
RL for LLMs,强化学习的 Scaling Law 才刚刚起步?

近期研究者通过奖励模型增强通用奖励模型在推理阶段的可扩展性,同时使用强化学习提升LLM性能。然而,当前强化学习算法仍有改进空间,奖励稀疏性是主要难点之一。
近期研究者通过奖励模型增强通用奖励模型在推理阶段的可扩展性,同时使用强化学习提升LLM性能。然而,当前强化学习算法仍有改进空间,奖励稀疏性是主要难点之一。
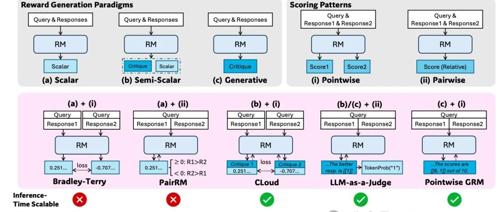
DeepSeek联合清华发布研究成果,提出DeepSeek-GRM模型通过点式生成奖励建模提高通用查询的性能,利用自我原则批评调整等方法实现推理时扩展。该模型在多个基准测试中表现出色,在推理时的性能随着采样数量增加而显著提升。