


大语言模型(如GPT-4)在训练阶段“吃”了大量数据和算力,但实际使用时常常表现得像“考试临时抱佛脚”——面对复杂问题容易卡壳。
论文:What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models
链接:https://arxiv.org/pdf/2503.24235
今天的一篇arxiv对Test-Time Scaling(TTS)的survey,TTS就像给LLM装上一个“深度思考开关”,允许它在回答问题时动态分配更多计算资源,通过反复推敲、多路径试错来提升表现。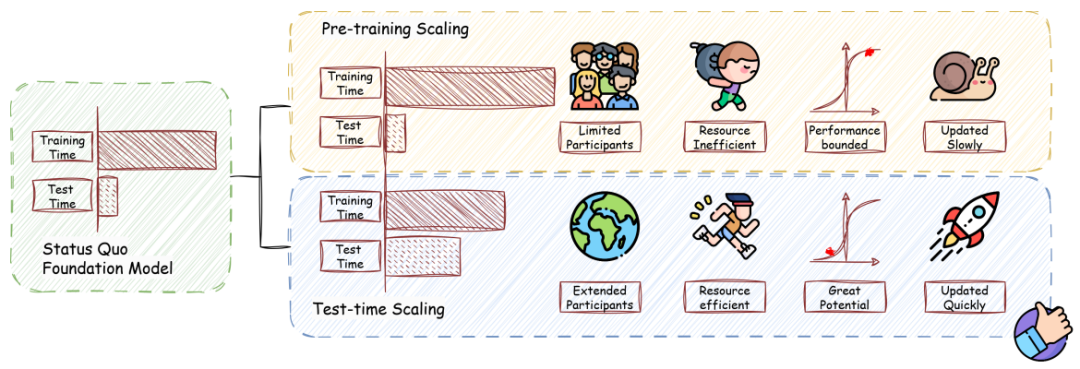 例如,让LLM解数学题时,不再一次性输出答案,而是像人类一样先写草稿、检查步骤,甚至尝试不同解法,最终选出最优解。
例如,让LLM解数学题时,不再一次性输出答案,而是像人类一样先写草稿、检查步骤,甚至尝试不同解法,最终选出最优解。
核心框架:四维视角拆解TTS的底层逻辑
论文用四大问题构建TTS的全景图:
-
What:扩展什么?(生成更多答案?优化单条推理链?) -
How:如何实现?(调整模型参数?动态搜索策略?) -
Where:用在哪些任务?(数学、编程、开放问答?) -
How Well:效果如何衡量?(准确率、效率、可控性?)
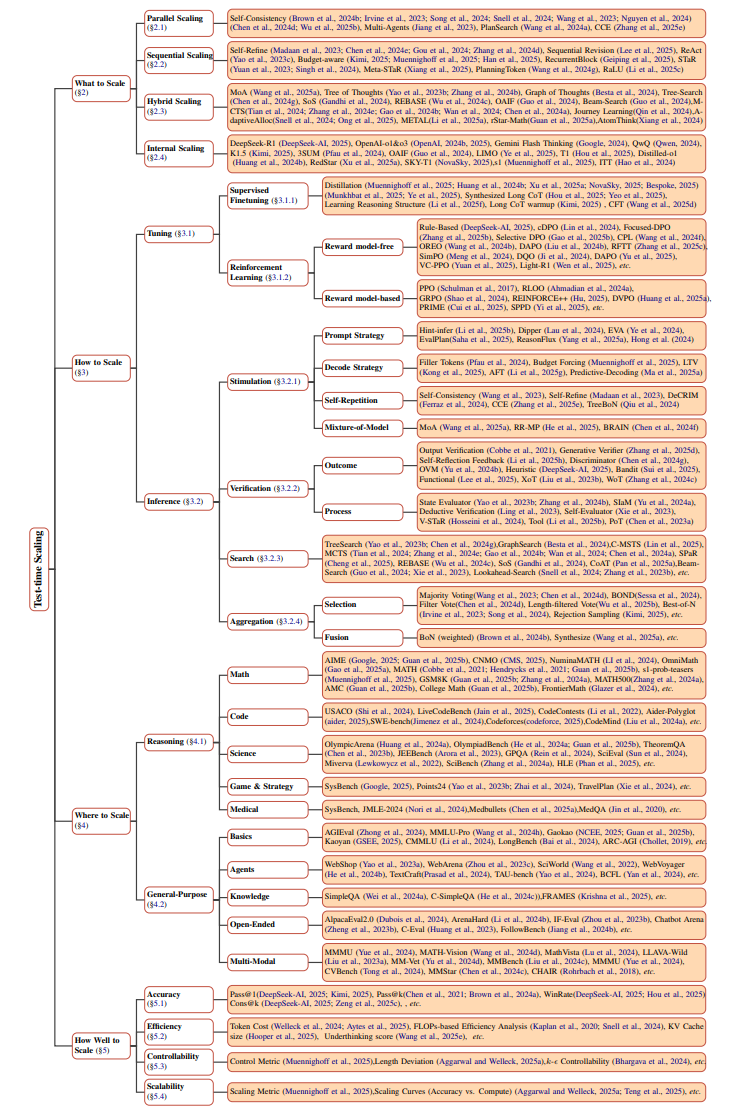
这就像给AI开发者的“操作手册”,告诉他们在不同场景下该按哪个按钮提升性能。
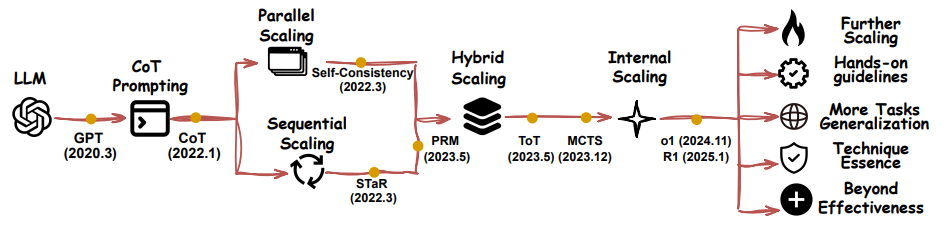
技术方法:从“暴力枚举”到“自动驾驶式推理”
-
暴力流:生成N个答案,投票选出最佳(类似“集思广益”) -
迭代流:让AI自我纠错,像写论文反复修改草稿 -
混合流:结合以上两种,先广撒网再深挖潜力股 -
黑盒流:直接训练模型自主决定“想多久”,无需人工干预
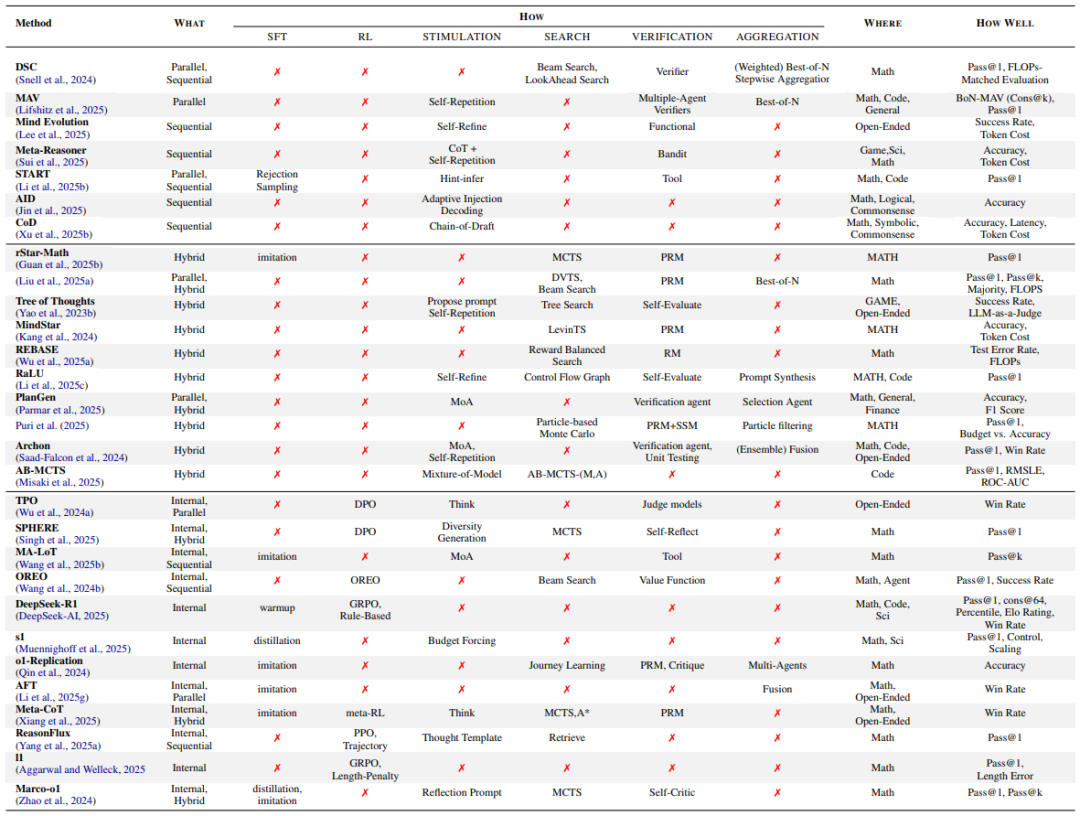
例如,蒙特卡洛树搜索(MCTS) 让AI像下围棋一样预判多步,而内部扩展则像给AI装上“自动驾驶”,自动分配算力。
应用场景:数学、编程、医疗……TTS如何改变行业?
-
数学:国际奥赛题准确率提升30%+ -
编程:生成代码后自动运行测试,筛选可通过版本 -
医疗:模拟医生会诊,多角度验证诊断结论 -
开放问答:生成10版回答,选最符合人类价值观的
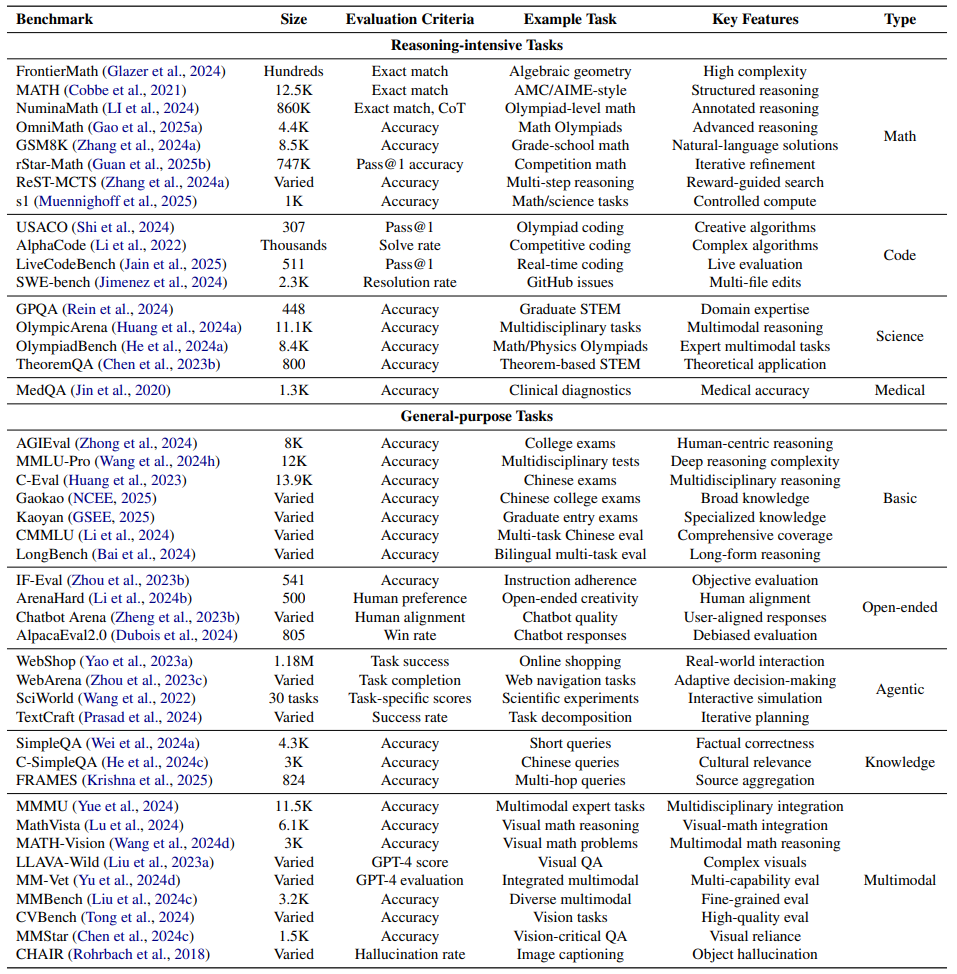
论文列出的50+个测评集(如MATH、Codeforces)显示,TTS已在专业领域展现颠覆潜力。
效果评估:如何衡量大模型“烧脑”后的进步?
-
准确率:基础指标,但可能存在“过度思考” -
效率:每提升1%准确率,需要多消耗多少算力? -
可控性:能否让AI在指定时间内完成推理? -
扩展性:算力翻倍时,性能是否线性增长?
例如,某些方法在数学题上“烧”10倍算力后,准确率从60%飙到85%,但再增加算力却收效甚微——找到性价比甜点至关重要。
未来挑战:TTS的边界与AI进化的下一站
-
算力天花板:无限堆计算资源是否可持续? -
本质理解:TTS为何有效?是“真智能”还是“暴力美学”? -
跨界通用:如何让医疗领域的TTS策略适用于法律咨询? -
伦理风险:若AI通过“无限烧脑”绕过人类控制怎么办? -
论文预言:未来的AI可能像人类一样,在“直觉反应”和“深度思考”间自由切换,甚至发展出独特的推理风格。
(文:机器学习算法与自然语言处理)