


在近期关于大规模模型与数据规模极限的讨论中,OpenAI 的 Ilya Sutskever 以及 微软研究院的 Shital Shah 都提出了一个值得关注的观点:随着模型不断扩张,数据的质量与多样性会逐渐成为训练的瓶颈,传统的预训练范式可能走向终结。
Ilya Sutskever 在演讲中直言“预训练(as we know it)将会终结”,暗示需要全新的思路来拓展数据边界。Shital Shah 则在社交媒体上更是指出,真实数据的高质量部分是有限的,继续简单堆砌相似数据并不能突破“质量上限”,而合成数据(synthetic data)的潜力尚未被充分发掘。
基于这一背景,今天的arxiv, 一篇关于多模态foundation model构建的文章首次验证了该想法。
 论文:Will Pre-Training Ever End? A First Step Toward Next-Generation Foundation MLLMs via Self-Improving Systematic Cognition
论文:Will Pre-Training Ever End? A First Step Toward Next-Generation Foundation MLLMs via Self-Improving Systematic Cognition
链接:https://arxiv.org/abs/2503.12303
当前多模态大模型(如GPT-4、LLaVA)依赖海量高质量数据预训练,但现实世界的高质量图文数据即将耗尽。鉴于此,当前的大部分工作关注在如何通过增强推理优化或微调(如RL fine-tuning)来增强model的泛化能力,从而促进model self-improvement。但是近期工作发现这种提高非常依赖基座模型预训练阶段获得的能力,不同模型的self-improvement差异巨大。就像不教学习方法、只让学生“刷题”,遇到新题型仍难以应对。
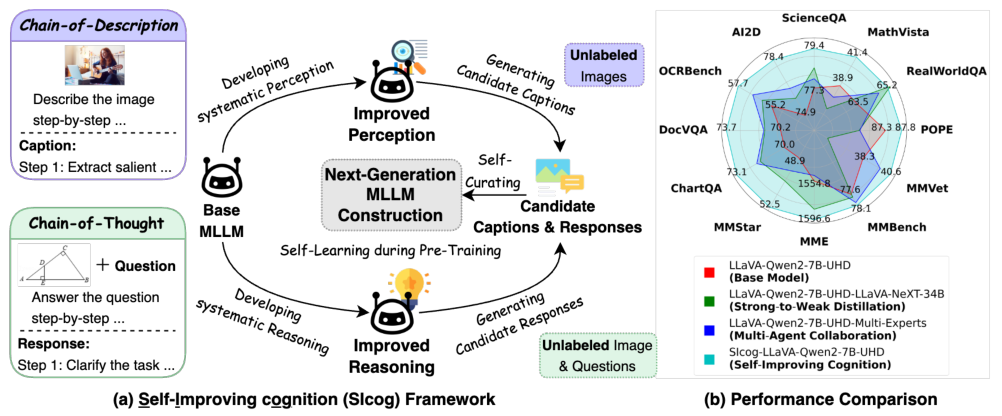
论文指出,模型进步需要预训练、推理优化、微调三者的深度协同,而SICOG框架正是这一理念的实践者。
核心创新:模型进步需要三位一体的协同
SICOG:让模型学会“自我进化”

-
描述链(Chain-of-Description, CoD)模型像侦探一样分步骤观察图像,从主体到细节,从关系到背景。例如,对于一张女孩弹吉他的图像,传统方法可能只说“女生在弹吉他”;而 CoD 会分层次描述: -
一位红发女性坐在床上,怀中抱着一把木吉他(人物姿势与主物体清晰可见); -
吉他为浅色指板的经典木制款式,光线柔和渲染出温暖氛围(细节层面); -
她坐在床上,笔记本放在小桌上,灯串和挂饰布置在背景中(元素关系); -
房间有梳妆台、墙面装饰等(边缘信息未被忽略); -
最终生成一段完整描述:女生盘腿坐在床上练琴,环境温馨,专注神情清晰可见。
这种方式让模型“看图像像人一样”,从细节到整体,提升感知质量。
-
结构化解题思路(Structured Chain-of-Thought, CoT)面对复杂问题,模型进行多步推理: -
拆解任务 → 提取关键信息 → 步步推理 → 总结答案 例如在一个几何题中,传统方法可能直接猜答案,而 CoT 会分步进行: -
明确目标是求三角形某边长; -
从图中识别出直角三角形、垂直线段、边长数据; -
判断相似三角形关系,列出比例公式,代入计算; -
得出最终答案为 C 选项。 这种方式让模型“解题像学霸一样”,通过层层推理得出准确结论。
持续自我迭代:让模型自己教自己,持续提升
-
用少量标注数据教模型基础能力 -
让模型给未标注数据生成候选答案 -
通过“投票机制”筛选优质答案(自我一致性) -
用筛选后的数据重新预训练,持续进化
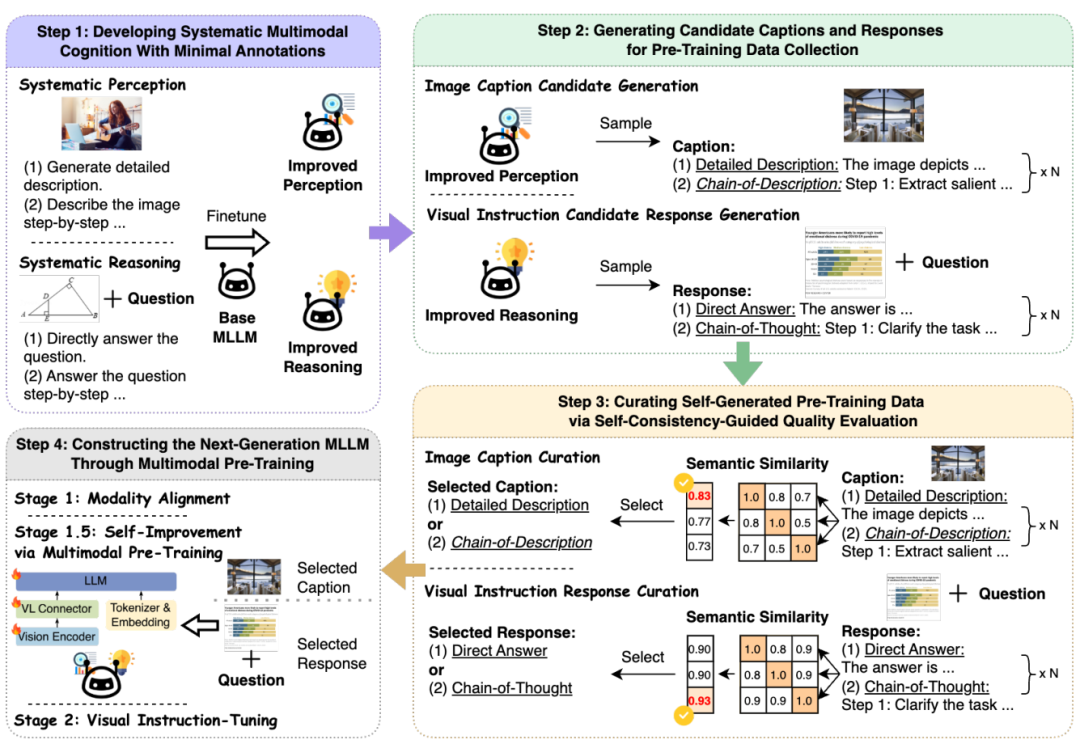
实验结果:模型能力全面提升
论文在12个主流测评集(涵盖图表理解、数学推理、抗幻觉等)中验证SICOG的效果:
-
综合能力提升2-4%,尤其在需要深度推理的任务(如ScienceQA)优势明显 -
抗幻觉能力增强,错误率降低1-2%(如POPE测评) -
数据越多表现越好,自产数据量从11.8万增至21.3万时,模型性能持续增长 这种方法的表现甚至超过了主流的strong-to-weak distillation, multi-agent collaboration的方法
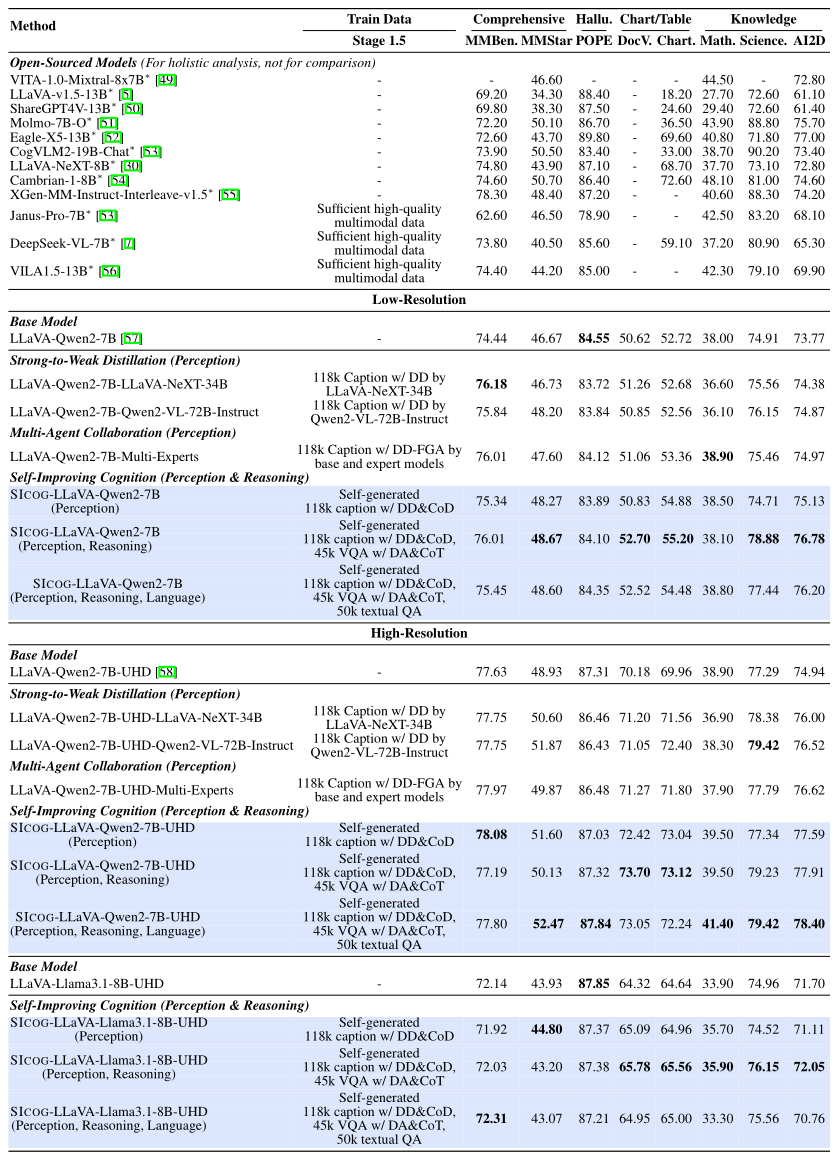
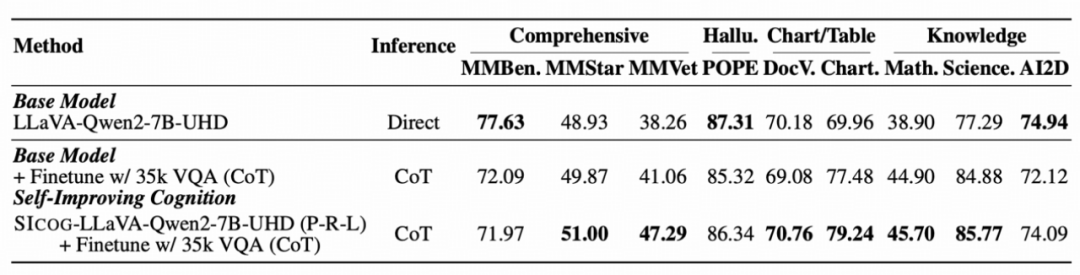
而且作者还验证了这种通过合成数据进行多模态预训练的方法也同样遵循scaling law。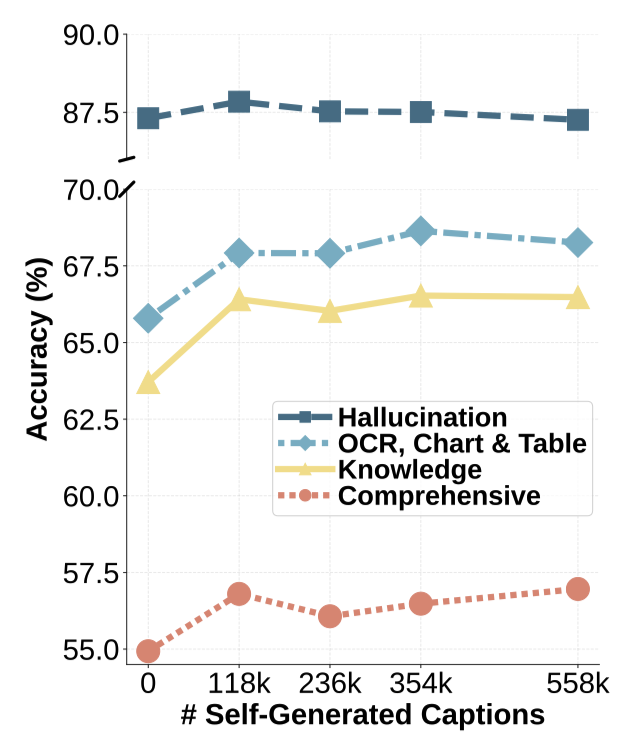 更有趣的是,基础越强的模型自我进化越快,类似“学霸更会自学”。实验显示,强基模型LLaVA-Qwen2-7B-UHD比普通模型LLaVA-Llama3.1-8B-UHD提升幅度高50%。
更有趣的是,基础越强的模型自我进化越快,类似“学霸更会自学”。实验显示,强基模型LLaVA-Qwen2-7B-UHD比普通模型LLaVA-Llama3.1-8B-UHD提升幅度高50%。
作者还提出了一个变体方法:用偏好学习(Preference Learning)替代传统的监督微调(SFT),进一步提升模型基础能力。
实验表明:
-
在所有测试集上表现更优; -
Preference Learning 比 SFT 更能增强模型泛化性; -
也印证了“强化学习优于 SFT”这一长期假设。 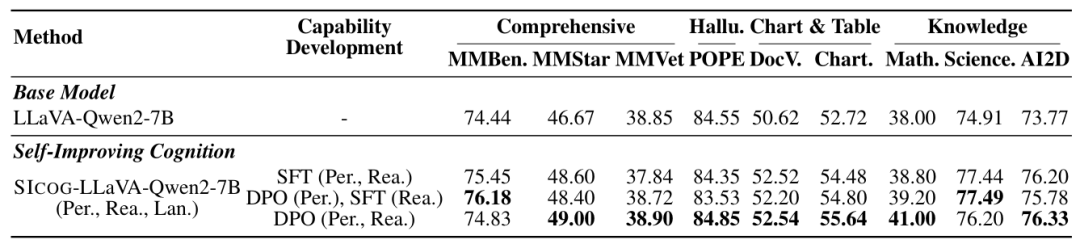

未来展望:迈向真正的“自主学习”模型
SICOG首次实现了“数据自产-训练-能力提升”的完整闭环,打破了传统AI依赖人工标注的瓶颈。这种类人的认知发展模式,让模型从“被动学习”转向“主动进化”。未来,结合人类反馈(如偏好学习),模型可能实现真正的终身学习。
(文:机器学习算法与自然语言处理)