DeepSeek联合清华发布了最新研究成果:通用奖励模型的推理时可扩展性,探讨了如何通过更多的推理计算来改进通用查询的奖励建模(RM),以及如何通过适当的学习方法提高性能与计算扩展的有效性。
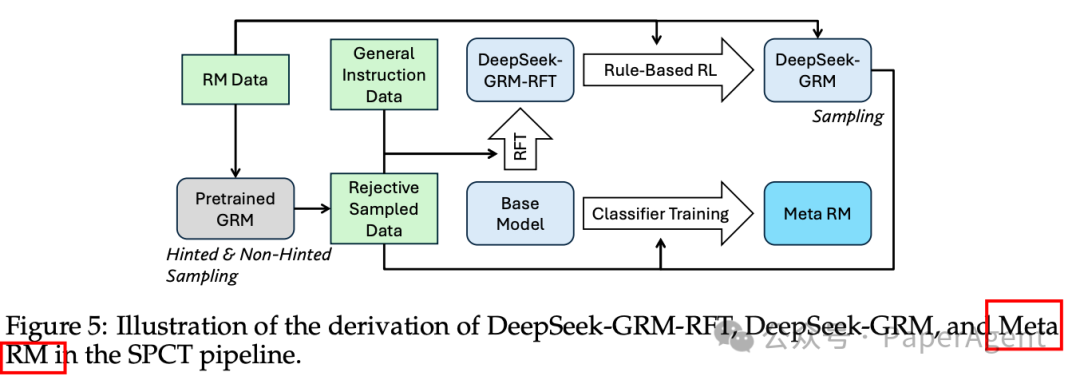
DeepSeek分三步走解决上述问题,并产生了DeepSeek-GRM模型:DeepSeek-GRM-27B能够达到与671B参数模型(DeepSeek V3/R1)相当的性能:
-
在奖励建模方法上,采用点式生成奖励建模(Pointwise Generative Reward Modeling, GRM),它允许模型为不同类型的输入生成奖励信号,并具有推理时可扩展的潜力。
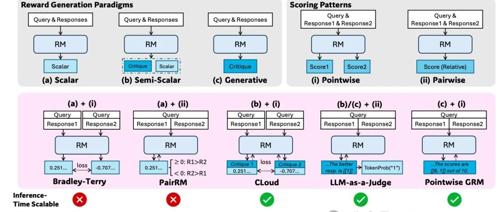
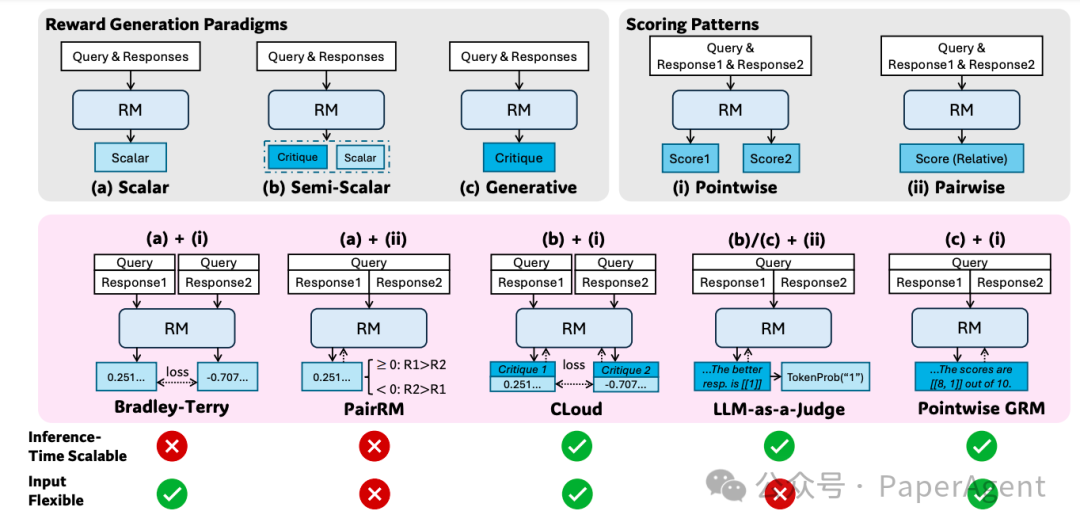
不同的奖励生成范式,包括(a)标量、(b)半标量和(c)生成式方法,以及不同的评分模式,包括(i)逐点式和(ii)成对式方法。我们列出了每种方法的代表性方法,并对应展示了推理时的可扩展性(是否可以通过多次采样获得更好的奖励)和输入灵活性(是否支持对单个和多个响应进行评分)。
-
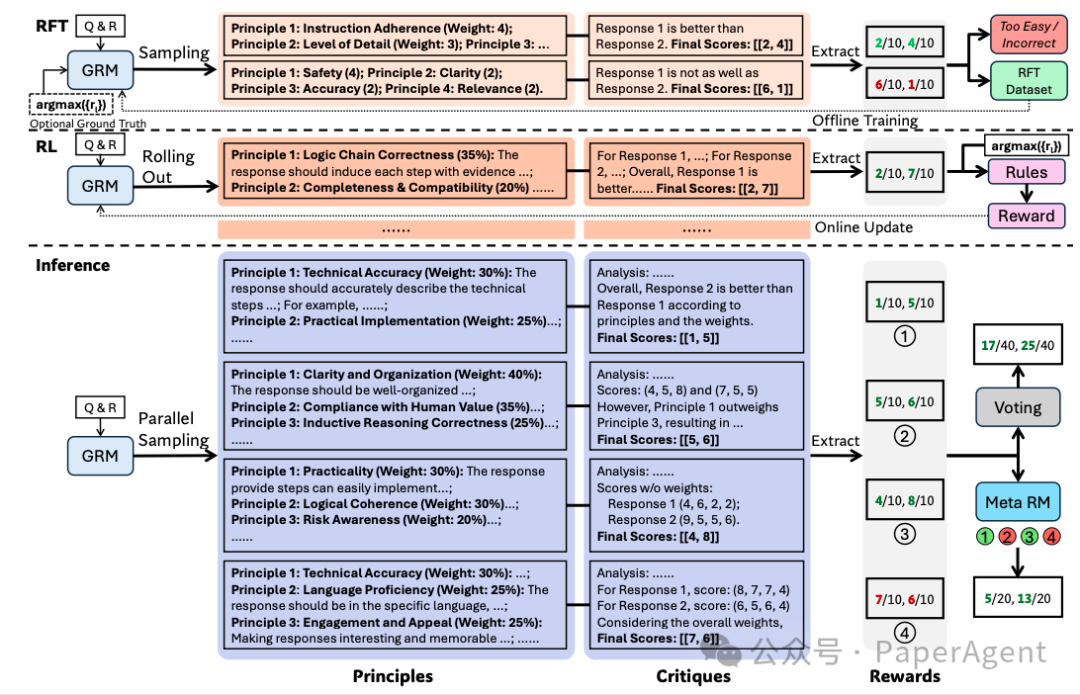
在学习方法上,提出“自我原则批评调整”(Self-Principled Critique Tuning SPCT):这是一种新的学习方法,通过在线强化学习(online RL)来训练GRM模型,使其能够自适应地生成原则(principles)和准确的批评(critiques),从而提高奖励生成的质量和可扩展性,并产生了DeepSeek-GRM模型
SPCT的示意图,包括拒绝式微调、基于规则的强化学习(RL),以及推理阶段的相应可扩展行为。通过简单的投票或由元奖励模型(Meta RM)引导的投票(基于大规模生成的原则),实现推理时的扩展,从而在扩展的价值空间内获得更细致的结果奖励。
-
此外,为了实现有效的推理时扩展,使用并行采样来扩大计算使用,并引入了一个元奖励模型(Meta Reward Modeling, Meta RM)来指导投票过程,以实现更好的扩展性能。
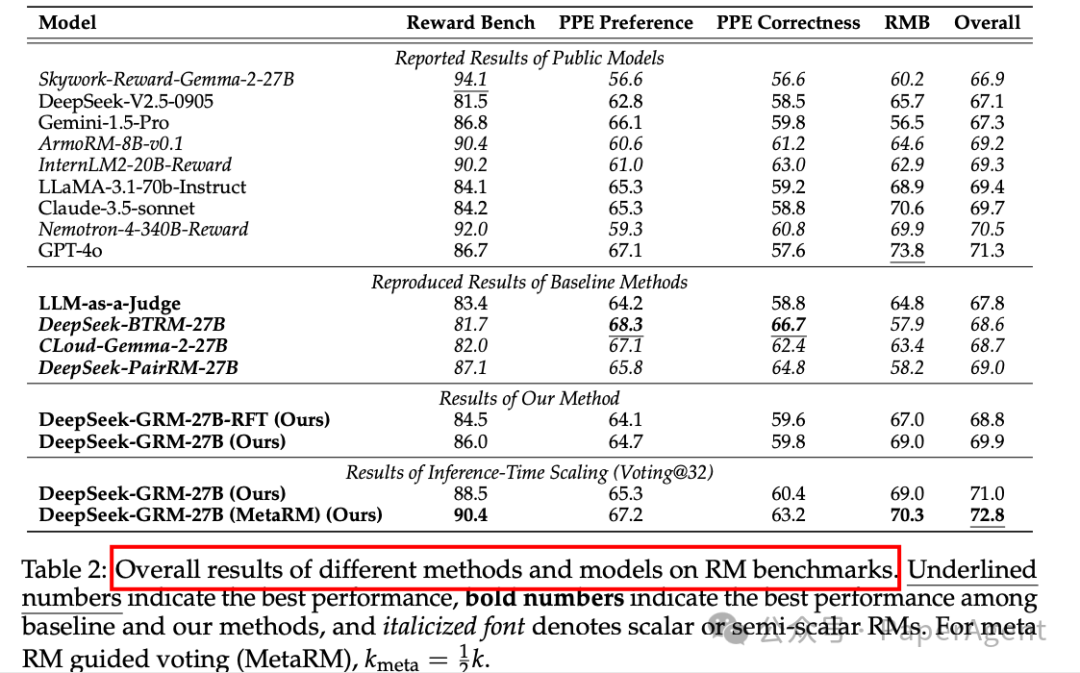
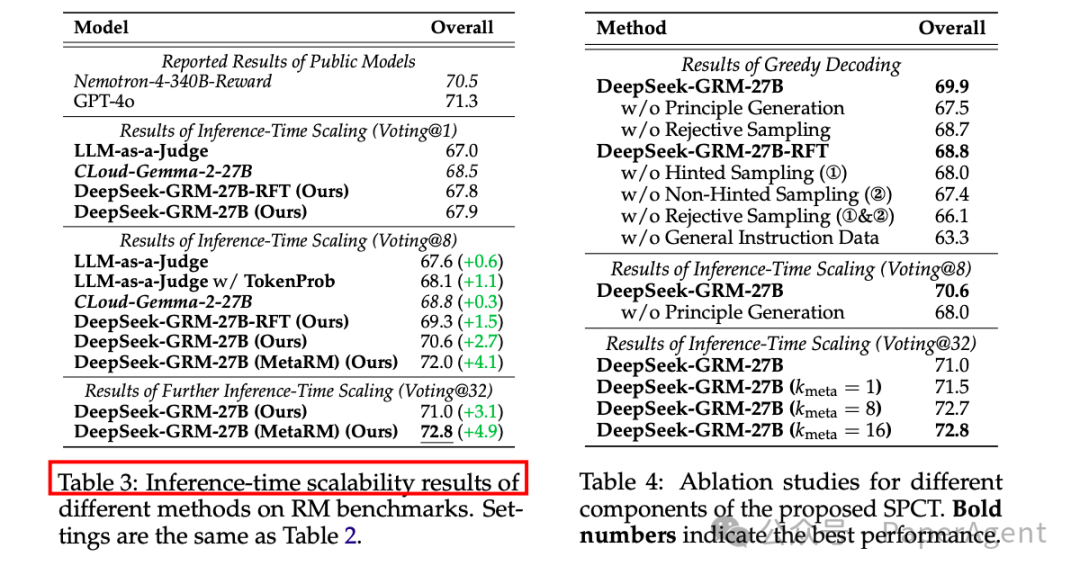
SPCT的有效性:实验表明,SPCT显著提高了GRM模型的质量和推理时可扩展性,超越了现有的方法和模型,且在多个RM基准测试中表现出色,没有明显的领域偏差。
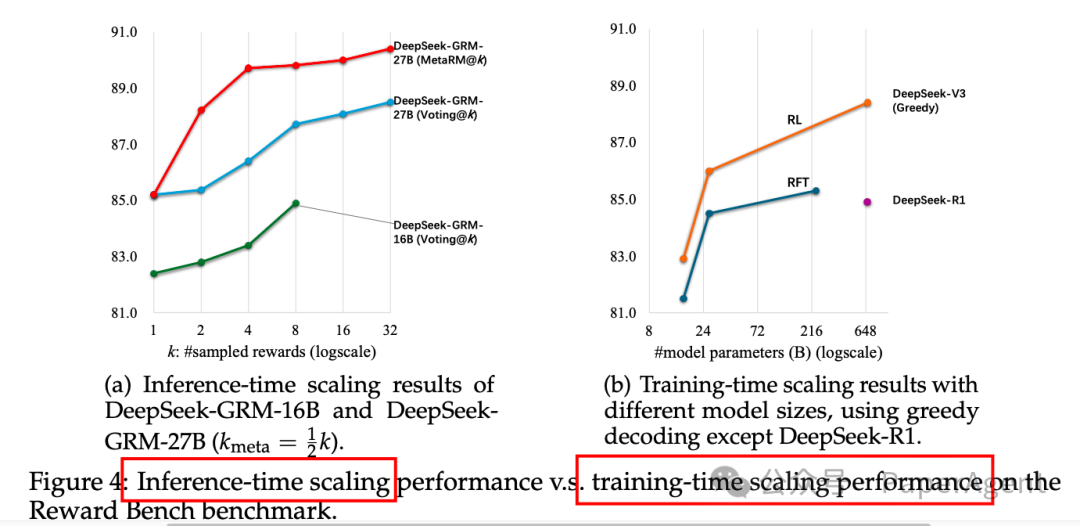
推理时可扩展性:通过并行采样和元RM指导投票,DeepSeek-GRM-27B模型在推理时的性能随着采样数量的增加而显著提高,甚至超过了训练时模型规模扩展的性能。
模型性能对比:DeepSeek-GRM-27B在推理时扩展到32个样本时,能够达到与671B参数模型相当的性能,显示出推理时可扩展性相比训练时模型规模扩展的优势。
https://arxiv.org/pdf/2504.02495Inference-Time Scaling for Generalist Reward Modeling
(文:PaperAgent)