
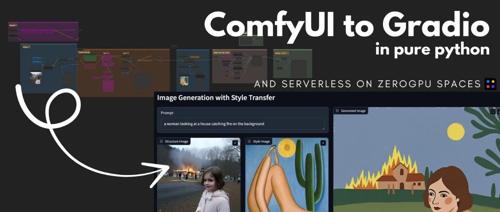
简介
在本教程中,我将逐步指导如何将一个复杂的 ComfyUI 工作流转换为一个简单的 Gradio 应用程序,并讲解如何将其部署在 Hugging Face Spaces 的 ZeroGPU 无服务器架构上,这样可以让它以无服务器的方式免费部署和运行。在本教程中,我们将使用 Nathan Shipley 的 Flux[dev] Redux + Flux[dev] Depth ComfyUI 工作流,但你可以按照教程的步骤操作任何你想要的工作流。
以下是本教程内容的简要概述:
-
使用 ComfyUI-to-Python-Extension 导出你的 ComfyUI 工作流;https://github.com/pydn/ComfyUI-to-Python-Extension -
为导出的 Python 代码创建一个 Gradio 应用程序; -
将其部署在 Hugging Face Spaces 的 ZeroGPU 上; -
即将推出: 整个过程将实现自动化。
前提条件:
-
了解如何运行 ComfyUI:
本教程需要你能够获取 ComfyUI 工作流并在本地机器上运行它,包括安装缺失的节点和找到缺失的模型 (不过我们计划很快自动化这一步)。 -
准备好要导出的工作流:
如果你还没有明确的工作流,可以尝试运行Nathan Shipley 的 Flux[dev] Redux + Flux[dev] Depth ComfyUI 工作流 作为学习示例。https://gist.github.com/nathanshipley/7a9ac1901adde76feebe58d558026f68 -
一点点编程知识:
虽然需要一些基础的编程知识,但我鼓励初学者尝试跟随本教程,因为它可以作为一个很好的 Python、Gradio 和 Hugging Face Spaces 的入门指南,不需要太多的编程经验。
如果你正在寻找一种端到端的“工作流到应用”的解决方案, 无需设置和运行 ComfyUI 或具备编程知识,请关注我的
-
Hugging Face 主页 https://hf.co/multimodalart/ -
Twitter/X https://twitter.com/multimodalart
1. 将 ComfyUI 工作流导出为纯 Python 代码运行
ComfyUI 非常强大,正如其名称所示,它包含一个用户界面 (UI),但 ComfyUI 不仅仅是一个 UI,它还包含一个基于 Python 的后端。由于在本教程中我们不打算使用 ComfyUI 的基于节点的 UI,因此需要将代码导出为纯 Python 脚本来运行。
幸运的是,
-
Peyton DeNiro https://github.com/pydn -
ComfyUI-to-Python-Extension https://github.com/pydn/ComfyUI-to-Python-Extension
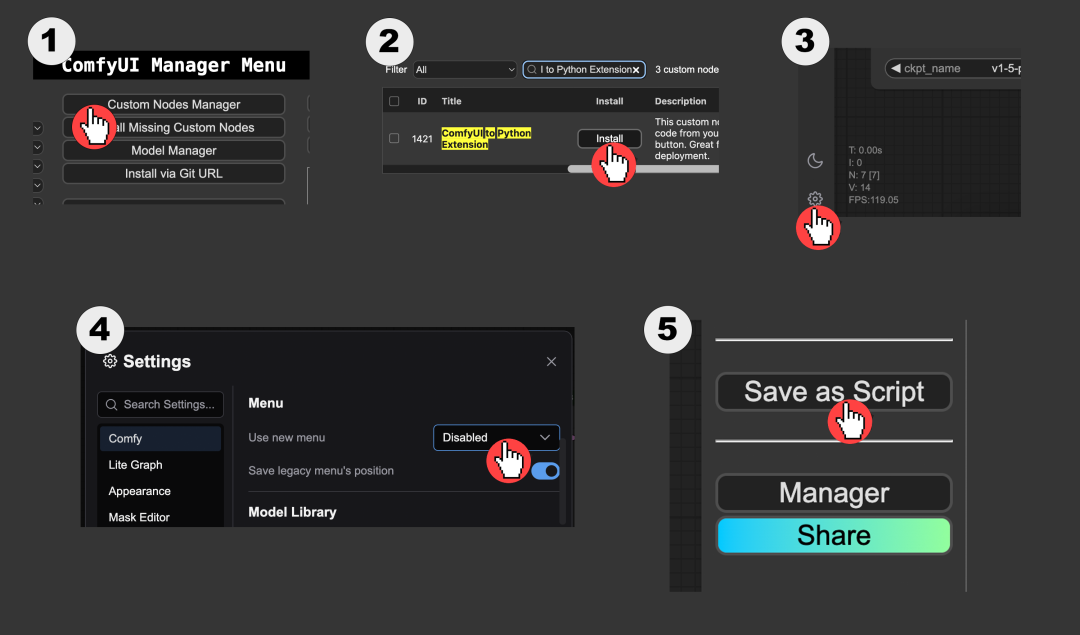
安装该扩展的最简单方法是:
(1) 在 ComfyUI Manager 扩展的 Custom Nodes Manager 菜单中搜索 ComfyUI to Python Extension 并安装。
(2) 前往 UI 右下角的设置禁用新菜单。
(3) 点击 Save as Script 。
这样,你将得到一个 Python 脚本。
2. 准备在 Hugging Face Spaces 上运行
现在我们有了 Python 脚本,接下来是创建一个 Gradio 应用程序来运行它。Gradio 是一个基于 Python 的 Web UI 构建工具,可以帮助我们快速创建简洁的应用程序。如果你还没有安装 Gradio,可以通过 pip install gradio 命令在你的 Python 环境中安装它。
接下来,我们需要稍微调整一下 Python 脚本,以便为其创建一个用户界面 (UI)。
小提示: 像 ChatGPT、Claude、Qwen、Gemini、LLama 3 等大型语言模型 (LLMs) 都知道如何创建 Gradio 应用程序。你可以将导出的 Python 脚本粘贴给它们,并要求它们帮你创建一个 Gradio 应用,这在基础层面上是可行的。不过,你可能需要根据本教程中学到的知识进行一些修正。为了本教程的目的,我们将自己动手创建这个应用程序。
打开导出的 Python 脚本,并在文件顶部添加 Gradio 的导入语句:
import os
import random
import sys
from typing import Sequence, Mapping, Any, Union
import torch
+ import gradio as gr
现在,我们需要考虑 UI 的设计—— 从复杂的 ComfyUI 工作流中,我们希望在 UI 中暴露哪些参数? 对于 Flux[dev] Redux + Flux[dev] Depth ComfyUI 工作流 ,我希望暴露以下参数: 提示词 (prompt) 、结构图像 (structure image) 、风格图像 (style image) 、深度强度 (depth strength,用于结构) 和风格强度 (style strength)。
视频说明哪些节点将暴露给最终用户
因此一个最简单的 Gradio 应用可以如下所示:
if __name__ == "__main__":
# 在导出的 Python 代码中注释掉对 main() 函数的调用
# 开启 Gradio 程序
with gr.Blocks() as app:
# 添加标题
gr.Markdown("# FLUX Style Shaping")
with gr.Row():
with gr.Column():
# 添加输入
prompt_input = gr.Textbox(label="Prompt", placeholder="Enter your prompt here...")
# 添加一个“Row”以将组并排显示
with gr.Row():
# 第一组包括结构图像和深度强度
with gr.Group():
structure_image = gr.Image(label="Structure Image", type="filepath")
depth_strength = gr.Slider(minimum=0, maximum=50, value=15, label="Depth Strength")
# 第二组包括风格图像和风格强度
with gr.Group():
style_image = gr.Image(label="Style Image", type="filepath")
style_strength = gr.Slider(minimum=0, maximum=1, value=0.5, label="Style Strength")
# 生成按钮
generate_btn = gr.Button("Generate")
with gr.Column():
# 输出图像
output_image = gr.Image(label="Generated Image")
# 当点击按钮时,它将触发“generate_image”函数,该函数带有相应的输入
# 并且输出是一张图像
generate_btn.click(
fn=generate_image,
inputs=[prompt_input, structure_image, style_image, depth_strength, style_strength],
outputs=[output_image]
)
app.launch(share=True)
这是应用程序渲染后的样子
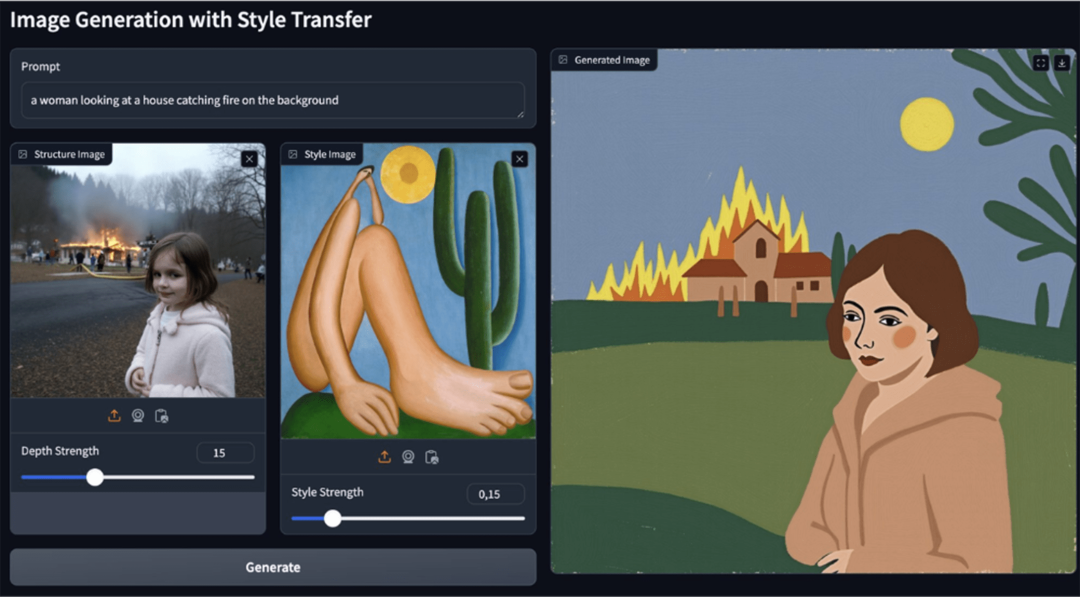
但是,如果你尝试运行它,它还无法工作,因为现在我们需要通过修改我们导出的 Python 脚本中的 def main() 函数来设置这个 generate_image 函数。
脚本:
- def main():
+ def generate_image(prompt, structure_image, style_image, depth_strength, style_strength)
在函数内部,我们需要找到我们想要的节点的硬编码值,并将其替换为我们想要控制的变量,例如:
loadimage_429 = loadimage.load_image(
- image="7038548d-d204-4810-bb74-d1dea277200a.png"
+ image=structure_image
)
# ...
loadimage_440 = loadimage.load_image(
- image="2013_CKS_01180_0005_000(the_court_of_pir_budaq_shiraz_iran_circa_1455-60074106).jpg"
+ image=style_image
)
# ...
fluxguidance_430 = fluxguidance.append(
- guidance=15,
+ guidance=depth_strength,
conditioning=get_value_at_index(cliptextencode_174, 0)
)
# ...
stylemodelapplyadvanced_442 = stylemodelapplyadvanced.apply_stylemodel(
- strength=0.5,
+ strength=style_strength,
conditioning=get_value_at_index(instructpixtopixconditioning_431, 0),
style_model=get_value_at_index(stylemodelloader_441, 0),
clip_vision_output=get_value_at_index(clipvisionencode_439, 0),
)
# ...
cliptextencode_174 = cliptextencode.encode(
- text="a girl looking at a house on fire",
+ text=prompt,
clip=get_value_at_index(cr_clip_input_switch_319, 0),
)
对于我们的输出,我们需要找到保存图像输出节点,并导出其路径,例如:
saveimage_327 = saveimage.save_images(
filename_prefix=get_value_at_index(cr_text_456, 0),
images=get_value_at_index(vaedecode_321, 0),
)
+ saved_path = f"output/{saveimage_327['ui']['images'][0]['filename']}"
+ return saved_path
查看这些修改的视频概述:
现在,我们应该准备好运行代码了!将你的 Python 文件保存为 app.py,将其添加到 ComfyUI 文件夹的根目录中,并以“python app.py”的方式运行它。
python app.py
这样你应该能够在 http://0.0.0.0:7860 上运行你的 Gradio 应用程序。
* Running on local URL: http://127.0.0.1:7860
* Running on public URL: https://366fdd17b8a9072899.gradio.live
为了调试这个过程,请查看ComfyUI-to-Python-Extension 导出的原始 Python 文件与 Gradio 应用之间的差异。你也可以在该 URL 下载这两个文件,以便检查和与你自己的工作流进行比较。
就是这样,恭喜你!你已经成功将 ComfyUI 工作流转换为 Gradio 应用,你可以在本地运行它,甚至可以将 URL 发送给客户或朋友。然而,如果你关闭电脑或超过 72 小时,临时的 Gradio 链接将会失效。为了获得一个持久的托管应用的结构——包括允许人们以无服务器的方式免费运行它,你可以使用 Hugging Face Spaces。
3. 为导出的 Python 代码创建 Gradio 应用
现在,我们的 Gradio 演示已经可以运行了,你可能会想直接将所有内容上传到 Hugging Face Spaces。然而,这将需要上传数十 GB 的模型到 Hugging Face,这不仅速度慢,而且没有必要,因为这些模型已经存在于 Hugging Face 上了!
相反,如果我们还没有安装 huggingface_hub ,首先需要安装它:
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="black-forest-labs/FLUX.1-Redux-dev", filename="flux1-redux-dev.safetensors", local_dir="models/style_models")
hf_hub_download(repo_id="black-forest-labs/FLUX.1-Depth-dev", filename="flux1-depth-dev.safetensors", local_dir="models/diffusion_models")
hf_hub_download(repo_id="Comfy-Org/sigclip_vision_384", filename="sigclip_vision_patch14_384.safetensors", local_dir="models/clip_vision")
hf_hub_download(repo_id="Kijai/DepthAnythingV2-safetensors", filename="depth_anything_v2_vitl_fp32.safetensors", local_dir="models/depthanything")
hf_hub_download(repo_id="black-forest-labs/FLUX.1-dev", filename="ae.safetensors", local_dir="models/vae/FLUX1")
hf_hub_download(repo_id="comfyanonymous/flux_text_encoders", filename="clip_l.safetensors", local_dir="models/text_encoders")
hf_hub_download(repo_id="comfyanonymous/flux_text_encoders", filename="t5xxl_fp16.safetensors", local_dir="models/text_encoders/t5")
这将把所有 ComfyUI 中的本地模型映射到它们在 Hugging Face 上的版本。遗憾的是,目前还没有办法自动化这一过程,你需要 手动 找到工作流中使用的模型在 Hugging Face 上的对应版本,并将它们映射到 ComfyUI 的相同文件夹中。
如果你运行的模型不在 Hugging Face 上,你需要找到一种方法,通过 Python 代码将它们下载到正确的文件夹中。这段代码只会在 Hugging Face Space 启动时运行一次。
现在,我们将对 app.py 文件进行最后一次修改,即添加 ZeroGPU 的函数装饰器,这将让我们能够免费进行推理!
import gradio as gr
from huggingface_hub import hf_hub_download
+ import spaces
# ...
+ @spaces.GPU(duration=60) #modify the duration for the average it takes for your worflow to run, in seconds
def generate_image(prompt, structure_image, style_image, depth_strength, style_strength):
请查看
4. 导出到 Spaces 并在 ZeroGPU 上运行
代码已准备妥当。你既可以在本地运行,也可选择任意心仪的云服务,如 Hugging Face Spaces 的专用 GPU。若要在无服务器的 ZeroGPU 上运行,请遵循以下步骤。
修复依赖项
首先,你需要修改 requirements.txt 文件,以包含 custom_nodes 文件夹中的依赖项。由于 Hugging Face Spaces 要求只有一个 requirements.txt 文件,因此请确保将此工作流所需的节点依赖项添加到根目录的 requirements.txt 文件中。
如下图所示,需要对所有 custom_nodes 重复此过程:
现在我们准备好了!
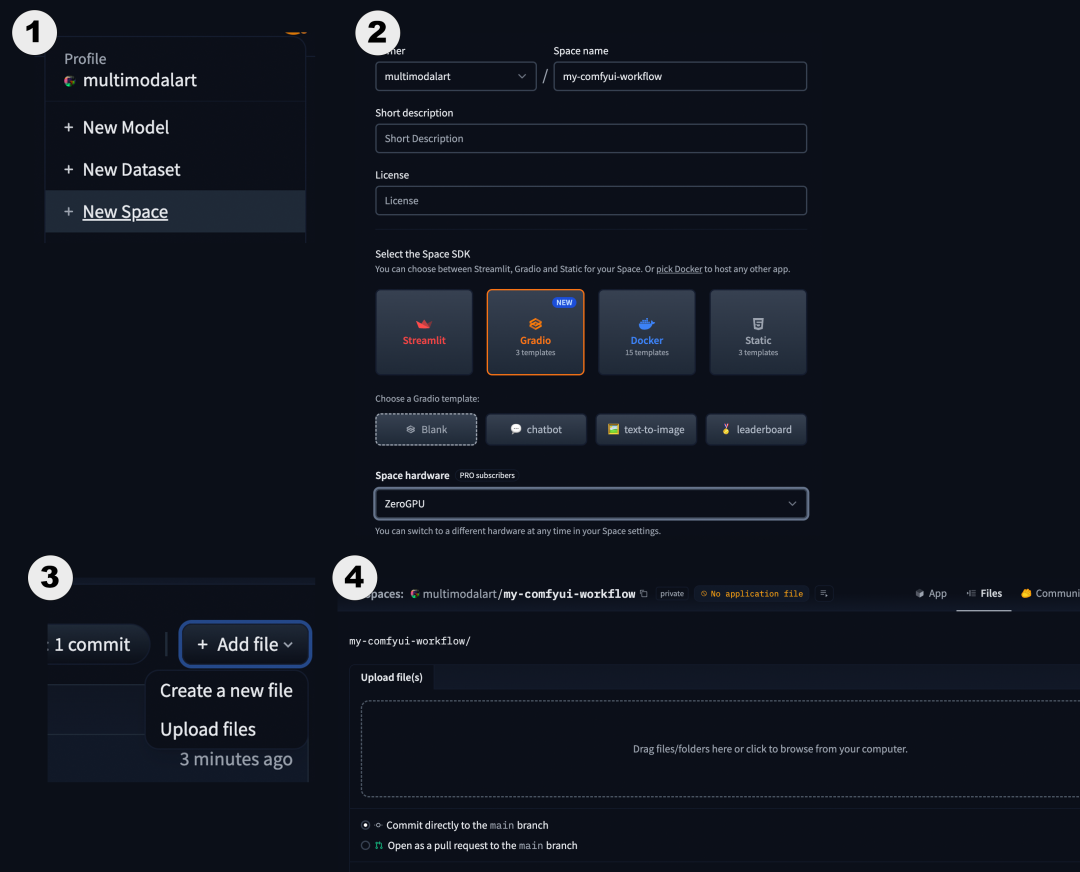
-
访问 Hugging Face 并创建一个新的 Space。https://hf.co/ -
将其硬件设置为 ZeroGPU (如果你是 Hugging Face PRO 订阅用户),或者如果你不是 PRO 用户,则设置为 CPU Basic (如果你不是 PRO 用户,最后可能需要一个额外的步骤)。2.1. (如果你更喜欢使用付费的专用 GPU,可以选择 L4、L40S 或 A100,而不是 ZeroGPU,这是一个付费选项)。 -
点击 “Files” 选项卡,选择 File > Upload Files。拖动你的 ComfyUI 文件夹中的所有文件 除了models文件夹 (如果你尝试上传models文件夹,上传会失败),这就是为什么我们需要第 3 部分的原因。 -
点击页面底部的 Commit changes to main按钮,等待所有内容上传完成。 -
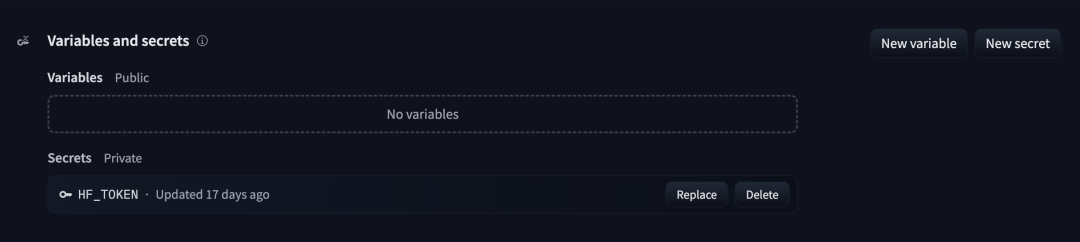
如果你使用的是受限模型 (如 FLUX),你需要在设置中添加一个 Hugging Face 令牌。首先,在 这里 创建一个具有read权限的令牌,用于访问你需要的所有受限模型,然后进入你的 Space 的Settings页面,创建一个名为HF_TOKEN的新密钥,并将你刚刚创建的令牌值填入。https://hf.co/settings/tokens
将模型移出装饰函数 (仅适用于 ZeroGPU)
你的演示应该已经可以运行了,但在当前的设置中,每次运行时模型都会从磁盘完全加载到 GPU 中。为了利用无服务器 ZeroGPU 的效率,我们需要将所有模型声明移到装饰函数之外,放到 Python 的全局上下文中,我们编辑 app.py 文件来实现这一点。
@@ -4,6 +4,7 @@
from typing import Sequence, Mapping, Any, Union
import torch
import gradio as gr
from huggingface_hub import hf_hub_download
+from comfy import model_management
import spaces
hf_hub_download(repo_id="black-forest-labs/FLUX.1-Redux-dev", filename="flux1-redux-dev.safetensors", local_dir="models/style_models")
@@ -109,6 +110,62 @@
from nodes import NODE_CLASS_MAPPINGS
+intconstant = NODE_CLASS_MAPPINGS["INTConstant"]()
+dualcliploader = NODE_CLASS_MAPPINGS["DualCLIPLoader"]()
+dualcliploader_357 = dualcliploader.load_clip(
+ clip_name1="t5/t5xxl_fp16.safetensors",
+ clip_name2="clip_l.safetensors",
+ type="flux",
+)
+cr_clip_input_switch = NODE_CLASS_MAPPINGS["CR Clip Input Switch"]()
+cliptextencode = NODE_CLASS_MAPPINGS["CLIPTextEncode"]()
+loadimage = NODE_CLASS_MAPPINGS["LoadImage"]()
+imageresize = NODE_CLASS_MAPPINGS["ImageResize+"]()
+getimagesizeandcount = NODE_CLASS_MAPPINGS["GetImageSizeAndCount"]()
+vaeloader = NODE_CLASS_MAPPINGS["VAELoader"]()
+vaeloader_359 = vaeloader.load_vae(vae_name="FLUX1/ae.safetensors")
+vaeencode = NODE_CLASS_MAPPINGS["VAEEncode"]()
+unetloader = NODE_CLASS_MAPPINGS["UNETLoader"]()
+unetloader_358 = unetloader.load_unet(
+ unet_name="flux1-depth-dev.safetensors", weight_dtype="default"
+)
+ksamplerselect = NODE_CLASS_MAPPINGS["KSamplerSelect"]()
+randomnoise = NODE_CLASS_MAPPINGS["RandomNoise"]()
+fluxguidance = NODE_CLASS_MAPPINGS["FluxGuidance"]()
+depthanything_v2 = NODE_CLASS_MAPPINGS["DepthAnything_V2"]()
+downloadandloaddepthanythingv2model = NODE_CLASS_MAPPINGS[
+ "DownloadAndLoadDepthAnythingV2Model"
+]()
+downloadandloaddepthanythingv2model_437 = (
+ downloadandloaddepthanythingv2model.loadmodel(
+ model="depth_anything_v2_vitl_fp32.safetensors"
+ )
+)
+instructpixtopixconditioning = NODE_CLASS_MAPPINGS[
+ "InstructPixToPixConditioning"
+]()
+text_multiline_454 = text_multiline.text_multiline(text="FLUX_Redux")
+clipvisionloader = NODE_CLASS_MAPPINGS["CLIPVisionLoader"]()
+clipvisionloader_438 = clipvisionloader.load_clip(
+ clip_name="sigclip_vision_patch14_384.safetensors"
+)
+clipvisionencode = NODE_CLASS_MAPPINGS["CLIPVisionEncode"]()
+stylemodelloader = NODE_CLASS_MAPPINGS["StyleModelLoader"]()
+stylemodelloader_441 = stylemodelloader.load_style_model(
+ style_model_name="flux1-redux-dev.safetensors"
+)
+text_multiline = NODE_CLASS_MAPPINGS["Text Multiline"]()
+emptylatentimage = NODE_CLASS_MAPPINGS["EmptyLatentImage"]()
+cr_conditioning_input_switch = NODE_CLASS_MAPPINGS[
+ "CR Conditioning Input Switch"
+]()
+cr_model_input_switch = NODE_CLASS_MAPPINGS["CR Model Input Switch"]()
+stylemodelapplyadvanced = NODE_CLASS_MAPPINGS["StyleModelApplyAdvanced"]()
+basicguider = NODE_CLASS_MAPPINGS["BasicGuider"]()
+basicscheduler = NODE_CLASS_MAPPINGS["BasicScheduler"]()
+samplercustomadvanced = NODE_CLASS_MAPPINGS["SamplerCustomAdvanced"]()
+vaedecode = NODE_CLASS_MAPPINGS["VAEDecode"]()
+saveimage = NODE_CLASS_MAPPINGS["SaveImage"]()
+imagecrop = NODE_CLASS_MAPPINGS["ImageCrop+"]()
@@ -117,75 +174,6 @@
def generate_image(prompt, structure_image, style_image, depth_strength, style_strength):
import_custom_nodes()
with torch.inference_mode():
- intconstant = NODE_CLASS_MAPPINGS["INTConstant"]()
intconstant_83 = intconstant.get_value(value=1024)
intconstant_84 = intconstant.get_value(value=1024)
- dualcliploader = NODE_CLASS_MAPPINGS["DualCLIPLoader"]()
- dualcliploader_357 = dualcliploader.load_clip(
- clip_name1="t5/t5xxl_fp16.safetensors",
- clip_name2="clip_l.safetensors",
- type="flux",
- )
-
- cr_clip_input_switch = NODE_CLASS_MAPPINGS["CR Clip Input Switch"]()
cr_clip_input_switch_319 = cr_clip_input_switch.switch(
Input=1,
clip1=get_value_at_index(dualcliploader_357, 0),
clip2=get_value_at_index(dualcliploader_357, 0),
)
- cliptextencode = NODE_CLASS_MAPPINGS["CLIPTextEncode"]()
cliptextencode_174 = cliptextencode.encode(
text=prompt,
clip=get_value_at_index(cr_clip_input_switch_319, 0),
)
cliptextencode_175 = cliptextencode.encode(
text="purple", clip=get_value_at_index(cr_clip_input_switch_319, 0)
)
- loadimage = NODE_CLASS_MAPPINGS["LoadImage"]()
loadimage_429 = loadimage.load_image(image=structure_image)
- imageresize = NODE_CLASS_MAPPINGS["ImageResize+"]()
imageresize_72 = imageresize.execute(
width=get_value_at_index(intconstant_83, 0),
height=get_value_at_index(intconstant_84, 0),
interpolation="bicubic",
method="keep proportion",
condition="always",
multiple_of=16,
image=get_value_at_index(loadimage_429, 0),
)
- getimagesizeandcount = NODE_CLASS_MAPPINGS["GetImageSizeAndCount"]()
getimagesizeandcount_360 = getimagesizeandcount.getsize(
image=get_value_at_index(imageresize_72, 0)
)
- vaeloader = NODE_CLASS_MAPPINGS["VAELoader"]()
- vaeloader_359 = vaeloader.load_vae(vae_name="FLUX1/ae.safetensors")
- vaeencode = NODE_CLASS_MAPPINGS["VAEEncode"]()
vaeencode_197 = vaeencode.encode(
pixels=get_value_at_index(getimagesizeandcount_360, 0),
vae=get_value_at_index(vaeloader_359, 0),
)
- unetloader = NODE_CLASS_MAPPINGS["UNETLoader"]()
- unetloader_358 = unetloader.load_unet(
- unet_name="flux1-depth-dev.safetensors", weight_dtype="default"
- )
- ksamplerselect = NODE_CLASS_MAPPINGS["KSamplerSelect"]()
ksamplerselect_363 = ksamplerselect.get_sampler(sampler_name="euler")
- randomnoise = NODE_CLASS_MAPPINGS["RandomNoise"]()
randomnoise_365 = randomnoise.get_noise(noise_seed=random.randint(1, 2**64))
- fluxguidance = NODE_CLASS_MAPPINGS["FluxGuidance"]()
fluxguidance_430 = fluxguidance.append(
guidance=15, conditioning=get_value_at_index(cliptextencode_174, 0)
)
- downloadandloaddepthanythingv2model = NODE_CLASS_MAPPINGS[
- "DownloadAndLoadDepthAnythingV2Model"
- ]()
- downloadandloaddepthanythingv2model_437 = (
- downloadandloaddepthanythingv2model.loadmodel(
- model="depth_anything_v2_vitl_fp32.safetensors"
- )
- )
- depthanything_v2 = NODE_CLASS_MAPPINGS["DepthAnything_V2"]()
depthanything_v2_436 = depthanything_v2.process(
da_model=get_value_at_index(downloadandloaddepthanythingv2model_437, 0),
images=get_value_at_index(getimagesizeandcount_360, 0),
)
- instructpixtopixconditioning = NODE_CLASS_MAPPINGS[
- "InstructPixToPixConditioning"
- ]()
instructpixtopixconditioning_431 = instructpixtopixconditioning.encode(
positive=get_value_at_index(fluxguidance_430, 0),
negative=get_value_at_index(cliptextencode_175, 0),
vae=get_value_at_index(vaeloader_359, 0),
pixels=get_value_at_index(depthanything_v2_436, 0),
)
- clipvisionloader = NODE_CLASS_MAPPINGS["CLIPVisionLoader"]()
- clipvisionloader_438 = clipvisionloader.load_clip(
- clip_name="sigclip_vision_patch14_384.safetensors"
- )
loadimage_440 = loadimage.load_image(image=style_image)
- clipvisionencode = NODE_CLASS_MAPPINGS["CLIPVisionEncode"]()
clipvisionencode_439 = clipvisionencode.encode(
crop="center",
clip_vision=get_value_at_index(clipvisionloader_438, 0),
image=get_value_at_index(loadimage_440, 0),
)
- stylemodelloader = NODE_CLASS_MAPPINGS["StyleModelLoader"]()
- stylemodelloader_441 = stylemodelloader.load_style_model(
- style_model_name="flux1-redux-dev.safetensors"
- )
-
- text_multiline = NODE_CLASS_MAPPINGS["Text Multiline"]()
text_multiline_454 = text_multiline.text_multiline(text="FLUX_Redux")
- emptylatentimage = NODE_CLASS_MAPPINGS["EmptyLatentImage"]()
- cr_conditioning_input_switch = NODE_CLASS_MAPPINGS[
- "CR Conditioning Input Switch"
- ]()
- cr_model_input_switch = NODE_CLASS_MAPPINGS["CR Model Input Switch"]()
- stylemodelapplyadvanced = NODE_CLASS_MAPPINGS["StyleModelApplyAdvanced"]()
- basicguider = NODE_CLASS_MAPPINGS["BasicGuider"]()
- basicscheduler = NODE_CLASS_MAPPINGS["BasicScheduler"]()
- samplercustomadvanced = NODE_CLASS_MAPPINGS["SamplerCustomAdvanced"]()
- vaedecode = NODE_CLASS_MAPPINGS["VAEDecode"]()
- saveimage = NODE_CLASS_MAPPINGS["SaveImage"]()
- imagecrop = NODE_CLASS_MAPPINGS["ImageCrop+"]()
emptylatentimage_10 = emptylatentimage.generate(
width=get_value_at_index(imageresize_72, 1),
height=get_value_at_index(imageresize_72, 2),
batch_size=1,
)
此外,为了预加载模型,我们需要使用 ComfyUI 的 load_models_gpu 函数,该函数会将上述预加载的模型中所有已加载的模型包含进来 (一个经验法则是检查哪些模型加载了 *.safetensors 文件)。
from comfy import model_management
# 添加所有加载 safetensors 文件的模型
model_loaders = [dualcliploader_357, vaeloader_359, unetloader_358, clipvisionloader_438, stylemodelloader_441, downloadandloaddepthanythingv2model_437]
# 检查哪些模型是有效的,并确定最佳加载方式
valid_models = [
getattr(loader[0], 'patcher', loader[0])
for loader in model_loaders
if not isinstance(loader[0], dict) and not isinstance(getattr(loader[0], 'patcher', None), dict)
]
# 最终加载模型
model_management.load_models_gpu(valid_models)
在 GitHub 中
非专业版订阅用户请留意 (专业版用户可跳过此步骤)
若你并非 Hugging Face 专业版订阅用户,则需申请 ZeroGPU 授权。你只需进入自己的 Space 设置页面,提交 ZeroGPU 授权请求即可,操作十分简便。所有采用 ComfyUI 后端的 Spaces 的 ZeroGPU 授权请求都将获批。🎉
演示正在运行
本教程中我们构建的演示示例已经发布到 Hugging Face Spaces 上啦,点击这里体验:
5. 结论
😮💨,就这些了!我知道这需要花费一些精力,但作为回报,你可以轻松的使用一个简洁的用户界面和免费推理将你的工作流分享给所有人!正如之前所述,我们的目标是在 2025 年初尽可能地自动化和简化这一过程!
原文链接:
https://hf.co/blog/run-comfyui-workflows-on-spaces 原文作者: Apolinário from multimodal AI art, Charles Bensimon
译者: evinci
(文:Hugging Face)