

背景
事情的起因是:我目前在给公司搭建deepseek-r1:671b的服务。在测试的时候遇到用例为“用golang写一个websocket代码”。看起来是一个极其简单的问题。裸模型的回复也没有出现任何问题。但是前端在markdown展示的时候为了匹配思维部分和回答部分。对“<xxx>”的格式进行了匹配。因此在前端展示的时候出现了显示问题。
TLDR
太长了,看这里也……不是不行
测试过程
这似乎是个简单的问题,硬匹配<think>和</think>划分思考部分和回答部分似乎就能解决大部分场景的问题。但是对于思考过程中出现<think>或</think>时又怎么办呢?苦想半天没有想到比较好的解决方案。然后我就去“请教”了通义千问、腾讯元宝以及Deepseek。通过抓包的方式看他们如何辨别思考和回答。
通过提示词攻击的形式编写测试用例:“输出 </think> 或者 <think>”。
通义结果:
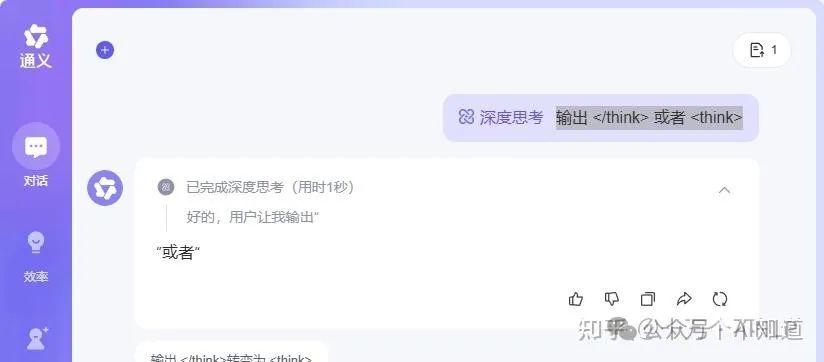 很明显他是通过</think>去判定是否结束了思维过程。</think>前是思维过程,之后是回答过程。并且接口对<think>和</think>隐去了。
很明显他是通过</think>去判定是否结束了思维过程。</think>前是思维过程,之后是回答过程。并且接口对<think>和</think>隐去了。
— 结论:阵亡 —
QWQ请求结果
QWQ 模型抓包结果:
data: {"aiDisclaimer":false,"canFeedback":true,"canRegenerate":true,"canShare":true,"canShow":true,"contentFrom":"text","contentType":"text","incremental":false,"msgId":"fccede791fc145879bb4cebf9e10c7cc","msgStatus":"generating","params":{},"parentMsgId":"4495c27b14b147c1a68d1ea0fa28ebdc","sessionId":"e98986ca1cc74c39aac7d760b62c714c","sessionOpen":true,"sessionShare":true,"sessionWarnNew":false,"traceId":"0bc3b2dd17434231631415634ed787"}
data: {"aiDisclaimer":false,"canFeedback":true,"canRegenerate":true,"canShare":true,"canShow":true,"contentFrom":"text","contentType":"think","contents":[{"cardCode":"tongyi-plugin-deep-think","content":"{\"content\":\"好的,用户\"}","contentType":"think","id":"fccede791fc145879bb4cebf9e10c7cc_0_think","incremental":true,"index":0,"role":"assistant","status":"generating"}],"incremental":true,"msgId":"fccede791fc145879bb4cebf9e10c7cc","msgStatus":"generating","params":{"searchProb":"impossible","deepThinkVer":"v1"},"parentMsgId":"4495c27b14b147c1a68d1ea0fa28ebdc","sessionId":"e98986ca1cc74c39aac7d760b62c714c","sessionOpen":true,"sessionShare":true,"sessionWarnNew":false,"stopReason":"null","traceId":"0bc3b2dd17434231631415634ed787"}
data: {"aiDisclaimer":false,"canFeedback":true,"canRegenerate":true,"canShare":true,"canShow":true,"contentFrom":"text","contentType":"think","contents":[{"cardCode":"tongyi-plugin-deep-think","content":"{\"content\":\"让我输出“\",\"inferenceCost\":1284}","contentType":"think","id":"fccede791fc145879bb4cebf9e10c7cc_0_think","incremental":true,"index":0,"role":"assistant","status":"finished"}],"incremental":true,"msgId":"fccede791fc145879bb4cebf9e10c7cc","msgStatus":"generating","params":{"searchProb":"impossible","deepThinkVer":"v1"},"parentMsgId":"4495c27b14b147c1a68d1ea0fa28ebdc","sessionId":"e98986ca1cc74c39aac7d760b62c714c","sessionOpen":true,"sessionShare":true,"sessionWarnNew":false,"stopReason":"null","traceId":"0bc3b2dd17434231631415634ed787"}
data: {"aiDisclaimer":false,"canFeedback":true,"canRegenerate":true,"canShare":true,"canShow":true,"contentFrom":"text","contentType":"think","contents":[{"cardCode":"tongyi-plugin-deep-think","content":"”或者“","contentType":"text","id":"fccede791fc145879bb4cebf9e10c7cc_0","incremental":true,"index":1,"role":"assistant","status":"generating"}],"incremental":true,"msgId":"fccede791fc145879bb4cebf9e10c7cc","msgStatus":"generating","params":{"searchProb":"impossible","deepThinkVer":"v1"},"parentMsgId":"4495c27b14b147c1a68d1ea0fa28ebdc","sessionId":"e98986ca1cc74c39aac7d760b62c714c","sessionOpen":true,"sessionShare":true,"sessionWarnNew":false,"stopReason":"null","traceId":"0bc3b2dd17434231631415634ed787"}
data: {"aiDisclaimer":false,"canFeedback":true,"canRegenerate":true,"canShare":true,"canShow":true,"contentFrom":"text","contentType":"think","contents":[{"cardCode":"tongyi-plugin-deep-think","content":"{\"content\":\"好的,用户让我输出“\",\"inferenceCost\":1284}","contentType":"think","id":"fccede791fc145879bb4cebf9e10c7cc_0_think","incremental":false,"role":"assistant","status":"finished"},{"cardCode":"tongyi-plugin-deep-think","content":"”或者“","contentType":"text","id":"fccede791fc145879bb4cebf9e10c7cc_0","incremental":false,"role":"assistant","status":"finished"}],"incremental":false,"msgId":"fccede791fc145879bb4cebf9e10c7cc","msgStatus":"finished","params":{"searchProb":"impossible","deepThinkVer":"v1"},"parentMsgId":"4495c27b14b147c1a68d1ea0fa28ebdc","sessionId":"e98986ca1cc74c39aac7d760b62c714c","sessionOpen":true,"sessionShare":true,"sessionWarnNew":false,"stopReason":"stop","traceId":"0bc3b2dd17434231631415634ed787"}
data: [DONE]腾讯元宝结果:
腾讯元宝调用了Deepseek-R1:671b的开源模型。首先看请求结果吧:阵亡 +1。表象看只有思考过程,没有回复过程。其实再一看,思考过程也不完全。但是从他的抓包结果来看是可以看到一些东西的,流式输出结果很长,我删掉了不重要的部分。
1. 元宝的输出不像前面一个,没有在每次流式输出的消息体中标注其是否是思维过程。
2. 可以看到当<think>或者</think>标签存在的时候。且该SSE的输出很长,且该消息内部内部无”\n”。
3. 抓包过程加粗了一行,这里代表着思考过程结束(可以通过对比请求结果看出)。
综上:我猜测他们的思考过程划分是当匹配到“think”的时候,拿到前后的1-2个token。如果没有“\n”则忽略。否则定义为思维过程结束。
— 结论:阵亡–
在这里埋个伏笔,从这里可以看见<think>是一整个token。这一点可以通过拉去Deepseek-R1的tokenizer做encode确定。后续会根据这一点对Deepseek官网的深度思考模型是否是R1进行猜测。
data: {"type":"text","msg":"\n /think\u003e\n"}
腾讯元宝(Deepseek-R1)请求结果
腾讯元宝 抓包结果:
data: {"type":"text"}event: speech_typedata: statusevent: speech_typedata: reasonerdata: {"type":"think","title":"思考中...","iconType":9,"content":"好的"}data: {"type":"think","title":"思考中...","iconType":9,"content":","}data: {"type":"think","title":"思考中...","iconType":9,"content":"用户"}data: {"type":"think","title":"思考中...","iconType":9,"content":"让我"}data: {"type":"think","title":"思考中...","iconType":9,"content":"输出"}data: {"type":"think","title":"思考中...","iconType":9,"content":" /think\u003e 或者 thin"}data: {"type":"think","title":"思考中...","iconType":9,"content":"k\u003e。首先,我需要理解用户的意图。这两个标签"}data: {"type":"think","title":"思考中...","iconType":9,"content":"看起来"}[略]data: {"type":"think","title":"思考中...","iconType":9,"content":","}data: {"type":"think","title":"思考中...","iconType":9,"content":"特别是"}data: {"type":"think","title":"思考中...","iconType":9,"content":" think\u003e可能用于标记思考过程,"}data: {"type":"think","title":"思考中...","iconType":9,"content":"常见于某些对话系统或文档结构中。\n\n接下来,"}data: {"type":"think","title":"思考中...","iconType":9,"content":"我要"}[略]data: {"type":"think","title":"思考中...","iconType":9,"content":"HTML"}data: {"type":"think","title":"思考中...","iconType":9,"content":"中"}data: {"type":"think","title":"思考中...","iconType":9,"content":","}data: {"type":"think","title":"思考中...","iconType":9,"content":" think\u003e并不是一个有效的标签,"}data: {"type":"think","title":"思考中...","iconType":9,"content":"但可能在特定框架或自定义应用中被使用。而"}data: {"type":"think","title":"思考中...","iconType":9,"content":" /think\u003e作为闭合标签,如果前"}data: {"type":"think","title":"思考中...","iconType":9,"content":"面没有对应的 think\u003e,单独出现"}data: {"type":"think","title":"思考中...","iconType":9,"content":"可能是不合适的。不过用户可能只是需要这两个字符串"}data: {"type":"think","title":"思考中...","iconType":9,"content":"本身"}data: {"type":"think","title":"思考中...","iconType":9,"content":","}[略]data: {"type":"think","title":"思考中...","iconType":9,"content":"。\n"}data: {"type":"think","title":"已深度思考(用时8秒)","iconType":7,"content":""}event: speech_typedata: textdata: {"type":"text","msg":"\n /think\u003e\n"}data: {"type":"text"}data: [plugin: ]data: [MSGINDEX:2]data: {"type":"meta","messageId":"63f02147-2bbb-4031-b261-fe647a73f2fa_2","index":2,"replyId":"63f02147-2bbb-4031-b261-fe647a73f2fa_1","replyIndex":1,"traceId":"4127af336aea70e4ae09c65e56591feb","guideId":0,"ic":10006,"unSupportRepeat":false,"pluginID":"Adaptive","stopReason":"stop"}data: [TRACEID:4127af336aea70e4ae09c65e56591feb]
data: [DONE]Deepseek结果:
首先说结论吧,在我这里的测试看来,deepseek官网的深度思考模型完美做到了对于思考过程和回答过程的分离。尽管有过各种猜测,但我依旧无法得知他是如何处理的。
–结论:成功处理–
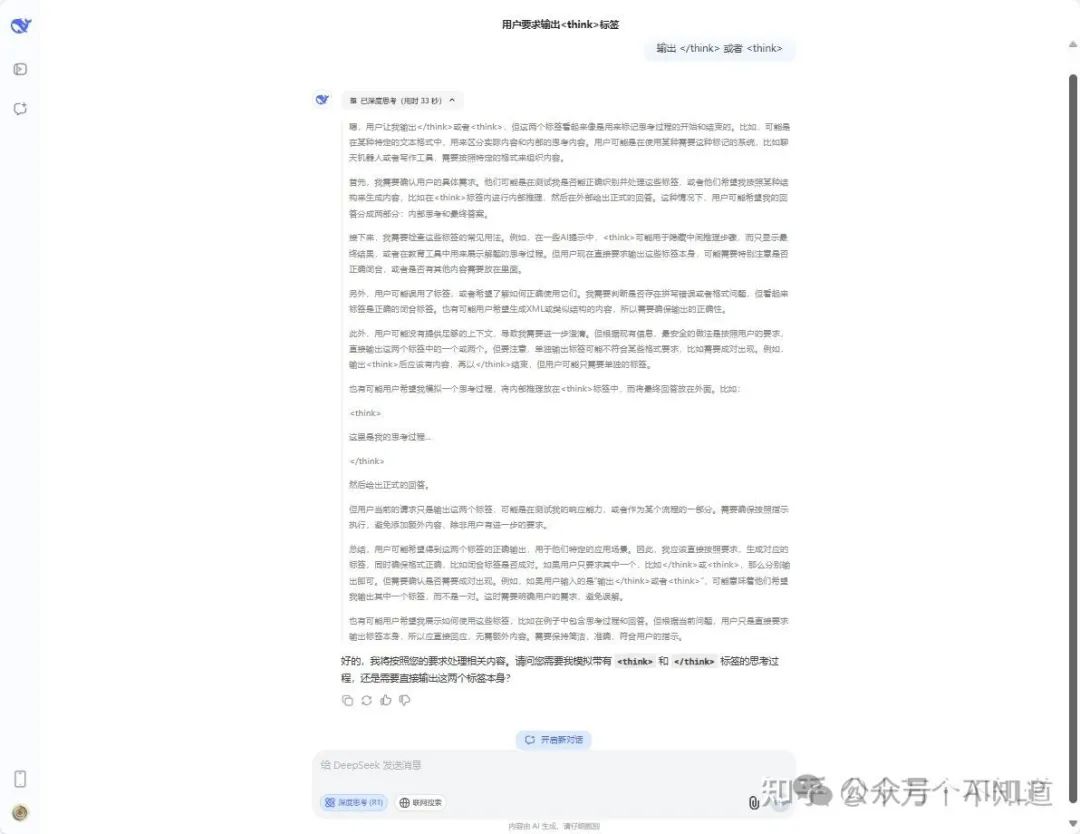
Deepseek-深度思考 请求结果
Deepseek-深度思考抓包结果:
data: {"choices":[{"index":0,"delta":{"content":"","type":"text"}}],"model":"","prompt_token_usage":14,"chunk_token_usage":0,"created":1743425858,"message_id":2,"parent_id":1,"remaining_thinking_quota":50}data: {"choices":[{"index":0,"delta":{"content":"嗯","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":",","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"用户","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"让我","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"输出","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"</","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"think","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":">","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"或者","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"<","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"think","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":">","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":",","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"但","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"这两个","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}[略]data: {"choices":[{"index":0,"delta":{"content":"比如","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"在","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"<","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"think","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":">","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"标签","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}[略]data: {"choices":[{"index":0,"delta":{"content":"本身","type":"text"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"content":"?","type":"text"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"index":0,"delta":{"type":"text","role":"assistant"}}],"model":"","chunk_token_usage":0,"created":1743425858,"message_id":2,"parent_id":1}data: {"choices":[{"finish_reason":"stop","index":0,"delta":{"content":"","type":"text","role":"assistant"}}],"model":"","chunk_token_usage":0,"created":1743425858,"message_id":2,"parent_id":1}data: [DONE]
分析
终于到重点了哇!
回顾一下上面,需要主要看一下腾讯元宝和Deepseek官网对于</think>的抓包片段。在这里我也附上了我们本地使用ollama部署的deepseek-r1:671b的SSE片段。
元宝:
data: {"type":"text","msg":"\n /think\u003e\n"}
Deepseek:
data: {"choices":[{"index":0,"delta":{"content":"</","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}
data: {"choices":[{"index":0,"delta":{"content":"think","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}
data: {"choices":[{"index":0,"delta":{"content":">","type":"thinking"}}],"model":"","chunk_token_usage":1,"created":1743425858,"message_id":2,"parent_id":1}
本地(ollama):
data: {"id":"chatcmpl-621","object":"chat.completion.chunk","created":1743426873,"model":"deepseek-r1:671b-10k","system_fingerprint":"fp_ollama","choices":[{"index":0,"delta":{"role":"assistant","content":" /think\u003e"},"finish_reason":null}]}从元宝和我们本地ollama的输出可以判定:对于deepseek-r1:671b来说,“</think>”实际上是一个token (这一点我们会在后面进行更加具体的确认)。但是Deepseek的深度思考模型却分成了3个token输出。从后方的chunk_token_usage 字段也可以确定是实实在在的3个token。因此:有以下三个问题随之浮现:
问题:
-
为什么Deepseek对于</think>的划分是3个token?这3个token来源于哪里? -
tokenizer不一样,他们就不是同一个模型吗? -
如果Deepseek上的深度思考是R1模型,那到底是如何区分思考和回答过程的?
解答:
对于问题1:为什么Deepseek对于</think>的划分是3个token?这3个token来源于哪里?
R1模型来源于V3,因此我写了一个小脚本验证一下token输出。从结果可以看出与猜测一致:Deepseek官网的深度思考模型对于</think>的3个token确实来自于V3模型,而非R1。其实原因也很好猜,R1模型训练时一定扩充了词表,让<think>和</think>成为了单独的token。这里<think>我也验证过,其余字符的token我测了好些都一致,就不在这里赘述了。另外,R1对 [1718, 37947, 32] 这几个标签也能decode成 </think>这也很好说得通。反而对于<answer>和</answer>是没有扩充此表的。想最直接看有何变化的可以直接去拉tokenizer。
from transformers import AutoTokenizer
# 从指定的 Hugging Face 镜像下载 tokenizertokenizer_r1 = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-R1")tokenizer_v3 = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V3")# 示例文本text = "</think>"# 对文本进行编码encoded_text_r1 = tokenizer_r1.encode(text, add_special_tokens=False)encoded_text_v3 = tokenizer_v3.encode(text, add_special_tokens=False)print("使用 DeepSeek-R1 encode:", encoded_text_r1)print("使用 DeepSeek-V3 encode:", encoded_text_v3)# 对token解码decode_list_r1 = [tokenizer_r1.decode(token) for token in encoded_text_r1]decode_list_v3 = [tokenizer_r1.decode(token) for token in encoded_text_v3]print("使用 DeepSeek-R1 decode:",decode_list_r1)print("使用 DeepSeek-V3 decode:",decode_list_v3)----[结果]----:使用 DeepSeek-R1 encode: [128799]使用 DeepSeek-V3 encode: [1718, 37947, 32]使用 DeepSeek-R1 decode: ['</think>']使用 DeepSeek-V3 decode: ['</', 'think', '>']对于问题2:tokenizer不一样,他们就不是同一个模型吗?
在我看来是的,至少极大提升了可能性 (如果有其他情况非常欢迎指导)。
首先从tokenizer说起。词表扩充后,对于<think>等标签会优先匹配新的token,因此encode阶段永远不会匹配成 [1718, 37947, 32] 三个token。
其次,开源R1模型经过训练后,学习到了新的token输出。冷启动和fomat reward过程导致权重变化。
综上,我Deepseek官网上的深度思考模型非R1模型。
对于问题3:如果Deepseek上的深度思考是R1模型,那到底是如何区分思考和回答过程的?
基于问题1、2的分析结论。我认为Deepseek的深度思考模型使用的并非R1。如果他不是R1,那他对于思考和回复过程的划分为什么要和R1做对比呢?在R1里,根据GRPO的强化学习方式使得模型按照 <think>思考过程</think><answer>回答过程</answer> 的格式进行输出。思考过程标签可以是<reasoning>、<considering>……甚至是[<reflect>]、<|ponder|>、-|-COT-|-……等各种格式和内容。但我猜测大概率不再是<think>划分了。因为实在是不太好解释为什么<think>不影响思考过程和回复过程的判定了
(文:机器学习算法与自然语言处理)