

-
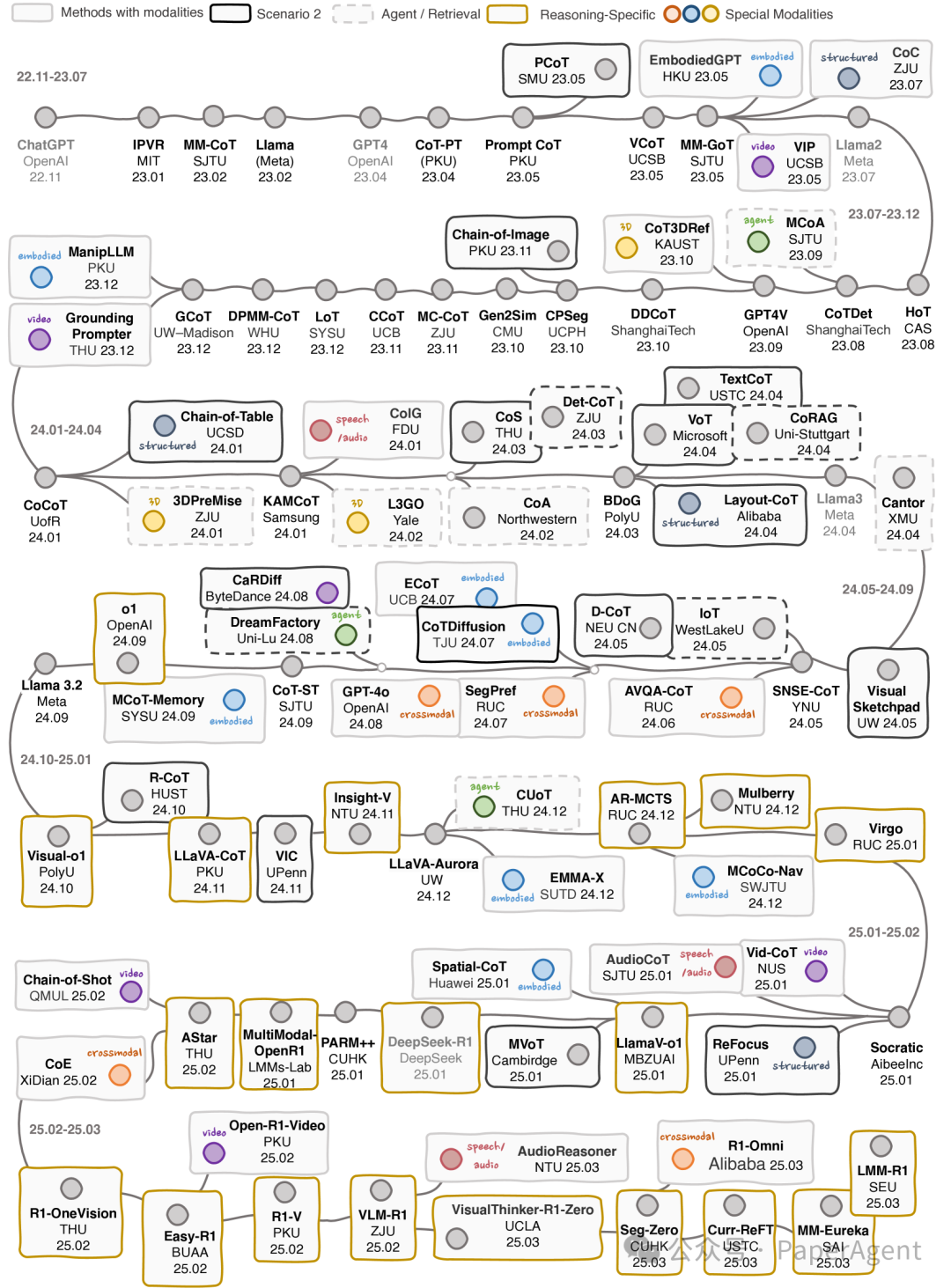
从CoT到MCoT:链式思考(CoT)推理的概念,这是一种模拟人类逐步解决问题的方法。CoT推理通过将复杂任务分解为一系列可管理的子任务来系统地构建解决方案。MCoT推理将CoT推理扩展到多模态环境中,整合了图像、视频、音频等不同模态的数据。
-
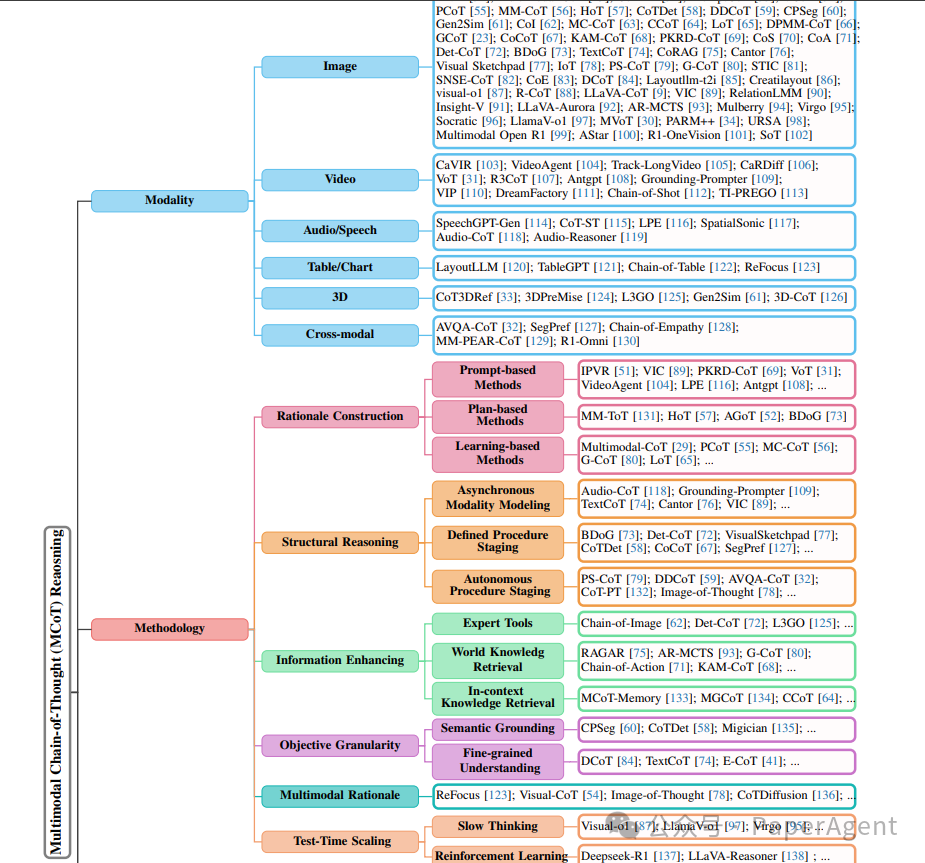
推理范式:自最初的CoT推理引入以来,已经发展出了多种推理结构或拓扑,包括链式、树式和图式。这些拓扑中的思考步骤被视为节点,节点之间的边表示它们之间的依赖关系。链式拓扑促进了线性和顺序的思考生成,而树式和图式拓扑则允许在推理过程中进行探索和回溯。

-
多模态大型语言模型(MLLMs):MLLMs的发展,这些模型能够处理和理解多模态内容,并生成文本响应。在图像-文本理解领域,已经取得了显著进展,例如BLIP2、OpenFlamingo等模型。同时,视频-文本理解和音频-语音理解也得到了关注,例如VideoChat和Qwen-Audio等模型。

详细探讨了多模态链式思考(MCoT)推理在不同模态下的应用和发展:

-
图像模态(Image):
-
MCoT推理在视觉问答(VQA)中得到了广泛应用。
-
早期实现如IPVR和Multimodal-CoT通过生成中间推理步骤来建立基础MCoT框架。
-
后续进展包括自洽性整合、动态选择推理范式、多图像理解改进等。
-
结构化推理机制被提出以增强可控性和可解释性,例如DDCoT和Socratic Questioning。
-
视频模态(Video):
-
视频理解依赖于推理能力,特别是处理长视频时的时间动态性。
-
CaVIR等实现通过零样本MCoT方法增强意图问答。
-
Video-of-Thought提出了一个五阶段框架,确保对视频内容的全面解释。
-
3D模态(3D):
-
3D场景推理涉及复杂高维数据的整合,包括形状、空间关系和物理属性。
-
3D-PreMise等框架展示了MCoT在3D生成中的有效性。
-
音频和语音模态(Audio and Speech):
-
MCoT已扩展到语音和音频处理,缩小了波形信号与语言语义之间的差距。
-
CoT-ST等方法将语音翻译分解为离散阶段,如语音识别和随后的翻译。
-
表格和图表模态(Table and Chart):
-
LLMs在处理结构化数据(如表格和图表)时面临挑战,因为它们的复杂布局和隐式模式。
-
LayoutLLM等方法通过整合布局感知预训练来推进文档理解。
-
跨模态CoT推理(Cross-modal CoT Reasoning):
-
CoT类推理也擅长整合超出文本和单一附加模态的多种模态,即跨模态CoT推理。
-
AVQA-CoT等将复杂查询分解为更简单的子问题,通过LLMs和预训练模型顺序解决音频视觉问答(AVQA)。
深入探讨了多模态链式思考(MCoT)推理的研究方法和策略:
-
推理构建视角:
-
基于提示的方法:利用精心设计的提示来引导模型在推理过程中生成推理依据,通常在零样本或少样本设置中使用。
-
基于计划的方法:允许模型在推理过程中动态探索和完善思考过程,例如通过搜索算法或辩论代理来生成推理路径。
-
基于学习的方法:在训练或微调过程中嵌入推理构建,要求模型显式学习与多模态输入相关的推理技能。
-
结构化推理视角:

-
异步模态建模:将感知和推理分开处理,以提高解释性和与人类认知过程的一致性。
-
定义过程阶段:通过明确定义结构化推理阶段来增强过程的可解释性,例如通过固定辩论-总结流程或模板化指令解析。
-
自主过程阶段:允许大型语言模型自主确定推理步骤的顺序,例如通过迭代解决子问题或自动生成任务解决计划。
-
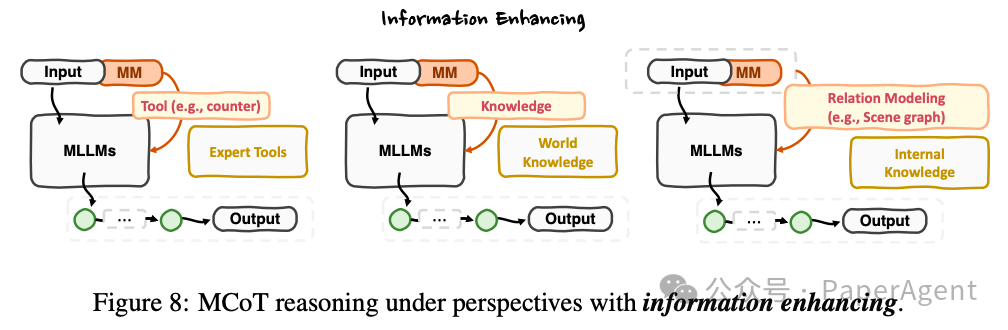
信息增强视角:
-
利用专家工具和知识检索(包括世界知识和上下文知识)来增强多模态输入,以促进全面推理。
-
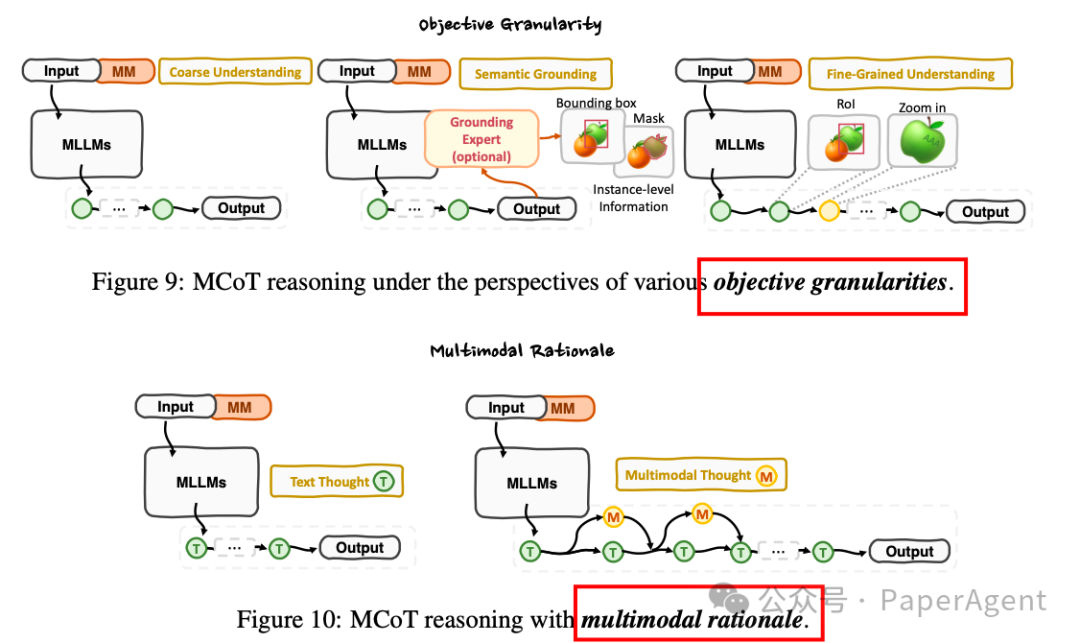
目标粒度视角:
-
研究方法通常与目标的粒度对齐,从粗粒度理解到细粒度理解和语义对齐。
-
多模态推理视角:
-
探索从文本中心到多模态推理依据的构建,模仿人类认知过程。
-
测试时扩展视角:
-
讨论了在推理过程中引入慢思考(slow thinking)和强化学习(reinforcement learning)来提高推理质量的策略。
https://arxiv.org/pdf/2503.12605Multimodal Chain-of-Thought Reasoning:A Comprehensive Surveyhttps://github.com/yaotingwangofficial/Awesome-MCoT
(文:PaperAgent)