


近年来,随着 o1 或 Deepseek-r1 等推理模型在复杂决策和推理任务中的迅速发展,强化学习(Reinforcement Learning, RL)在模型训练与推理优化中的价值越发凸显。通过对庞大搜索空间进行有效探索与学习,RL 在机器决策和自动化设计等多个领域发挥了重要作用。
基于这一趋势,我们希望将强化学习引入社区建筑布局生成这一更具挑战性的场景,利用多智能体协同来高效探索布局空间并满足多重设计需求。
建筑布局设计对建筑师来说是一项耗时且劳动密集的任务,行业需要高度自动化的方法。与近来有较多研究的室内布局生成相比,社区建筑布局生成由于建筑间隔和容积率等限制而面临更多挑战。现有的依赖于规则或启发式搜索的算法难以平衡这些因素。此外,缺乏用于评估的数据集。
我们为该任务定义状态、动作空间和奖励函数,提出了一种基于多智能体强化学习的解法,以及一套用于评估社区建筑布局的指标,在现实世界场景中的实验结果表明该方法的有效性。
本研究成果发表于 Knowledge and Information Systems(JCR Q2 国际期刊,致力于发表在知识与先进信息系统领域热门话题的前沿研究成果)。
论文标题:
Deep reinforcement learning for community architectural layout generation
论文链接:
https://link.springer.com/article/10.1007/s10115-024-02291-4

Introduction
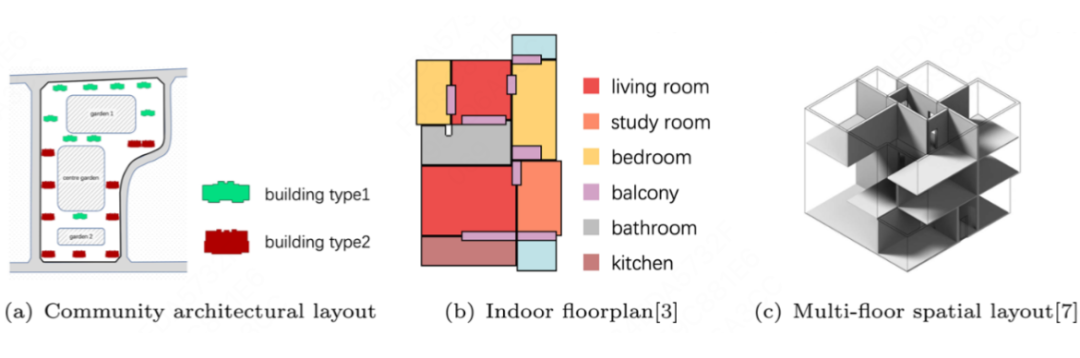
建筑布局设计在城市设计 [1,2] 中起着重要作用,建筑师需要花费大量时间对建筑布局设计进行规划和调整。许多现有算法主要侧重于室内布局图的生成,比如 HouseGAN++ [3] 等,这些算法受益于丰富的数据集如 RPLAN 和 LIFULL HOME,可以应用计算机视觉领域的生成式方法。
相比之下,社区建筑布局生成是在给定地块边界和建筑参数的条件下,对建筑物进行布置并生成合理的建筑布局。如图所示,该任务通常具有较低的自由度,受到建筑物形状、数量、间隔等的限制。此外,用于训练的社区建筑布局数据集仍然不足。
Rule-based 方法是最直观的 [4],它们根据领域知识为建筑物布置设定规则。然而,定义这些规则可能非常困难。启发式搜索是解决优化问题的主要方法之一,Zheng 等人 [5] 探索了模拟退火算法在生成建筑布局中的应用,呈现了在特定参数下的模拟地块中的应用结果。
然而启发式搜索算法很难满足地块和建筑物的硬约束,且大规模地块的搜索空间巨大、耗时长。GAN 方法如 Sch-GAN [6] 应用 Pix2Pix [7] 模型根据给定的校园边界自动生成校园布局,但依赖于专家手动处理过的数据集,且难以精细约束。
在实践中,建筑师需要对建筑物的位置进行多次决策,通过获取当前决策的反馈信息来逐步完善建筑布局,直到做出令人满意的设计。这个过程可以很自然地被建模为强化学习问题。
尽管强化学习在诸多领域取得进展,但在建筑布局生成中面临两大挑战:1)大规模动作空间导致策略学习困难,前期错误布局会限制后续建筑排布,难以满足输入参数要求;2)需平衡建筑师设计中的多因素权衡,单一线性奖励函数难以有效协调冲突目标。
本文提出方法的主要思路是训练多智能体(mutli-agent)来调整建筑物的位置,以优化布局设计。我们利用规则初始化地块的结果来丰富 agent 的状态。放置在地块上的建筑物由多智能体来表示,它们会执行动作并调整位置。
奖励函数是根据建筑师在布局时所考虑的各种因素(如均匀度和对齐度)设计的,并通过课程学习策略从全局到局部逐步训练模型。此外,我们还提出了计算这些因素的定量方法。

Problem Formulation
社区建筑布局任务定义为:给定一个地块边界和需要放置的建筑列表,包括各类型建筑的尺寸和需放置的数量,以及建筑的最小横纵间距,期望输出所有放置建筑的中心点坐标。
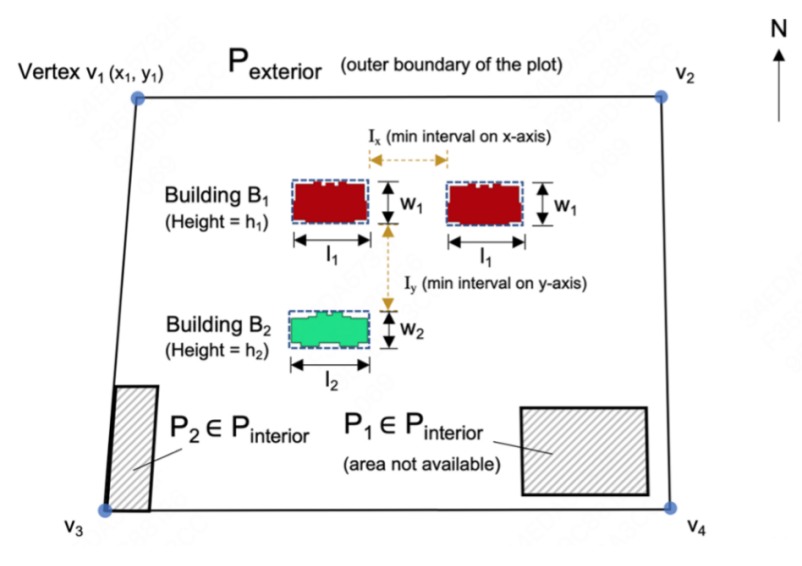
其中,P_exterior 表示外边界,所有建筑需要放置在外边界内;P_interior 表示内边界,用来标明不可排布的区域(如公共绿化等)。

Methodology
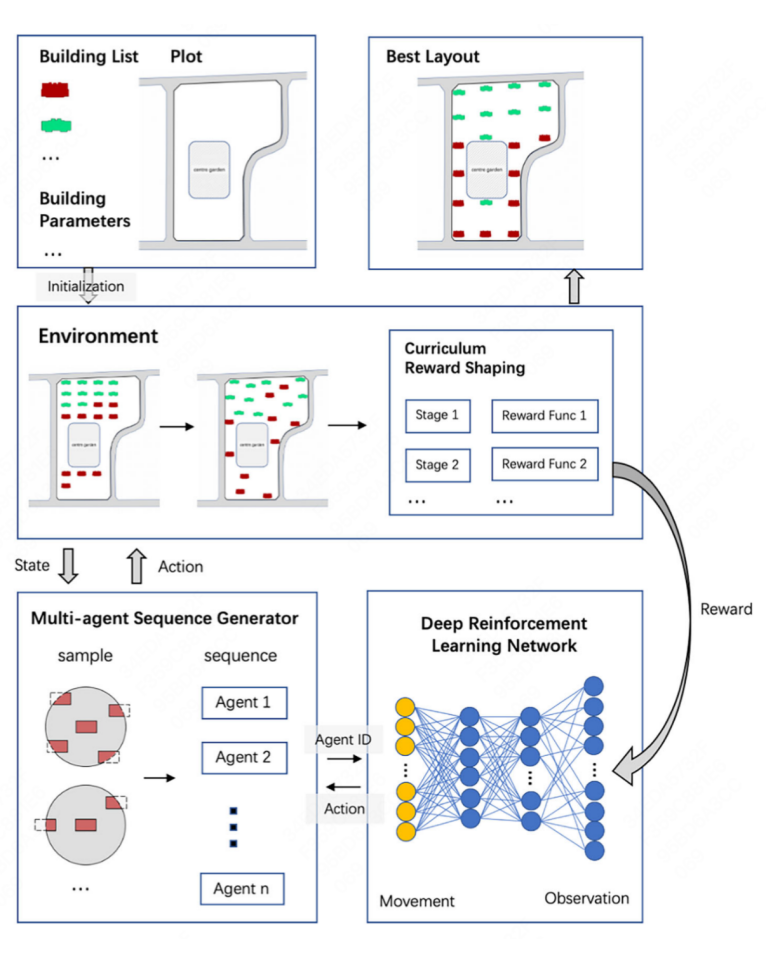
方法的框架如图所示。基于输入的建筑参数,为每个智能体(agent)初始化位置,agent 根据 DQN 模型输出的策略,在课程奖励的引导下,分阶段调整动作选择策略、调整位置,逐步优化布局。
动作空间是离散的,agent 在每个 step 可以上、下、左、右将建筑移动 1m 或不执行动作。如果移动出了边界或不满足最小间距约束,该动作会被丢弃且返回一个惩罚性奖励。
奖励函数被定义为与建筑布局相关的指标的加权组合,包括贴边度(r_edges)、对齐度(r_align)、均匀度(r_even)和中心度(r_center)。
我们将与建筑师讨论得出的定性评估方式定量化,计算 r_edges 为建筑的边界框与地块的相交边数,r_align 为建筑坐标重合的占比,r_even 为建筑距离的标准差,r_center 为所有建筑的平均中心与地块中心的重合程度。
奖励函数被设计为多阶段,初期鼓励探索,奖励基础约束满足(如边界避障);后期引入密集奖励,优化空间均匀程度,通过加权奖励驱动布局收敛。学习策略上使用 DQN 作为 backbone,因其兼顾了生成效率和效果。
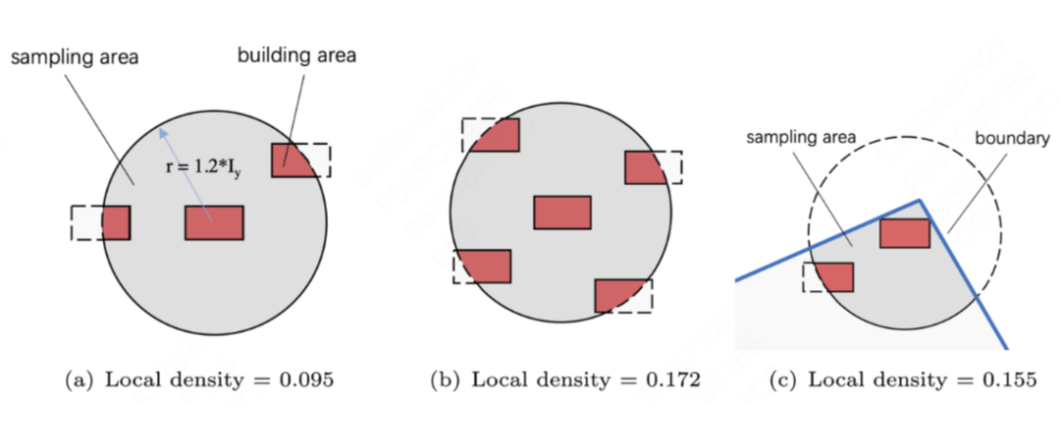
为了提高建筑的调整效率,我们计算每个建筑的局部密度,从局部密度最低的建筑对应的 agent 开始执行动作,尽量避免排列堵塞带来的大量无效动作。
算法的核心流程如下图所示:


Experiments
我们在上海市的 100 个真实地块 [8] 上对比了各方法的效果,基线模型包括 Rule-based 纯规则方法、Simulated annealing(SA)、Single-Agent RL(SARL)使用单 agent 每个 step 向地块上放置一个建筑、Multi-Agent RL(MARL)。
我们使用建筑覆盖率、中心程度、对齐度、均匀度、接受率和加权得到的 reward 作为评估指标。其中建筑覆盖率定义为建筑外轮廓的凸包面积与地块面积之比,接受率为方案满足输入约束且合法的比例。
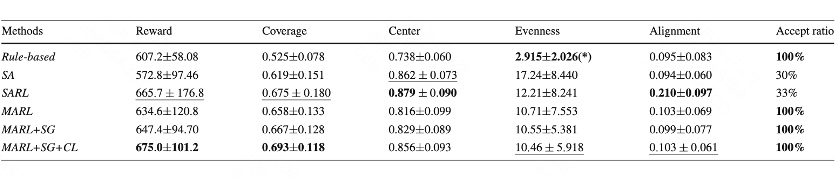
从表中可见,我们的方法综合表现最佳。其中单 agent 方法由于放置建筑时可能会与已有建筑产生冲突,从而导致无效操作,损失了方案的接受率。
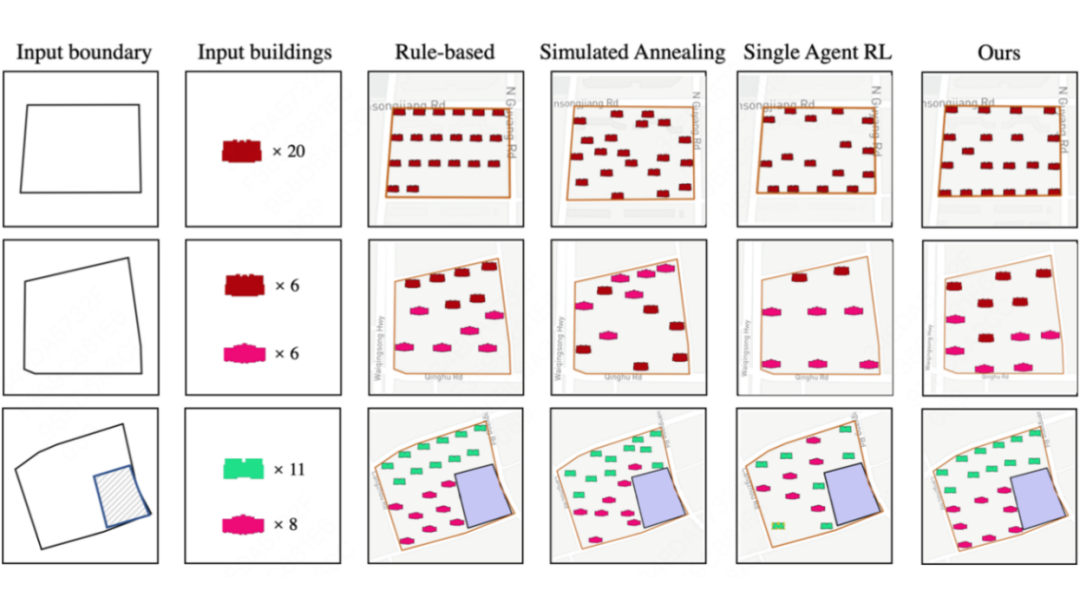
以下为在三个真实地块上将我们的方法和 baseline 生成的建筑布局可视化。基于规则的方法虽局部排列均匀但整体覆盖率低,模拟退火算法排列不够规整,单智能体强化学习因逐个尝试放置导致建筑数量与输入不符。相比之下,我们的方法在保证均匀性的同时最大化覆盖率,实现视觉平衡。

(文:PaperWeekly)