

为什么说大语言模型(LLM)正在颠覆技术普及的“老规矩”?
著名 AI 大牛、前特斯拉 AI 总监、OpenAI 创始成员之一的安德烈·卡帕西(Andrej Karpathy)刚刚就此写了一篇文章—《权力回归大众:大语言模型如何颠覆技术扩散的传统模式》
文章的核心观点
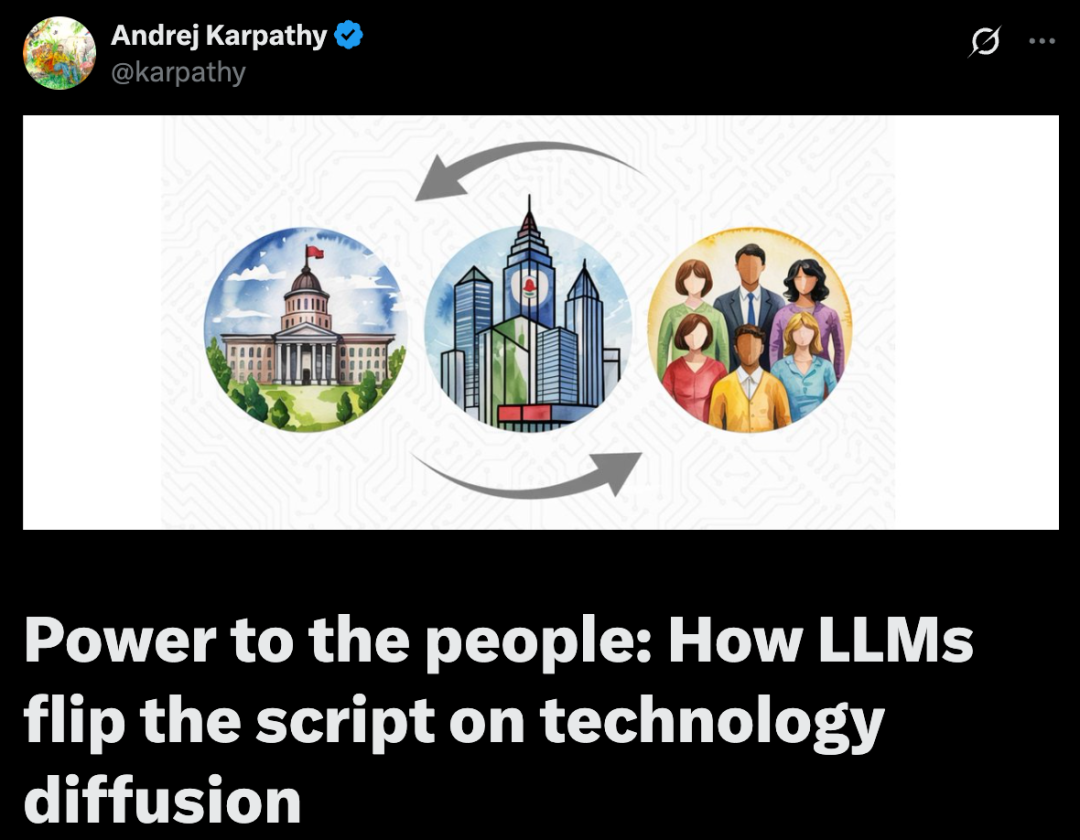
卡帕西敏锐地观察到一个反常现象:像电力、计算机、互联网这些颠覆性技术,过去总是“自上而下”普及的——先是政府、军队,然后是大公司,最后才轮到普通消费者。但 LLM(以 ChatGPT 为典型代表)完全反过来了!普通人成了最早、最大规模的受益者,其影响在个人层面是爆炸性的、颠覆性的,而在企业和政府层面反而显得更慢、更温和。这在技术史上是极其罕见甚至前所未有的。
为什么会这样?卡帕西给出了他的分析:
“万金油” vs. “专家团”:LLM 强在“啥都懂一点”,是个知识广但不深的“通才”。这对个人来说是巨大的赋能,因为我们普通人不可能样样精通,LLM 让我们突然能在很多以前不敢想的领域(编程、法律、研究、创作)达到“还行”的水平。但对于本就拥有各种专家的企业来说,LLM 带来的更多是效率提升,而非能力上的根本突破
“简单粗暴” vs. “精耕细作”:个人使用 LLM 门槛低、限制少、容错率高,可以“跟着感觉走”。但企业应用场景复杂得多,涉及系统集成、安全合规、品牌形象、法律风险等,对准确性和可靠性要求极高,不能容忍 LLM 的“胡说八道”,应用起来自然束手束脚。
“灵活小船” vs. “笨重大船”:大机构固有的文化、流程、官僚主义和内部政治,都让它在面对这种“既强大又可能犯错”的新技术时,转身更慢,采纳更谨慎
以下是全文翻译(口语化的翻译)
权力回归大众:大语言模型如何颠覆技术扩散的传统模式
安德烈·卡帕西
那些能改变世界的技术,一般都是从上往下传的:先是政府或者军队搞出来,然后传到大公司,最后才轮到咱们普通人用——你想想电、加密技术、电脑、飞机、互联网、GPS,是不是都这路子?这感觉也挺自然的,毕竟新出的牛掰技术,一开始肯定又少又贵,还得是懂行的专家才能玩得转
所以啊,LLM这波操作就显得特别不一样,简直神了——它们给咱普通老百姓带来的好处多得不成比例,反倒是在大公司和政府部门里,动静小得多,也慢半拍。ChatGPT可是火得最快的App,每周有4亿人用它写东西、敲代码、搞翻译、当家教、做总结、挖资料、头脑风暴啥的。这可不是以前那些工具的小打小小闹升级,这是直接把咱个人的能力值拉高了好几个档次,而且是全方位的。关键是用起来门槛低到不行——模型便宜(甚至白给)、速度快、谁都能上网用(甚至自己电脑上就能跑),还能用你最习惯的说话方式跟你聊,管你什么语气、黑话还是表情包,都能懂。这简直了!反正据我所知,普通人从来没体验过这么猛、这么快的技术福利
那为啥在大公司和政府那边,这好处就没那么明显呢?我觉得吧,首先,LLM能干的活儿很特别——它啥都懂一点,但啥都不算顶尖专家,就是个“万金油”选手。可一个公司或机构的看家本领,恰恰是能把各种领域的专家(工程师、研究员、分析师、律师、营销大佬等等)聚在一起,集中火力干大事。LLM顶多是让这些专家自己干活更顺手点(比如,帮忙起草个合同初稿、生成点基础代码),对整个组织来说,也就是在本来就能干的事上效率高了那么一丢丢。但对咱个人来说就不一样了,咱一般也就精通一两个领域,LLM这种啥都懂点的“万金油”能力,就能让我们干成以前想都不敢想的事。现在普通人也能捣鼓着写App了,能看懂法律文件了,能搞明白那些高深的论文了,能做数据分析了,能自己做图文视频搞宣传了。干这些,都能达到个差不不多的水平,还不用额外再请专家
其次,公司和政府要处理的事儿复杂多了,协调起来也麻烦得多,想想:各种系统对接、老旧系统拖后腿、公司的形象和说话风格要求、死严的安全规定、隐私保护、国际化问题、法律法规合规、还有各种风险。变量太多、限制太多、要考虑的太多,犯错的空间也小得多。想把这些一股脑塞进LLM的对话框里?没那么容易。你可不能随便“跟着感觉走”写代码,万一它给你“胡说八道”一次,你可能工作就没了。第三点,就是大机构都有的那种“惰性”,大家都懂的:企业文化、老规矩、一有风吹草动就开始的内部“抢地盘”、沟通成本高、给一大帮人搞培训也难,还有那老掉牙的官僚作风。想让它们快速接受一个新出的、啥都能干点但又不精、还老出错的工具?那阻力可大了去了。我不是说LLM对公司政府没影响,但至少眼下,从全社会来看,它们给普通人生活带来的改变,比给那些大机构带来的改变要大得多得多。玛丽、吉姆、乔这些普通人才是最大的受益者,而不是谷歌或者美国政府
往后看,LLM能不能继续普及,还得看它们能不能变得更厉害、能力更全面。这个“好处怎么分”的问题就特别有意思了,关键看花多少钱能买到多大程度的性能提升。现在呢,最顶尖的LLM性能,大家都能用上,还挺便宜。到了一定程度,你再砸钱也买不到明显更好的性能、可靠性或自主性了。钱买不来更好的ChatGPT。比尔·盖茨跟你我一样,用的也是GPT-4o。但这能一直这样吗?训练时砸钱(更多参数、更多数据)、用的时候花时间(更多计算时间)、或者搞“模型组团”(用一堆模型一起上),这些都会让花钱能买到的性能差距变大。另一方面,“模型蒸馏”(把大模型的能耐教给小模型,让小模型也变得很强)又在努力缩小这个差距。当然了,要是哪天钱真能买到比现在好得多的ChatGPT,那情况就不一样了。大公司就能用它们的钱砸出更强的智能。在“个人”这个圈子里,有钱人可能又会把普通人甩开。他们的孩子用GPT-8-pro-max-high辅导功课,你的孩子只能用GPT-6 mini
但至少在现在这个时间点,咱们正处在技术史上一个独一无二、前所未有的时刻。你去翻翻以前的科幻小说,很少有人能猜到AI革命会是这么个搞法。大家以为的都是政府秘密搞个超级大脑,被将军们控制着,哪想到会是ChatGPT这样,几乎一夜之间冒出来,还免费,人人手机上都能用。还记得威廉·吉布森那句名言“未来已来,只是分布不均”吗?嘿,没想到吧——未来来了,而且这次分布得惊人地均匀!力量属于人民! 反正我个人是超爱这一点的
参考:
https://x.com/karpathy/status/1909308143156240538
⭐
(文:AI寒武纪)