特点与不足,并指明了未来方向:
* 模型表现因功能分类而异:
结构感知模型(如 MIF 和 MIFST)在稳定性预测中表现优异。
进化信息模型(如 VESPA 和 GEMME)在活性预测中更胜一筹。
整合序列、结构与进化信息的 VenusREM 展现了出色的综合性能。
* 突变数量的影响:所有模型在单点突变预测上显著优于多点突变,表明捕捉多点突变的上位效应仍是一大难题。
* 结合亲和力的挑战:在蛋白质-蛋白质相互作用 (PPI) 预测中,多数模型表现欠佳,凸显 PPI 界面的复杂性。输入多链信息的 ESM-IF1 和 ProteinMPNN 的预测能力优于只输入单链信息的模型,提示纳入复合物蛋白质结构信息的重要性。
* 选择性预测的瓶颈:选择性预测(包括对映体选择性与立体选择性)是最大难点,所有模型表现均不理想,(spearman correlation) 相关系数几乎为 0。这反映了当前方法的根本局限:选择性涉及蛋白对底物(或产物)的相对偏好,而现有模型仅关注蛋白质,未明确考虑底物特异性相互作用。
* 小样本测试集评估结果更真实:就模型预测零样本突变结果和湿实验功能结果的相关性而言,小样本数据集上的相关系数约为 0.2-0.3,而高通量数据集上高达 0.5,前者与已经发表的干湿印证的科学工作更接近,后者明显偏高。
应用价值与未来展望
VenusMutHub 在实际应用中具有重要价值,为蛋白质工程研究人员提供了实用指导:可根据目标特性选择最佳预测模型(如稳定性预测用结构感知模型,活性预测用进化信息模型),在经费受限情况下客观评估模型性能,加速设计流程并优先验证更有潜力的候选序列。
未来研究应聚焦整合蛋白质-配体对接模拟、引入立体化学特征及开发同时处理蛋白质与底物信息的专用架构,以突破结合亲和力和选择性预测瓶颈。作为开放资源,VenusMutHub将持续更新 (https://lianglab.sjtu.edu.cn/muthub/),为领域提供可靠基准,推动蛋白质功能预测走向更规范,更高速的发展。
结语:大模型应用的局限与展望
大模型在单点突变预测已经展现出跨不同功能,不同物种蛋白的应用潜力,但在实际场景中仍面临两大核心挑战:一是在有限实验条件下难以发现全新的优质突变位点(所有的大模型都有其偏好性,即使集成的专家系统也不例外);二是难以克服上位效应,设计满足需求的多点突变蛋白。现有研究表明,单一大模型或集成式专家系统尚无法完全解决这些问题。目前公开文献 [2-4] 显示,结合大模型表征能力、小样本学习、生成再蒸馏和非线性机制算法的干湿结合迭代方法能更有效地应对这些挑战。我们衷心期待更强大的大模型「神兵天降」,直接根据「人类自然语言提示词」生成满足产业需求的优秀性能的多点突变蛋白。但现阶段看来,道阻且长。
作者信息:
上海交通大学物理与天文学院硕士生张良、上海科技大学硕士生庞华、上海交通大学生命科学学院本科生张骋昊为共同第一作者,上海人工智能实验室青年研究员谈攀、上海交通大学自然科学院&物理与天文学院&生命科学学院&计算机学院博士生导师洪亮教授为共同通讯作者。
参考文献:
[1] Zhanga L, Pangb H, Zhang C, et al. VenusMutHub: A systematic evaluation of protein mutation effect predictors on small-scale experimental data[J]. arXiv preprint arXiv:2503.04851, 2025.
[2] Jiang F, Li M, Dong J, et al. A general temperature-guided language model to design proteins of enhanced stability and activity[J]. Science Advances, 2024, 10(48): eadr2641.
[3] Zhou Z, Zhang L, Yu Y, et al. Enhancing efficiency of protein language models with minimal wet-lab data through few-shot learning[J]. Nature Communications, 2024, 15(1): 5566.
[4] Jiang K, Yan Z, Di Bernardo M, et al. Rapid in silico directed evolution by a protein language model with EVOLVEpro[J]. Science, 2024: eadr6006.



戳“阅读原文”,免费获取海量数据集资源!
(文:HyperAI超神经)