

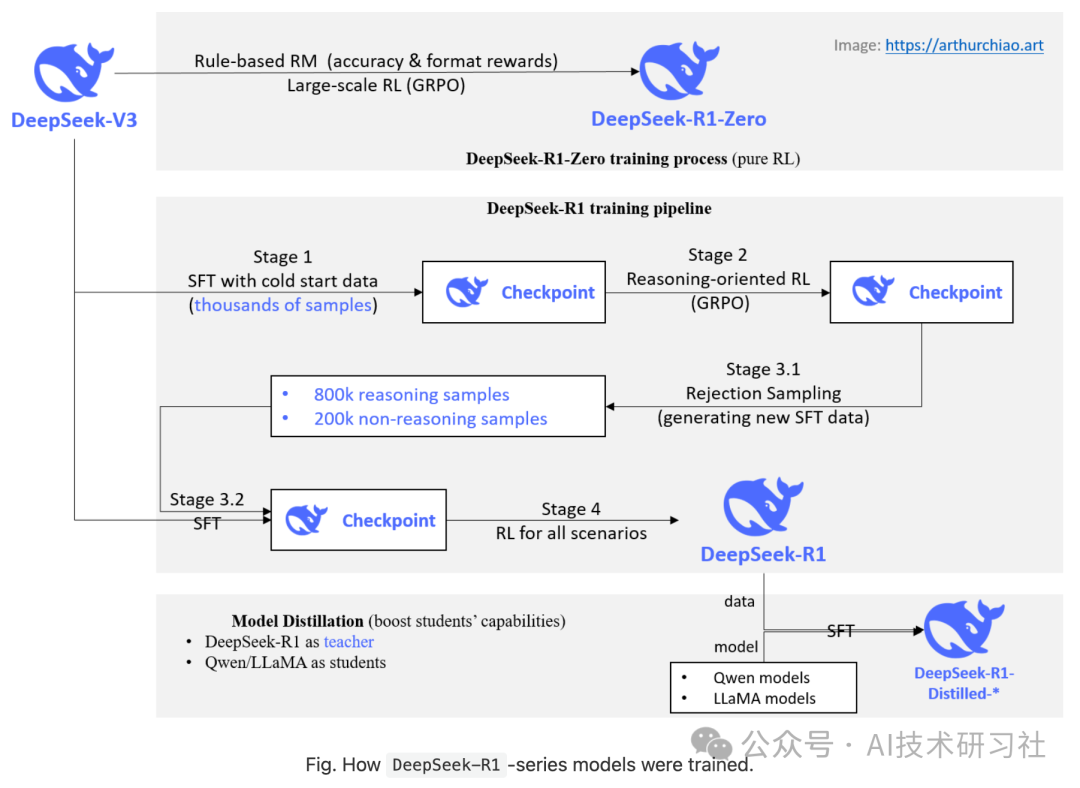

DeepSeek-R1-Zero 的创新之处在于完全跳过了 SFT 步骤, 直接在基座模型上进行大规模 RM+RL 训练,性能达到了 OpenAI-o1-0912 的水平。DeepSeek-R1, 在推理任务上的表现与 OpenAI-o1-1217 不相上下。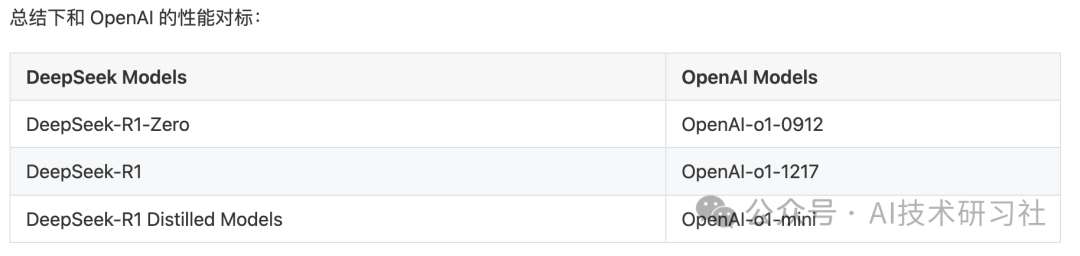
post-training:在基础模型上进行大规模强化学习
跳过监督微调(SFT)步骤,直接在基础模型(base model)上应用 RL。 这会使模型去探索解决复杂问题时的思维链(CoT),用这种方式训练得到的就是 DeepSeek-R1-Zero。
蒸馏:小型模型也可以很强大
Deep Seek证明了大型模型的推理模式可以被蒸馏到小型模型中,
利用 DeepSeek-R1 生成的推理数据,我们微调了几个在社区中广泛使用的小型 dense 模型。 结果显示,这些经过蒸馏的小型 dense model 在基准测试中表现非常好。
以往的研究重度依赖于大量的监督数据(人类标注数据)来提升模型性能。 本文的研究证明:
- 不使用监督微调(SFT),单纯通过大规模强化学习(RL)
也能显著提升推理能力。 -
通过引入少量冷启动数据(SFT 训练数据),还可以进一步增强性能。
DeepSeek-R1-Zero:在基础模型上进行强化学习
之前的研究(Wang 等,2023;Shao 等,2024)已经证明,强化学习对提高推理性能非常有用。 但是,这些前期研究都重度依赖监督数据,而收集监督数据是个费事费力的过程。
本节探索在没有任何监督数据的情况下(单纯通过 RL 过程自我进化),大模型发展出推理能力的过程。
强化学习算法:Group Relative Policy Optimization (GRPO)
为了降低 RL 训练成本,我们采用了 GRPO(组相对策略优化)算法(Shao 等,2024), 该方法放弃了 critic model(通常尺寸与 policy model 大小相同),而是用 group scores 来估计基线。
具体来说,对于每个问题q, GRPO从老的policy πθold中采样得到一组输出o1,o2,⋯,oG,然后用下面的目标函数优化 policy model πθ:

奖励建模(Reward Modeling):rule-based reward system
奖励是 training signal 的来源,它决定了强化学习的优化方向。 训练 DeepSeek-R1-Zero 时,我们采用了一个基于规则的奖励系统(rule-based reward system), 该系统主要由两种类型的奖励组成。
类型一:准确性奖励(Accuracy rewards)
准确性奖励模型评估响应是否正确(whether the response is correct)。例如,
-
对于具有确定性结果的数学问题,要求模型以指定格式提供最终答案,从而能可靠地基于规则验证正确性。 -
对于 LeetCode问题,可以使用编译器对生成的程序进行编译,然后运行预定义的测试用例。
类型二:格式奖励(Format rewards)
我们还采用了一个格式奖励模型,强制推理模型将其思考过程放在 <think> 和 </think> tag 内。
这里没有使用结果或过程神经奖励模型(outcome or process neural reward model), 因为我们发现神经奖励模型可能会在大规模强化学习过程中出现 reward hacking 行为, 并且重新训练奖励模型需要额外的训练资源,也会使整个训练流程变得更加复杂。
训练模板(提示词模板)
我们设计了一个简单直白的模板,指导基础模型遵循我们的具体指令。如表 1 所示。
A conversation between User and Assistant. The user asks a question, and the Assistant solves it.
The assistant first thinks about the reasoning process in the mind and then provides the user
with the answer. The reasoning process and answer are enclosed within <think> </think> and
<answer> </answer> tags, respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: prompt. Assistant:
表 1:DeepSeek-R1-Zero 的模板。在训练期间,将用具体的推理问题替换提示。
可以看到,这个模板要求 DeepSeek-R1-Zero 首先生产一个推理过程,然后再给出最终答案。 我们有意将约束限制在这一结构内,避免任何 content-specific biases —— 例如,mandating reflective reasoning or promoting particular problem-solving strategies —— 以确保我们能够准确地观察模型在 RL 过程中的自然进化。
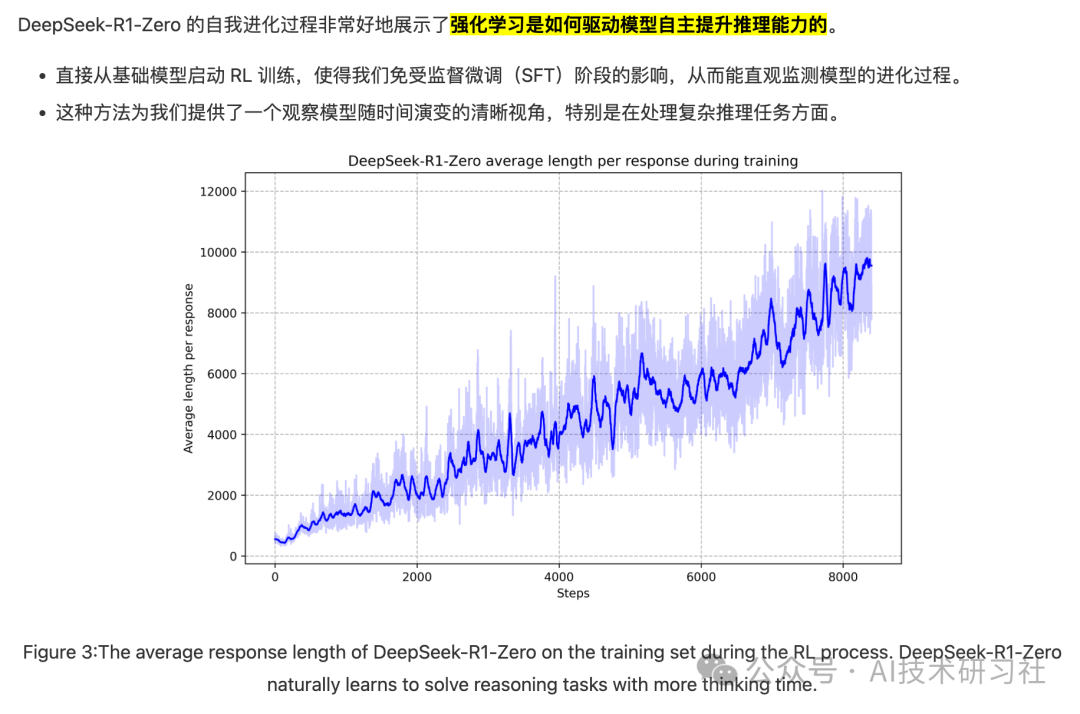

这一时刻出现在模型的一个中间版本中。在这个阶段,DeepSeek-R1-Zero 学会了通过重新评估其初始处理方法,为问题分配更多的思考时间。 这种行为不仅是模型逐步增长的推理能力的证明,也是强化学习能够带来意外且复杂结果的一个迷人例证。
这对于模型和观察其行为的研究者来说都是一个 “顿悟时刻”,它凸显了强化学习的力量和美感:
-
我们并没有明确地教导模型如何解决问题,而是仅仅提供了正确的激励,模型便能够自主地发展出高级的问题解决策略。 -
“顿悟时刻” 有力地提醒了我们 RL 激发人工智能系统新智能水平的潜力,为未来更具自主性和适应性的模型铺平了道路。
缺点和解决方式
尽管 DeepSeek-R1-Zero 展示了强大的推理能力,并且能够自主发展出意外且强大的推理行为,但它也面临一些问题。例如,DeepSeek-R1-Zero 遇到了诸如可读性差、语言混用等挑战。 为了使推理过程更具可读性,我们探索了 DeepSeek-R1。
蒸馏:赋予小型模型推理能力
为了使小型模型具备类似 DeepSeek-R1 的推理能力, 我们直接用 DeepSeek-R1 生成的 800k 样本对开源模型进行微调。
我们的研究发现,这种直接蒸馏的方法能显著提升小型模型的推理能力。 我们使用的基础模型包括:
-
Qwen2.5-Math-1.5B -
Qwen2.5-Math-7B -
Qwen2.5-14B -
Qwen2.5-32B -
Llama-3.1-8B -
Llama-3.3-70B-Instruct。选择 Llama-3.3 是因为其推理能力略优于 Llama-3.1。
蒸馏过程:在以上基础模型上进行监督微调(SFT),
-
这里不再进行强化学习(RL),尽管叠加 RL 可能会进一步提升模型性能。 -
我们的主要目的是展示蒸馏技术的有效性,叠加 RL 阶段的探索就留给更社区研究。
蒸馏与强化学习的性能对比
前面已经看到,通过蒸馏 DeepSeek-R1,小型模型可以取得非常好的效果。 但这里还有一个问题待解答:通过本文讨论的大规模 RL 对小模型训练,和蒸馏方式相比,哪个效果来的更好?
为了回答这个问题,我们在 Qwen-32B-Base 上进行了大规模 RL 训练,使用数学、编码和 STEM 数据,训练了超过 10K 步, 得到了 DeepSeek-R1-Zero-Qwen-32B。 两种方式得到的模型,性能对比如下。
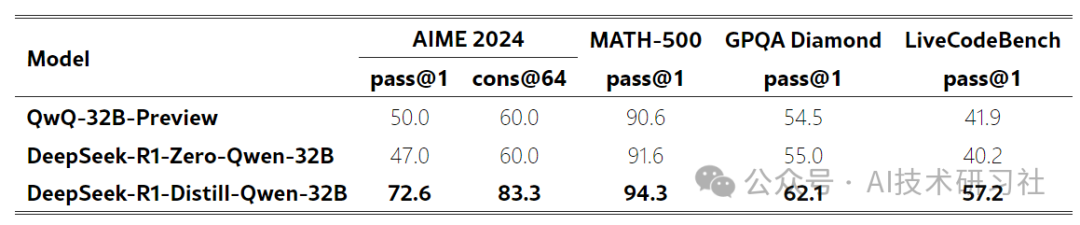
Table 6:Comparison of distilled and RL Models on Reasoning-Related Benchmarks.
-
大规模 RL 训练的 32B 基础模型,在性能上与 QwQ-32B-Preview 相当。 -
从 DeepSeek-R1 蒸馏而来的模型,在所有基准测试中都显著优于 DeepSeek-R1-Zero-Qwen-32B。
因此,我们可以得出两个结论:
- 将更强大的模型蒸馏到小型模型中,可以让小模型获得出色的性能。
对小型模型进行大规模 RL 也能取得不错的性能,但需要的算力比蒸馏要多很多,而且可能无法达到蒸馏取得的效果。 -
蒸馏是一种既经济又高效的方式,但要突破智能边界,可能仍需要更强大的基础模型和更大规模的强化学习。
(文:AI技术研习社)