


极市导读
本文提供了从零开始构建 Mamba 的全部代码过程,作者将Mamba算法模型从理论转化为具体实践。这一探索过程不仅可以巩固对 Mamba 内部工作原理的理解,而且还展示了新颖算法模型架构的实际设计步骤。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
在深度学习领域,序列建模仍然是一项具有挑战性的任务,通常由 LSTM 和 Transformers 等模型来解决。然而,这些模型的计算量很大,因此在实际应用场景中,这些模型方法仍存在巨大的缺陷。而Mamba 是一个线性时间序列建模框架,其旨在提高序列建模的效率和有效性。本文将深入探讨使用 PyTorch 实现 Mamba 的过程,解码这一创新方法背后的技术问题和代码。

1.1 Transformer:
Transformer因其注意机制而闻名。借助于Transformer操作特性,特征序列中的任何部分都可以与其他部分进行动态交互,尤其是因果注意力特征,能够很好的捕获因果特征的信息。因此,Transformer能够处理好序列中的每一个元素,相应的,Transformer的计算代价和内存成本也都很高,与序列长度(L²)的平方成正比。
1.2 递归神经网络(RNN):
RNN 是按照序列顺序更新隐藏状态,它只考虑当前输入特征和上一个隐藏状态信息。这种方法允许它们以恒定的内存成本处理无限长的序列。然而,RNN 的简单性也变相的成为一个缺点,即限制了其记忆长期依赖关系的能力。此外,尽管有 LSTM 这样的创新,RNN 中的时间反向传播(BPTT)机制可能会占用大量内存,并可能出现梯度消失或爆炸的问题。
1.3.状态空间模型(S4):
状态空间模型具有良好的特性。它们提供了一种计算代价和内存成本的平衡,比 RNNs 更有效地捕捉长程依赖性,同时比 Transformers 更节省内存。
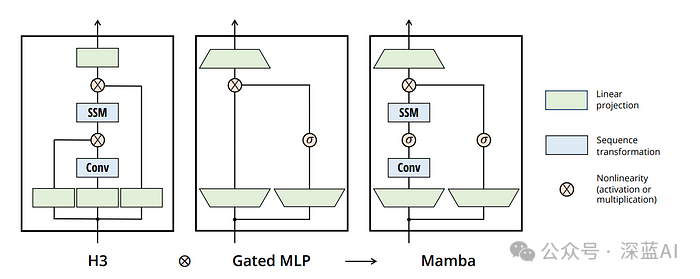
1.4.Mamba架构的方法思路:
●选择性状态空间:Mamba 以状态空间模型的概念为基础,引入了一种新的模型架构设计思路。它利用选择性状态空间,能更高效、更有效地捕捉长序列中的相关信息。
●线性时间复杂性:与Transformers不同,Mamba的运行时间与序列长度成线性关系。这一特性使其特别适用于超长序列的任务,而传统的模型在这方面会很吃力。
Mamba 通过其 “选择性状态空间”(Selective State Spaces)的概念,为传统的状态空间模型引入了一个新颖的架构。这种方法稍微放宽了标准状态空间模型的僵化状态转换,使其更具适应性和灵活性,有点类似于 LSTM。不过,Mamba 保留了状态空间模型的高效计算特性,使其能够一次性完成整个序列的前向传递。

2.1导入必须的库文件
在简单介绍完Mamba架构之后,为大家带来Mamba的代码实现过程,首先导入必须的库。
# PyTorch相关的库
import torchimport torch.nn as nn
import torch.optim as optim
from torch.utils.data
import DataLoader, Dataset
from torch.nn
import functional as Ffrom einops
import rearrangefrom tqdm
import tqdm
# 系统相关的库
import mathimport os
import urllib.request
from zipfile import ZipFile
from transformers
import AutoTokenizer
torch.autograd.set_detect_anomaly(True)
2.2 设置标识和训练设备
这里主要针对是否使用GPU,以及Mamba的选择设定对应的表示、以及所使用的设备。
# 配置标识和超参数
USE_MAMBA =1
DIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM =0
# 设定所用设备
device = torch.device('cuda'if torch.cuda.is_available() else'cpu')
←左右滑动查看完整代码→
2.3 设置初始化超参数
这一小节定义了模型维度(d_model)、状态大小、序列长度和批次大小等超参数。
# 人为定义的超参数
d_model =8
state_size =128 # 状态大小
seq_len =100 # 序列长度
batch_size =256 # 批次大小
last_batch_size =81 # 最后一个批次大小
current_batch_size = batch_size
different_batch_size =False
h_new =None
temp_buffer =None
2.4 定义S6模块
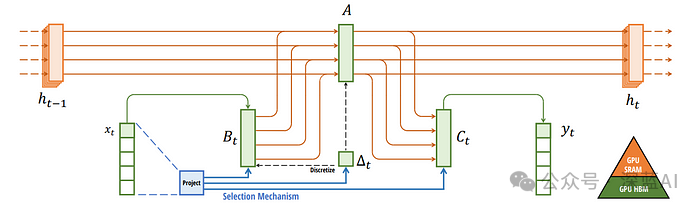
S6 模块是 Mamba 架构中的一个复杂组件,它主要由一系列线性变换和离散化过程组成,用于处理输入的特征序列。它在捕捉序列的时间动态特征方面起着至关重要的作用,而时间动态特征是语言建模等序列建模任务的一个关键方面。
# 定义S6模块
class S6(nn.Module):
def__init__(self, seq_len, d_model, state_size, device):
super(S6, self).__init__()
# 一系列线性变换
self.fc1 = nn.Linear(d_model, d_model, device=device)
self.fc2 = nn.Linear(d_model, state_size, device=device)
self.fc3 = nn.Linear(d_model, state_size, device=device)
# 设定一些超参数
self.seq_len = seq_len
self.d_model = d_model
self.state_size = state_size self.A = nn.Parameter(F.normalize(torch.ones(d_model, state_size, device=device), p=2, dim=-1))
# 参数初始化
nn.init.xavier_uniform_(self.A)
self.B = torch.zeros(batch_size, self.seq_len, self.state_size, device=device)
self.C = torch.zeros(batch_size, self.seq_len, self.state_size, device=device)
self.delta = torch.zeros(batch_size, self.seq_len, self.d_model, device=device)
self.dA = torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
self.dB = torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
# 定义内部参数h和y
self.h = torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
self.y = torch.zeros(batch_size, self.seq_len, self.d_model, device=device)
# 离散化函数
def discretization(self):
# 离散化函数定义介绍在Mamba论文中的28页 self.dB = torch.einsum("bld,bln->bldn", self.delta, self.B)
#dA = torch.matrix_exp(A * delta) # matrix_exp() only supports square matrix
self.dA = torch.exp(torch.einsum("bld,dn->bldn", self.delta, self.A)) #print(f"self.dA.shape = {self.dA.shape}") #print(f"self.dA.requires_grad = {self.dA.requires_grad}")
returnself.dA, self.dB
# 前行传播
def forward(self, x):
# 参考Mamba论文中算法2
self.B =self.fc2(x)
self.C =self.fc3(x)
self.delta = F.softplus(self.fc1(x))
# 离散化
self.discretization()
ifDIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM:
# 如果不使用'h_new',将触发本地允许错误
global current_batch_size
current_batch_size = x.shape[0]
ifself.h.shape[0] != current_batch_size
different_batch_size =True
# 缩放h的维度匹配当前的批次
h_new = torch.einsum('bldn,bldn->bldn', self.dA, self.h[:current_batch_size, ...]) + rearrange(x, "b l d -> b l d 1") *self.dB
else:
different_batch_size =False
h_new = torch.einsum('bldn,bldn->bldn', self.dA, self.h) + rearrange(x, "b l d -> b l d 1") *self.dB
# 改变y的维度
self.y = torch.einsum('bln,bldn->bld', self.C, h_new)
# 基于h_new更新h的信息
global temp_buffer
temp_buffer = h_new.detach().clone() ifnotself.h.requires_grad else h_new.clone()
returnself.y
else:
# 将会触发错误
# 设置h的维度
h = torch.zeros(x.size(0), self.seq_len, self.d_model, self.state_size, device=x.device)
y = torch.zeros_like(x)
h = torch.einsum('bldn,bldn->bldn', self.dA, h) + rearrange(x, "b l d -> b l d 1") *self.dB
# 设置y的维度
y = torch.einsum('bln,bldn->bld', self.C, h)
return y
←左右滑动查看完整代码→
S6 模块继承于 nn.Module,是 Mamba 算法模型的关键部分,负责处理离散化过程和前向传播。
2.5 定义MambaBlock模块
MambaBlock 模块是一个定制的神经网络模块,是 Mamba 模型的关键部件,它封装了处理输入数据的多个网络层和操作函数。MambaBlock 模块代表一个复杂的神经网络模块,包括线性投影、卷积、激活函数、自定义 S6 模块和残差连接。该模块是 Mamba 模型的基本组成部分,通过一系列转换处理输入序列,以捕捉数据中的相关模式和特征。这些不同网络层和操作函数的组合使 MambaBlock 能够有效处理复杂的序列建模任务。
# 定义MambaBlock模块
class MambaBlock(nn.Module):
def__init__(self, seq_len, d_model, state_size, device):
super(MambaBlock, self).__init__()
self.inp_proj = nn.Linear(d_model, 2*d_model, device=device)
self.out_proj = nn.Linear(2*d_model, d_model, device=device)
# 残差连接
self.D = nn.Linear(d_model, 2*d_model, device=device)
# 设置偏差属性
self.out_proj.bias._no_weight_decay =True
# 初始化偏差
nn.init.constant_(self.out_proj.bias, 1.0)
# 初始化S6模块
self.S6 = S6(seq_len, 2*d_model, state_size, device)
# 添加1D卷积
self.conv = nn.Conv1d(seq_len, seq_len, kernel_size=3, padding=1, device=device)
# 添加线性层
self.conv_linear = nn.Linear(2*d_model, 2*d_model, device=device)
# 正则化
self.norm = RMSNorm(d_model, device=device)
# 前向传播
def forward(self, x):
# 参考Mamba论文中的图3
x =self.norm(x)
x_proj =self.inp_proj(x)
# 1D卷积操作
x_conv =self.conv(x_proj)
x_conv_act = F.silu(x_conv) # Swish激活
# 线性操作
x_conv_out =self.conv_linear(x_conv_act)
# S6模块操作
x_ssm =self.S6(x_conv_out)
x_act = F.silu(x_ssm) # Swish激活
# 残差连接
x_residual = F.silu(self.D(x))
x_combined = x_act * x_residual
x_out =self.out_proj(x_combined)
return x_out
←左右滑动查看完整代码→
MambaBlock 模块是另一个封装了 Mamba 核心功能的模块,包括输入投影、一维卷积和 S6 模块。
2.6 定义Mamba模型
Mamba 类代表 Mamba 模型的整体架构,由一系列 MambaBlock 模块组成。每个模块负责处理输入的序列数据,一个模块的输出作为下一个模块的输入。这种顺序处理使模型能够捕捉输入数据中的复杂模式和关系,从而有效地完成顺序建模的任务。多个模块的堆叠是深度学习架构中常见的设计,因为它能让模型学习数据的分层表示特征。
# 定义Mamba模型
class Mamba(nn.Module):
def__init__(self, seq_len, d_model, state_size, device):
super(Mamba, self).__init__()
self.mamba_block1 = MambaBlock(seq_len, d_model, state_size, device)
self.mamba_block2 = MambaBlock(seq_len, d_model, state_size, device)
self.mamba_block3 = MambaBlock(seq_len, d_model, state_size, device)
def forward(self, x):
x =self.mamba_block1(x)
x =self.mamba_block2(x)
x =self.mamba_block3(x)
return x
←左右滑动查看完整代码→
该类定义了整个 Mamba 模型,将多个 MambaBlock 模块链接在一起,构成整体算法模型的架构。
2.7 定义RMSNorm模块
RMSNorm 模块是一个自定义的归一化层,继承了 PyTorch 的 nn.Module。该层用于对神经网络的激活值进行归一化操作,这有助于加快训练速度。
class RMSNorm(nn.Module):
def__init__(self,
d_model: int,
eps: float=1e-5,
device: str='cuda'):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(d_model, device=device))
def forward(self, x):
output = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) +self.eps) *self.weight
return output
←左右滑动查看完整代码→
RMSNorm 模块是用于归一化的均方根网络层,是神经网络架构中的一种常用技术。

本节介绍如何在简单的数据样本上实例化和使用 Mamba 算法模型。
# 创建模拟数据
x = torch.rand(batch_size, seq_len, d_model, device=device)
# 创建Mambda算法模型
mamba = Mamba(seq_len, d_model, state_size, device)
# 定义rmsnorm模块
norm = RMSNorm(d_model)
x = norm(x)
# 前向传播
test_output = mamba(x)
print(f"test_output.shape = {test_output.shape}")
3.1数据准备和训练函数
Enwiki8Dataset 类是一个自定义数据集处理程序,它继承自 PyTorch 的 Dataset 类,专门用于为序列建模任务(如语言建模)而构建的数据集。
# 定义填充函数
def pad_sequences_3d(sequences, max_len=None, pad_value=0):
# 获得张量的维度大小
batch_size, seq_len, feature_size = sequences.shape
if max_len isNone:
max_len = seq_len +1
# 初始化 padded_sequences
padded_sequences = torch.full((batch_size, max_len, feature_size), fill_value=pad_value, dtype=sequences.dtype, device=sequences.device)
# 填充每个序列
padded_sequences[:, :seq_len, :] = sequences
return padded_sequences
←左右滑动查看完整代码→
train 函数用于训练 Mamba 算法模型。
def train(model, tokenizer, data_loader, optimizer, criterion, device, max_grad_norm=1.0, DEBUGGING_IS_ON=False):
●model(模型):要训练的神经网络模型(本例中为 Mamba);
●tokenizer:处理输入数据的标记符;
●data_loader:数据加载器,一个可迭代器,用于为训练提供成批数据;
●optimizer: 优化器:用于更新模型权重的优化算法;
●criterion:用于评估模型性能的损失函数;
●设备:模型运行的设备(CPU 或 GPU);
●max_grad_norm:用于梯度剪切的值,以防止梯度爆炸;
●DEBUGGING_IS_ON:启用调试信息的标志。
# 定义train函数def train(model, tokenizer, data_loader, optimizer, criterion, device, max_grad_norm=1.0, DEBUGGING_IS_ON=False):
model.train()
total_loss =0
for batch in data_loader:
optimizer.zero_grad()
input_data = batch['input_ids'].clone().to(device)
attention_mask = batch['attention_mask'].clone().to(device)
# 获取输入数据和标签
target = input_data[:, 1:]
input_data = input_data[:, :-1]
# 填充序列数据
input_data = pad_sequences_3d(input_data, pad_value=tokenizer.pad_token_id)
target = pad_sequences_3d(target, max_len=input_data.size(1), pad_value=tokenizer.pad_token_id)
if USE_MAMBA:
output = model(input_data)
loss = criterion(output, target)
loss.backward(retain_graph=True)
# 裁剪梯度
for name, param in model.named_parameters():
if'out_proj.bias'notin name:
# 裁剪梯度函数操作
torch.nn.utils.clip_grad_norm_(param, max_norm=max_grad_norm)
if DEBUGGING_IS_ON:
for name, parameter in model.named_parameters():
if parameter.grad isnotNone:
print(f"{name} gradient: {parameter.grad.data.norm(2)}")
else:
print(f"{name} has no gradient")
if USE_MAMBA and DIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM:
model.S6.h[:current_batch_size, ...].copy_(temp_buffer)
optimizer.step()
total_loss += loss.item()
return total_loss /len(data_loader)
←左右滑动查看完整代码→
3.2 模型训练循环
# 输入预训练模型权重
encoded_inputs_file ='encoded_inputs_mamba.pt'
if os.path.exists(encoded_inputs_file):
print("Loading pre-tokenized data...")
encoded_inputs = torch.load(encoded_inputs_file)
else:
print("Tokenizing raw data...")
enwiki8_data = load_enwiki8_dataset()
encoded_inputs, attention_mask = encode_dataset(tokenizer, enwiki8_data)
torch.save(encoded_inputs, encoded_inputs_file)
print(f"finished tokenizing data")
# 组合数据data = {
'input_ids': encoded_inputs,
'attention_mask': attention_mask
}
# 分割训练和验证集total_size =len(data['input_ids'])
train_size =int(total_size *0.8)
train_data = {key: val[:train_size] for key, val in data.items()}
val_data = {key: val[train_size:] for key, val in data.items()}
train_dataset = Enwiki8Dataset(train_data)
val_dataset = Enwiki8Dataset(val_data)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
# 初始化模型
model = Mamba(seq_len, d_model, state_size, device).to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=5e-6)
# 训练次数
num_epochs =25
for epoch in tqdm(range(num_epochs)):
train_loss = train(model, tokenizer, train_loader, optimizer, criterion, device, max_grad_norm=10.0, DEBUGGING_IS_ON=False)
val_loss = evaluate(model, val_loader, criterion, device)
val_perplexity = calculate_perplexity(val_loss)
print(f'Epoch: {epoch+1}, Training Loss: {train_loss:.4f}, Validation Loss: {val_loss:.4f}, Validation Perplexity: {val_perplexity:.4f}')
←左右滑动查看完整代码→
上述代码是建立和训练 Mamba 模型的详细示例过程,包括数据集的组合和划分,模型的定义和初始化,以及损失函数和优化器的定义,最后则是设定训练循环的次数。

本文提供了从零开始构建 Mamba 的全部代码过程,读者们可以借助本文的讲解和代码,将Mamba算法模型从理论转化为具体实践。这一探索过程不仅可以巩固对 Mamba 内部工作原理的理解,而且还展示了新颖算法模型架构的实际设计步骤。通过这种实践方法,笔者发现了序列建模的细微差别以及 Mamba 在这一领域引入的效率。有了这些知识,笔者现在就可以在自己的项目中更好地尝试使用 Mamba,或更深入地开发新型的AI模型。
参考:
【1】https://arxiv.org/abs/2312.00752
【2】https://github.com/state-spaces/mamba
【3】https://pytorch.org/tutorials/beginner/basics/data_tutorial.html
【4】https://huggingface.co/datasets/enwik8
(文:极市干货)