
刚刚,DeepSeek-GRM模型发布,全新推理时Scaling,为R2打前站!
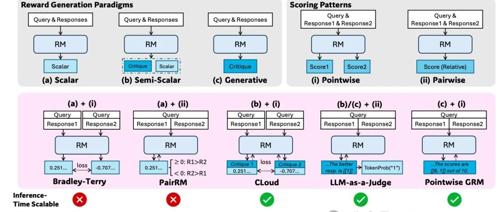
DeepSeek联合清华发布研究成果,提出DeepSeek-GRM模型通过点式生成奖励建模提高通用查询的性能,利用自我原则批评调整等方法实现推理时扩展。该模型在多个基准测试中表现出色,在推理时的性能随着采样数量增加而显著提升。
DeepSeek联合清华发布研究成果,提出DeepSeek-GRM模型通过点式生成奖励建模提高通用查询的性能,利用自我原则批评调整等方法实现推理时扩展。该模型在多个基准测试中表现出色,在推理时的性能随着采样数量增加而显著提升。

最近转行人工智能,作者总结了学习方法和心得,强调要摆正心态、掌握方式方法,并从应用出发学习新技术。他认为技术的本质是一个工具,学习新东西应循序渐进,先从简单到复杂。
