


近年来,检索增强生成(RAG)技术蓬勃发展,其通过引入外部文本知识有效减少了大语言模型在进行实时、专业领域文本知识问答时的幻觉问题。由于多模态数据(文本、图像、视频等)存在更加丰富的上下文信息,如何构建多模态检索增强生成(MRAG)系统,提升对外部多模态知识的利用,引起了众多研究者的关注。
华为云大模型应用算法团队系统性地调研了多模态检索增强生成(MRAG)的最新研究进展和主要技术路径,形成本领域的综述文章一篇,引用或介绍了相关论文510余篇,目前以预印版形式上传到github和arXiv网站,期望能为各位研究人员和工程人员提供一定的技术参考。

GitHub项目链接:https://github.com/PanguIR/MRAGSurvey
总览
多模态检索增强生成(MRAG)通过将文本、图像、视频等多模态数据整合到检索与生成过程中,显著提升了多模态大语言模型(MLLM)的性能。传统检索增强生成(RAG)系统主要依赖文本数据,通过动态引入外部知识有效减少了幻觉现象并提高了回答准确性,但其单模态特性限制了系统对多模态数据中丰富上下文信息的利用。MRAG通过扩展RAG框架实现多模态检索与生成,从而能够提供更全面且符合上下文语境的回答。在MRAG框架中,检索阶段涉及从多模态数据中定位并整合相关知识,生成阶段则利用多模态大语言模型(MLLM)融合多种数据类型的信息进行答案合成。这种方法不仅提升了问答系统的质量,还能通过将回答锚定在多模态事实知识上显著降低幻觉发生率。最新研究表明,在需要同时理解视觉与文本信息的关键场景中,MRAG的表现显著优于传统单模态RAG系统。
该综述系统梳理了MRAG研究的现状,聚焦四大核心维度:关键技术组件、数据集、评估方法与指标,以及现有局限性。通过深入解析这些方面,综述旨在为MRAG系统的构建与优化提供全景式洞察。此外,综述还着重探讨了当前挑战并提出了未来研究方向,以推动这一前沿领域的持续探索。综述的研究工作揭示了MRAG在多模态信息检索与生成领域的革命性潜力,为其发展与应用提供了前瞻性视角。
一、MRAG发展阶段纵览(从1.0到3.0)
多模态检索增强生成(MRAG)是传统检索增强生成(RAG)框架的重要演进,在继承其基础架构的同时,扩展了处理多模态数据的能力。传统RAG仅能处理纯文本,而MRAG整合了图像、音频、视频与文本等多模态数据,从而能够应对现实世界中信息跨模态的复杂多样化应用场景。
MRAG发展初期,研究者将多模态数据转化为统一的文本表征。这种方法通过复用基于文本的检索与生成机制,实现了从RAG到MRAG的无缝过渡。尽管该策略简化了多模态数据整合流程并优化了端到端用户体验,但也存在显著缺陷:例如转换过程会导致图像中的视觉细节、音频中的声调特征等模态特异性信息丢失,制约了系统充分挖掘多模态输入潜力的能力。后续研究聚焦于突破这些限制,开发出更先进的MRAG系统优化方法。
这些突破性进展显著提升了MRAG的性能与泛用性,使其在多项多模态任务中达到业界最优水平。本文将MRAG的演进历程划分为三个鲜明发展阶段:
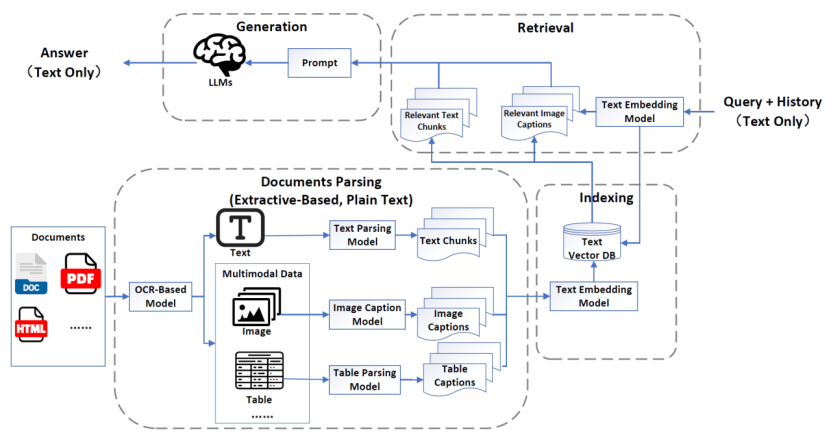
MRAG1.0
MRAG1.0的架构(通常被称为”伪MRAG”)与传统RAG高度相似,包含三个核心模块:文档解析与索引、检索、生成。虽然整体流程基本保持一致,但其核心差异体现在文档解析阶段。在该阶段,系统会采用专用模型(例如OCR模型)将多模态数据转化为特定模态的文本描述(caption),这些描述文本将与常规文本数据共同存储,以供后续环节调用。
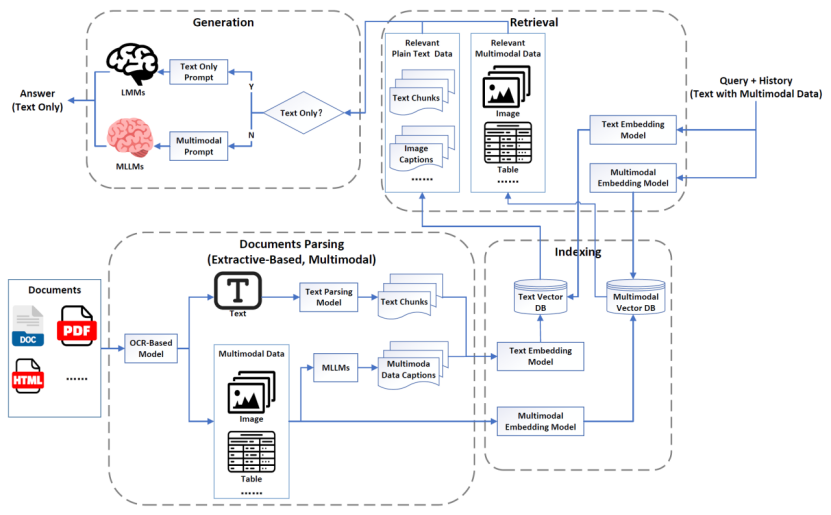
MRAG2.0
MRAG2.0的架构通过文档解析与索引技术保留多模态数据,同时引入多模态检索和多模态大语言模型(MLLM)进行答案生成,真正迈入了多模态时代。
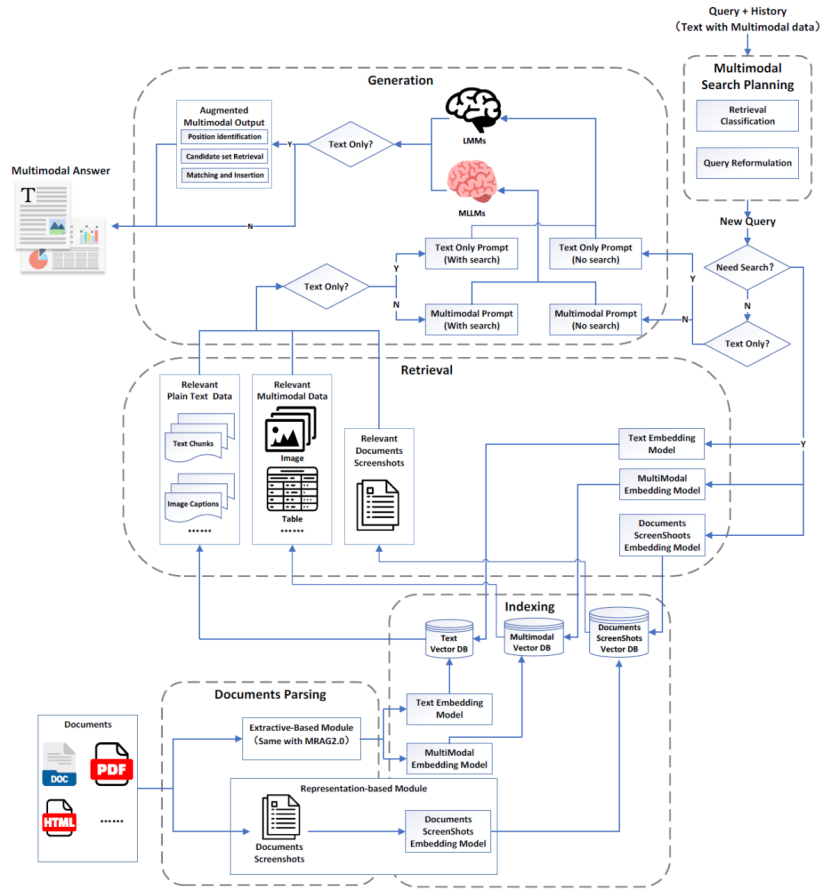
MRAG3.0
MRAG3.0架构在文档解析与索引阶段集成文档截图以最小化信息损失。在输入阶段引入多模态搜索规划模块,统一视觉问答(VQA)与检索增强生成(RAG)任务,同时提升用户查询精准度。输出阶段通过多模态数据增强模块,将纯文本转化为多模态形式生成增强答案,从而实现生成信息的富媒体化升级。
二、MRAG的技术模块组件
MRAG系统包含五大关键技术组件:多模态文档解析与索引、多模态搜索规划、多模态检索、多模态生成。
多模态文档解析与索引(Multimodal Document Parsing and Indexing)
多模态文档解析与索引旨在为MRAG系统通过解析外部知识库中的多模态文档,提升生成答案的质量,主要分为抽取式与表示式两类:
(1)抽取式方法:
a)纯文本抽取:早期工具(如PyMuPDF)直接提取文本,但忽略多模态信息。OCR技术通过文本检测、识别与解析三阶段提升精度,但存在误差累积和计算资源消耗问题。
b)多模态抽取:保留原始模态数据,但需针对不同模态设计专用模型(如TableNet解析表格)。近期MLLMs趋向统一框架处理多模态数据。
(2)表示式方法:直接以文档截图或子图像作为输入,利用MLLMs编码全局与局部信息。
多模态搜索规划(Multimodal Search Planning)
多模态搜索规划旨在通过有效检索和整合多模态信息以应对MRAG系统的复杂查询。其方法主要分为两类:固定规划(Fixed Planning)和自适应规划(Adaptive Planning)。
(1)固定规划(Fixed Planning)
早期MRAG系统采用固定的处理流程,缺乏对不同查询需求的动态适应能力,主要包括两种范式:
a)单模态检索规划
文本中心化(Text-centric):将多模态查询(如图文混合)转换为纯文本形式进行检索。但这种方法可能导致语义偏差,无法精准捕捉用户意图。
图像中心化(Image-centric):无论查询特性如何,均优先执行图像检索。然而,研究表明强制图像检索可能引入无关视觉噪声,尤其在文本信息已足够时反而降低性能。
b)多模态检索规划
近期研究尝试结合文本和视觉检索,但仍采用固定流程。例如,强制对所有含图像的查询执行Google Lens搜索,再重新生成查询。这种刚性设计可能导致冗余计算,且无法根据查询需求灵活调整。
局限性:
a)无法适应多样化查询需求,检索策略与信息需求不匹配;
b)冗余检索增加计算开销,并可能引入噪声;
c)部分查询可能无需检索,但固定流程仍执行不必要的操作。
(2)自适应规划(Adaptive Planning)
针对固定规划的不足,自适应方法通过动态调整策略优化检索过程。
优势:
a)根据查询上下文和中间结果灵活调整策略;
b)减少冗余检索,提升效率;
c)更精准匹配用户意图,避免噪声干扰。
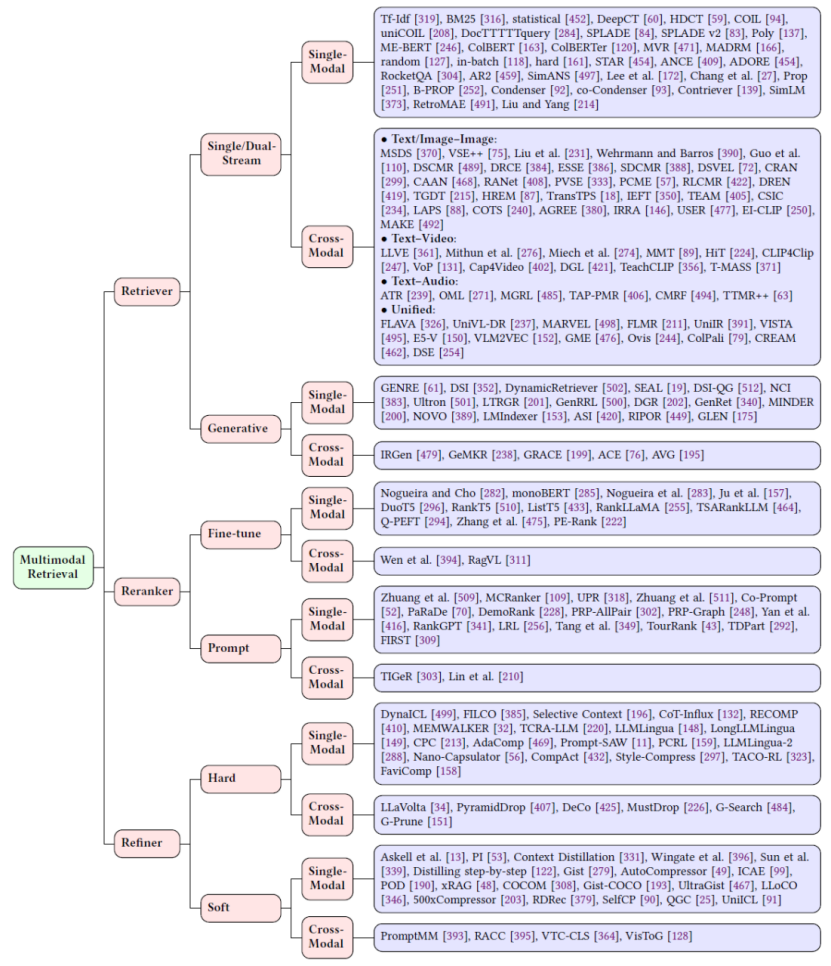
多模态检索(Multimodal Retrieval)
MRAG系统中多模态检索包含三个核心组件:检索器、重排序器和优化器。这些组件各司其职又相互关联,共同提升大语言模型信息检索的质量与相关性。
多模态生成(Multimodal Generation)
多模态大模型(MLLMs)通过整合文本、图像、音频和视频等多种数据类型,实现了跨模态内容的生成。根据输入和输出的生成视角,相关研究可分为模态输入和模态输出两类。
(1)模态输入:研究重点从单一文本模态,扩展到简单模态图像扩展到复杂模态(如视频),再扩展到任意模态的统一处理。
(2)模态输出:从单一文本答案到多模态输出(如文本+图像/视频)以及输出增强(检索配图、位置识别等)演进。

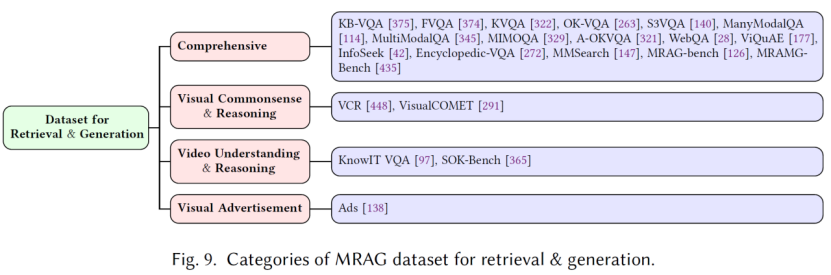
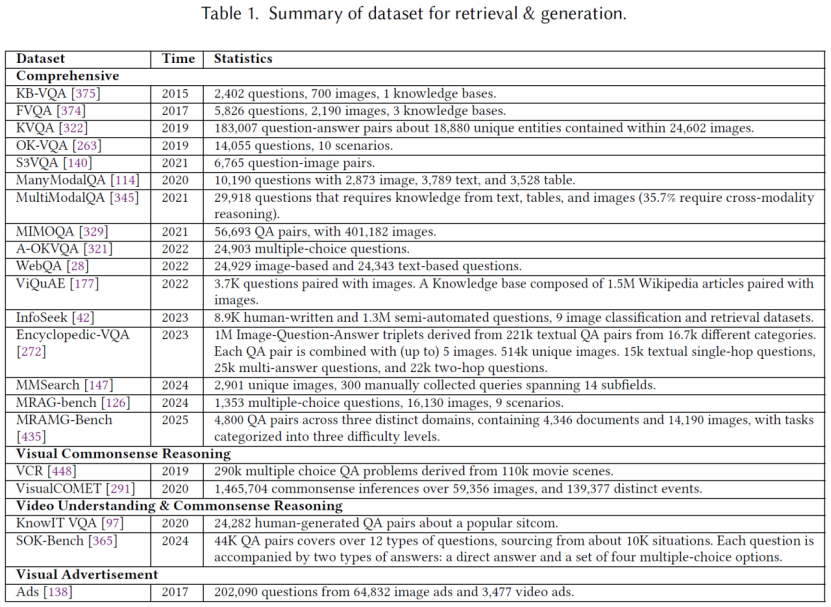
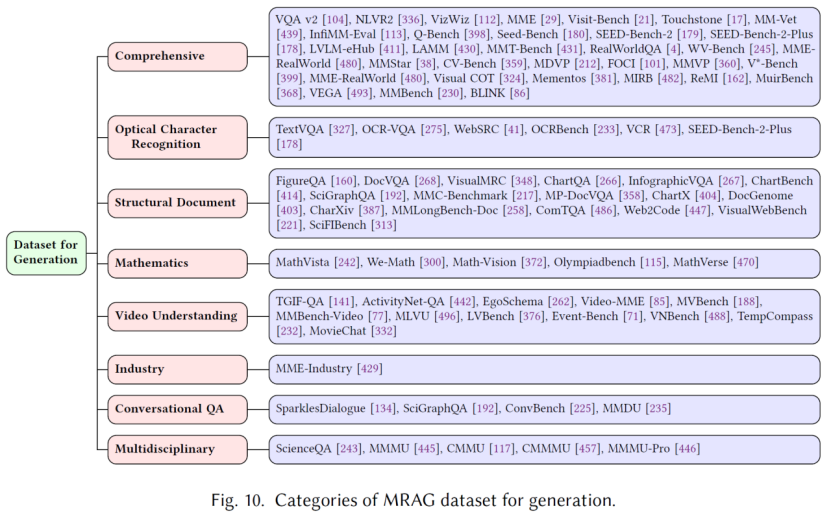
三、MRAG数据集基准
为评估MRAG系统在现实世界多模态理解和知识问答任务中的综合能力,综述系统整合了现有数据集以全面测评MRAG流程。这些数据集分为两大类:
(1)检索与生成联合组件:要求系统检索外部知识并生成精准回答,评估检索与生成的协同能力。
(2)纯生成任务:聚焦模型在不依赖外部检索的情况下产出上下文准确输出的能力。该分类体系能细致评估MRAG系统在不同场景下的优势与局限性。
总结
本综述对多模态检索增强生成(MRAG)这一新兴领域进行了全面探讨,揭示了其通过整合文本、图像、视频等多模态数据来增强多模态大语言模型(MLLM)能力的巨大潜力。与传统基于文本的RAG系统不同,MRAG致力于解决跨模态信息检索与生成的挑战,从而提升响应内容的准确性与相关性,同时减少幻觉现象。本综述从四大核心视角系统性地解析了MRAG:关键技术组件、数据集、评估方法与指标以及现存局限性。研究不仅指出了当前面临的挑战——例如多模态知识的有效整合与生成内容的可靠性保障,同时提出了未来研究方向。通过提供结构化的领域概览与前瞻性见解,本综述旨在为研究者推动MRAG发展提供指引,最终促进构建更强大、更通用的多模态检索增强生成系统。
(文:机器学习算法与自然语言处理)