
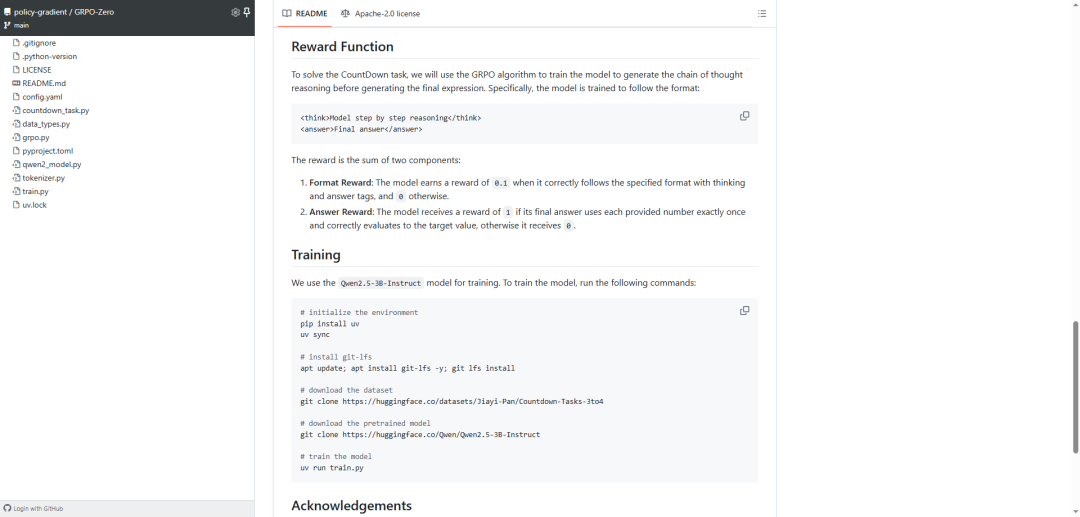
GRPO 训练实现的极简依赖版本。几乎从零开始构建所有组件,仅依赖 tokenizers 进行分词处理,以及 pytorch 完成训练。
参考文献:
[1] http://github.com/policy-gradient/GRPO-Zero
(文:NLP工程化)
GRPO 训练实现的极简依赖版本。几乎从零开始构建所有组件,仅依赖 tokenizers 进行分词处理,以及 pytorch 完成训练。
参考文献:
[1] http://github.com/policy-gradient/GRPO-Zero
(文:NLP工程化)