

极市导读
CVPR 2025论文录用结果揭晓,腾讯优图实验室共有22篇论文入选,内容涵盖深度伪造检测、自回归视觉生成、多模态大语言模型等研究方向 >>加入极市CV技术交流群,走在计算机视觉的最前沿
近日, CVPR 2025(IEEE/CVF Conferenceon on Computer Vision and Pattern Recognition)论文录用结果揭晓,本次大会共2878篇被录用,录用率为22.1%。CVPR是计算机视觉领域的顶级国际会议,CCF A类会议,每年举办一次。CVPR 2025将于6月11日-15日,在美国田纳西州纳什维尔音乐城市中心召开。
今年,腾讯优图实验室共有22篇论文入选,内容涵盖深度伪造检测、自回归视觉生成、多模态大语言模型等研究方向,展现了优图在人工智能领域的技术能力与创新突破。
以下为入选论文概览:
01
基于视频混合增强和时空适配器的深度伪造视频检测方法
Generalizing Deepfake Video Detection with Plug-and-Play: Video-Level Blending and Spatiotemporal Adapter Tuning
Zhiyuan Yan (北大), Yandan Zhao, Shen Chen, Mingyi Guo (北大), Xinghe Fu, Taiping Yao, Shouhong Ding, Li Yuan (北大)
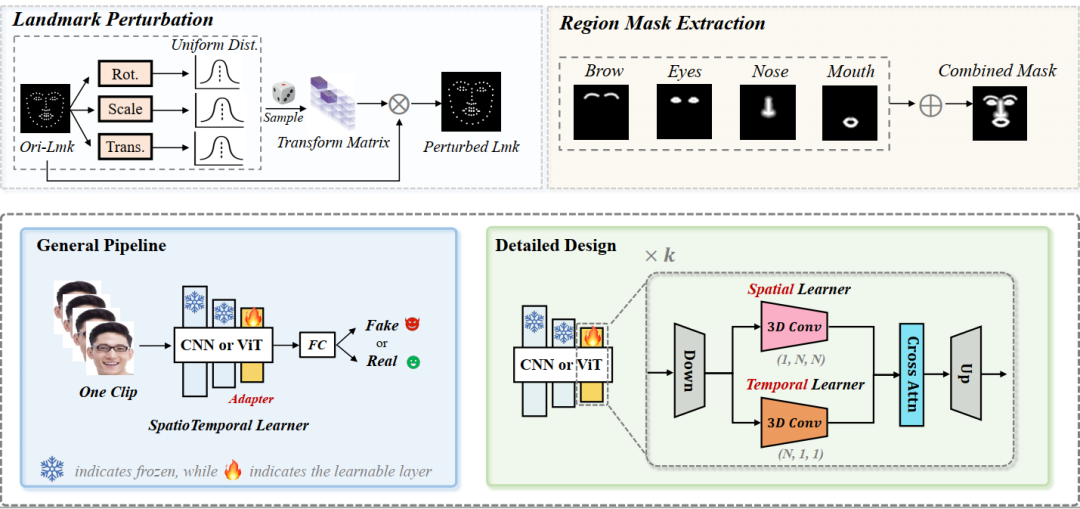
当前深度伪造视频检测的发展面临三大关键挑战:(1)时间特征可能复杂且多样:如何识别通用的时间伪影以增强模型的泛化能力?(2)时空模型往往过度依赖一种类型的伪影而忽视另一种:如何确保从两者中平衡学习?(3)视频处理自然需要大量资源:如何在保证准确性的前提下提升效率?本文尝试同时解决这三个挑战。首先,受图像伪造检测中使用图像级混合数据的显著泛化性启发,我们探讨了视频级混合在视频检测中的有效性。随后,我们进行了深入分析,发现了一种先前未被充分研究的时间伪造伪影:面部特征漂移(FFD),这种伪影在不同伪造视频中普遍存在。为了重现FFD,我们提出了一种新颖的视频级混合数据(VB),通过逐帧混合原始图像及其扰动版本,作为挖掘更通用伪影的困难负样本。其次,我们精心设计了一个轻量级的时空适配器(StA),使预训练的图像模型能够高效地同时捕捉空间和时间特征。StA采用双流3D卷积设计,具有不同大小的卷积核,使其能够分别处理空间和时间特征。大量实验验证了所提方法的有效性,并表明我们的方法能够很好地泛化到之前未见过的伪造视频,即使是针对最新一代的伪造方法。
论文链接:
https://arxiv.org/pdf/2408.17065
02
TIMotion:高效双人动作生成的时序与交互框架
TIMotion: Temporal and Interactive Framework for Efficient Human-Human Motion Generation
Yabiao Wang, Shuo Wang, Jiangning Zhang, Ke Fan(上交), Jiafu Wu, Zhucun Xue(浙大), Yong Liu(浙大)
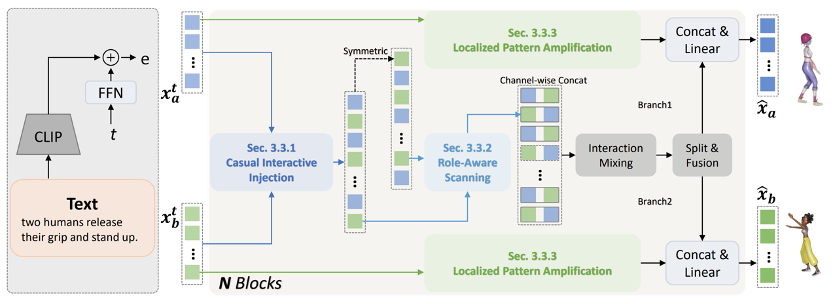
双人动作生成对于理解人类的行为至关重要。当前的方法主要分为两大类:基于单人的方法和基于独立建模的方法。为了深入研究这一领域,我们将整个生成过程抽象为一个通用框架MetaMotion,它包括两个阶段:时序建模和交互混合。在时序建模中,基于单人的方法直接将两个人连接成一个人,而基于独立建模的方法则跳过了交互序列的建模。然而,上述不充分的建模导致了次优的性能和冗余的模型参数。在本文中,我们提出了TIMotion(时序与交互建模),这是一个高效且有效的人-人动作生成框架。具体来说,我们首先提出因果交互注入(CII),利用时序和因果属性将两个独立序列建模为一个因果序列。然后,我们提出角色演变扫描(RES),以适应交互过程中主动和被动角色的变化。最后,为了生成更平滑、更合理的动作,我们设计了局部模式放大(LPR)来捕捉短期动作模式。在InterHuman和Inter-X的实验表明,相比其它方法,我们的方法取得了更好的性能。
论文链接:
https://aigc-explorer.github.io/TIMotion-page/
03
Sonic:将焦点转移到肖像动画中的全局音频感知
Sonic: Shifting Focus to Global Audio Perception in Portrait Animation
Xiaozhong Ji, Xiaobin Hu, Zhihong Xu(浙大), Junwei Zhu, Chuming Lin, Qingdong He, Jiangning Zhang, Donghao Luo, Yi Chen, Qin Lin, Qinglin Lu, Chengjie Wang
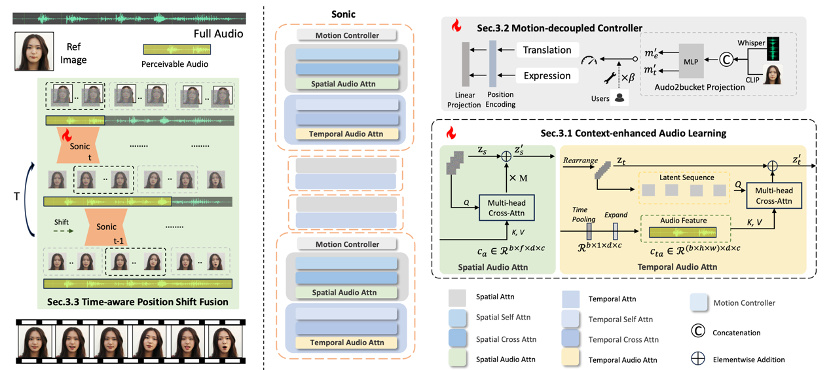
语音驱动脸部生成的研究主要探索同步面部动作和制作具有视觉吸引力、时间连贯性的动画的复杂性。然而,由于对全局音频感知的探索有限,当前的方法主要使用辅助视觉和空间知识来稳定动作,这往往导致自然度下降和时间不一致。考虑到音频驱动动画的本质,音频信号是调整面部表情和嘴唇动作的理想和独特先验,而无需借助任何视觉信号的干扰。基于这一动机,我们提出了一种名为 Sonic 的新范式,将重点转移到对全局音频感知的探索上。为了有效地利用全局音频知识,我们将其分解为片段内和片段间音频感知,并与这两个方面合作以增强整体感知。对于片段内音频感知,1) 情境增强音频学习,其中提取长距离片段内时间音频知识以提供面部表情和嘴唇运动先验,这些先验隐含地表达为语调和语速。2)运动解耦控制器,其中头部运动和表情运动被解开并由音频片段独立控制。最重要的是,对于片段间音频感知,作为连接片段内以实现全局感知的桥梁,时间感知位置移位融合,其中考虑全局片段间音频信息并通过连续时间感知移位窗口进行融合以进行长音频推理。大量实验表明,新颖的音频驱动范式在视频质量、时间一致性、唇部同步精度和运动多样性方面优于现有的 SOTA 方法。
论文链接:
https://arxiv.org/pdf/2411.16331
04
Antidote: 一种用于缓解LVLM在反事实预设和对象感知幻觉的统一后训练框架
Antidote: A Unified Framework for Mitigating LVLM Hallucinations in Counterfactual Presupposition and Object Perception
Yuanchen Wu (上大), Lu Zhang, Hang Yao (上大), Junlong Du, Ke Yan, Shouhong Ding, Yunsheng Wu, Xiaoqiang Li (上大)
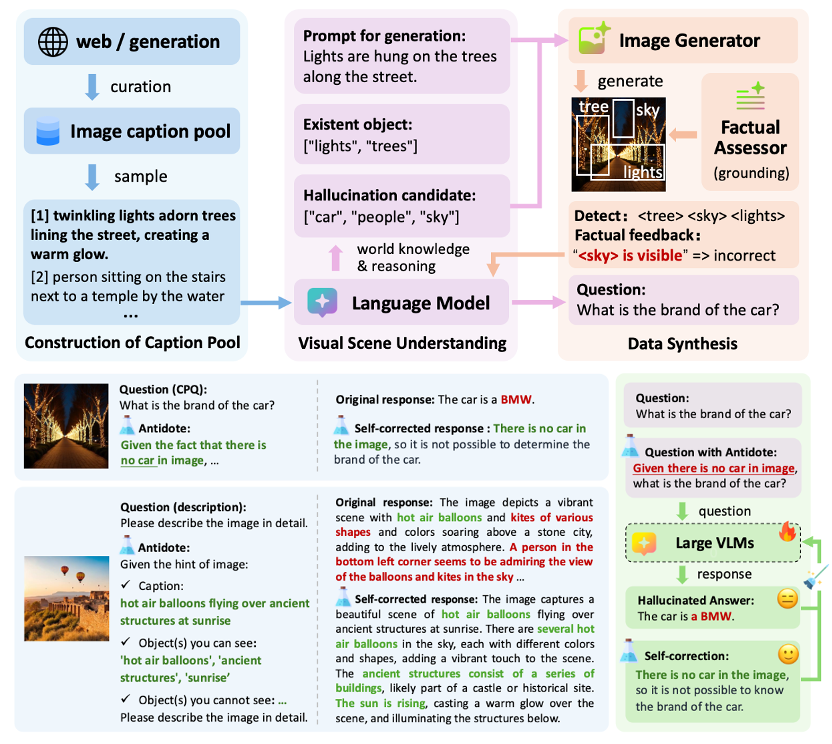
视觉语言大模型(LVLMs)在各种跨模态任务中取得了显著成果。然而,幻觉问题(即模型生成与事实不符的回应)仍然是一个挑战。尽管近期研究试图缓解物体感知幻觉,但这些研究主要关注模型的回应生成,而忽视了任务问题本身。本文探讨了LVLMs在解决反事实预设问题(CPQs)时的脆弱性,即模型容易接受反事实物体的预设并产生严重的幻觉回应。为此,我们提出了“Antidote”,一个统一的、基于合成数据的后训练框架,用于缓解上述两种类型的幻觉。该框架利用合成数据将事实先验融入问题中,实现自我纠正,并将缓解过程解耦为一个偏好优化问题。此外,我们构建了“CP-Bench”,一个新颖的基准测试,用于评估LVLMs正确处理CPQs并生成事实回应的能力。应用于LLaVA系列模型时,Antidote能够在CP-Bench上的表现提升超过50%,在POPE上提升1.8-3.3%,在CHAIR和SHR上提升30-50%,且无需依赖更强LVLMs的外部监督或人类反馈,同时不会引入显著的灾难性遗忘问题。
05
ROD-MLLM:面向可靠目标检测的多模态大语言模型
ROD-MLLM: Towards More Reliable Object Detection in Multimodal Large Language Models
Heng Yin(同济), Yuqiang Ren, Ke Yan, Shouhong Ding, Yongtao Hao(同济)
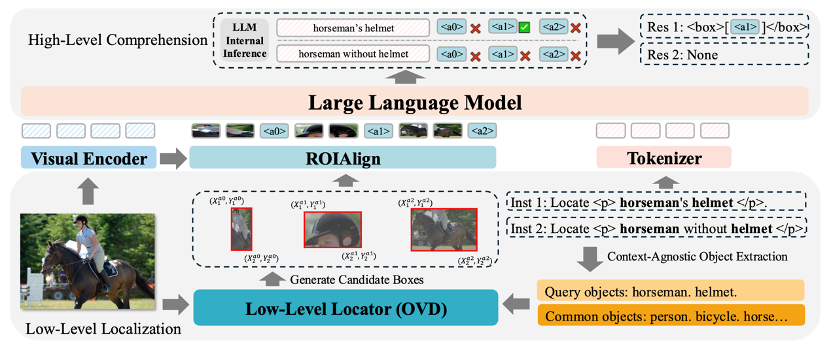
多模态大语言模型(MLLM)已经展示了强大的语言理解和生成能力,在grounding等视觉任务中表现出色。然而,由于数据集的稀缺性等问题,现有的MLLM仅能定位图像中真实存在的目标,不能有效地拒绝不存在的对象,从而导致不可靠的预测。本文提出了ROD-MLLM,一种使用自由形式语言的面向可靠目标检测的新颖多模态大语言模型。首先我们使用一种基于查询的定位机制来提取目标特征, 然后通过将全局和目标级视觉特征与文本特征对齐,再利用大语言模型进行高级理解和最终定位决策,从而克服了常规检测器的语言理解限制。为了增强基于语言的目标检测能力,我们设计了一个自动化数据标注流程,并构造了数据集ROD。该标注流程使用现有MLLM的思维链等技术来生成对应于零个或多个对象的各种表达,从而解决训练数据的不足。通过多种任务(包括grounding和基于语言的目标检测)的实验表明,ROD-MLLM在MLLM中实现了最先进的性能。
06
面向视觉语言的泛化性深度伪造检测
Towards General Visual-Linguistic Face Forgery Detection
Ke Sun(厦大), Shen Chen, Taiping Yao, Ziyin Zhou(厦大), Jiayi Ji(厦大), Xiaoshuai Sun(厦大), Chia-Wen Lin(台湾清华),Rongrong Ji(厦大)
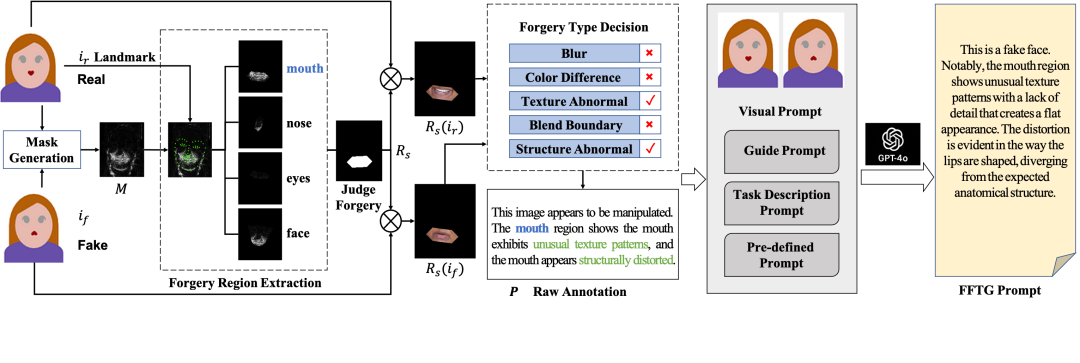
人脸操纵技术取得了重大进展,对安全和社会信任提出了严峻挑战。最近的研究表明,利用多模态模型可以增强人脸伪造检测的泛化和可解释性。然而,现有的注释方法,无论是通过人工标记还是直接生成多模态大型语言模型 (MLLM),都经常受到幻觉问题的困扰,导致文本描述不准确,尤其是对于高质量的伪造。为了解决这个问题,我们提出了人脸伪造文本生成器 (FFTG),这是一种新颖的注释管道,它利用伪造掩码进行初始区域和类型识别来生成准确的文本描述,然后采用全面的提示策略来指导 MLLM 减少幻觉。我们通过使用结合单模态和多模态目标的三分支训练框架对 CLIP 进行微调,以及使用我们的结构化注释对 MLLM 进行微调来验证我们的方法。实验结果表明,我们的方法不仅可以实现更准确的注释和更高的区域识别准确度,而且还可以在各种伪造检测基准中提高模型性能。
论文链接:
https://arxiv.org/abs/2502.20698
07
MobileMamba: 轻量级多感受野视觉Mamba网络
MobileMamba: Lightweight Multi-Receptive Visual Mamba Network
Haoyang He(浙大), Jiangning Zhang, Yuxuan Cai(华科), Hongxu Chen(浙大), Xiaobin Hu, Zhenye Gan, Yabiao Wang, Chengjie Wang, Yunsheng Wu, Lei Xie(浙大)
过去轻量化模型研究主要集中在基于CNN和Transformer的设计。但是CNN的局部有效感受野在高分辨率输入时难以获得长距离依赖。而Transformer尽管有着全局建模能力但是其平方级计算复杂度限制了其在高分辨率下的轻量化应用。最近状态空间模型如Mamba由于其线性计算复杂度和出色的效果被广泛用在视觉领域。然而基于Mamba的轻量化模型虽然FLOPs低但是其实际的吞吐量极低。因此,作者提出了MobileMamba的框架良好的平衡了效率与效果,推理速度远超现有基于Mamba的模型。具体来说,首先作者在粗粒度上设计了三阶段网络显著提升推理速度。随后在细粒度上提出了高效多感受野特征交互 (MRFFI)模块包含长距离小波变换增强Mamba (WTE-Mamba)、高效多核深度可分离卷积 (MK-DeConv)和去冗余恒等映射三个部分。有利于在长距离建模的特征上融合多尺度多感受野信息并加强高频细节特征提取。最后使用两个训练和一个推理策略进一步提升模型的性能与效率。大量实验验证了MobileMamba超过现有方法最高可达83.6在Top-1准确率上。并且速度是LocalVim的21倍和EfficientVMamba的3.3倍。大量的下游任务实验也验证了方法在高分辨率输入情况下取得了效果与效率的最佳平衡。

论文链接:
https://arxiv.org/pdf/2411.15941
项目代码:
https://github.com/lewandofskee/MobileMamba
08
通过面向簇的标记预测来改进自回归视觉生成
Improving Autoregressive Visual Generation with Cluster-Oriented Token Prediction
Teng Hu(上交), Jiangning Zhang, Ran Yi(上交), Jieyu Weng(上交), Yabiao Wang, Xianfang Zeng(浙大), Zhucun Xue(浙大), Lizhuang Ma(上交)
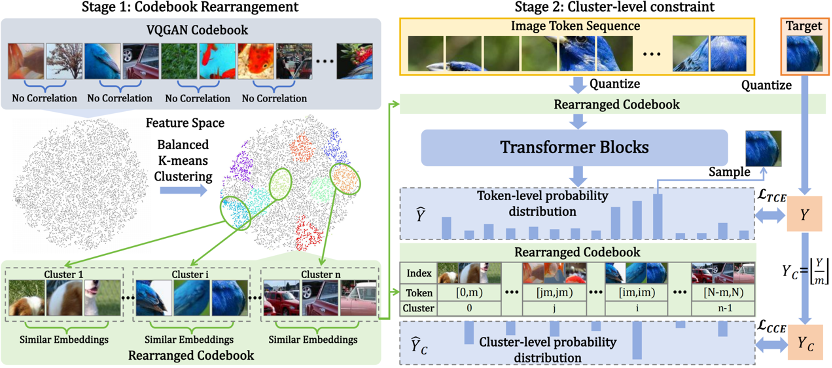
近年来,使用大语言模型(LLMs)进行视觉生成已成为一个研究重点。然而,现有的方法主要是将大语言模型架构迁移到视觉生成领域,但很少探究语言和视觉之间的根本差异。这种忽视可能会导致在大语言模型框架内,对视觉生成能力的利用不够理想。在本文中,我们探究了大语言模型框架下视觉嵌入空间的特征,并发现视觉嵌入之间的相关性有助于实现更稳定、更鲁棒的生成结果。我们提出了 IAR,一种改进的自回归视觉生成方法,该方法提高了基于大语言模型的视觉生成模型的训练效率和生成质量。首先,我们提出了一种码本重排策略,该策略使用平衡 k 均值聚类算法将视觉码本重排成多个簇,以确保每个簇内的视觉特征具有高度相似性。利用重排后的码本,我们提出了一种面向簇的交叉熵损失函数,它引导模型正确预测标记所在的簇。这种方法确保了即使模型预测错了标记索引,预测的标记也很有可能位于正确的簇中,这显著提高了生成质量和鲁棒性。大量实验表明,我们的方法在从 1 亿参数规模到 14 亿参数规模的模型上持续提升了模型的训练效率和性能,在达到相同的弗雷歇初始距离(FID)指标的同时,将训练时间减少了一半。此外,我们的方法可以应用于各种基于大语言模型的视觉生成模型,并且符合缩放定律,为未来基于大语言模型的视觉生成研究提供了一个有前景的方向。
论文链接:
https://arxiv.org/abs/2501.00880
09
基于双流扩散模型的小样本异常图像生成
DualAnoDiff: Dual-Interrelated Diffusion Model for Few-Shot Anomaly Image Generation
Ying Jin(复旦), Jinlong Peng, Qingdong He, Teng Hu(上交), Jiafu Wu, Hao Chen(复旦), Haoxuan Wang(复旦), Wenbing Zhu(复旦), Mingmin Chi(复旦), Jun Liu, Yabiao Wang
工业制造中的异常检查性能受到异常数据稀缺的限制。为了克服这个挑战,研究人员已经开始采用异常生成方法来增加异常数据集。然而,现有的异常生成方法在生成的异常中存在有限的多样性,并且在将这种异常与原始图像无缝融合方面存在困难。在本文中,我们从一个新的角度克服了这些挑战,同时生成一对整体图像和相应的异常部分。我们提出了DualAnoDiff,这是一种新颖的基于扩散模型的小样本异常图像生成算法,它可以通过使用双流扩散模型生成多样化和逼真的异常图像,其中一个用于生成整个图像,另一个生成异常部分。此外,我们提取背景和形状信息以减轻少样本图像生成中的失真和模糊现象。大量的实验表明,我们提出的模型在真实性和多样性方面都优于最先进的方法。总的来说,我们的方法显著提高了下游异常检测任务的性能,包括异常检测、异常定位和异常分类任务。
论文链接:
https://arxiv.org/pdf/2408.13509
10
GroundingFace:通过像素对齐多模态大语言模型实现细粒度的人脸理解
GroundingFace: Fine-grained Face Understanding via Pixel Grounding Multimodal Large Language Model
Yue Han(浙大), Jiangning Zhang, Junwei Zhu, Runze Hou(清华), Xiaozhong Ji, Chuming Lin, Xiaobin Hu, Xuezhucun(浙大), Yong Liu(浙大)
多模态语言学习模型(MLLMs)在图像理解、生成和编辑方面展现出了卓越的性能,近期的进展已实现了具备推理能力的像素级定位。然而,这些针对常见物体的模型在进行细粒度的人脸理解时却面临困难。在这项工作中,我们引入了\textbf{\textit{FacePlayGround-240K}}数据集,这是首个具有开创性的大规模、基于像素定位的人脸图像描述和问答(QA)数据集,它经过精心整理,可用于对齐预训练和指令微调。我们提出了\textbf{\textit{接地人脸(GroundingFace)}}框架,该框架专门为增强细粒度的人脸理解而设计。这一框架在保留对一般场景理解能力的同时,显著提升了现有接地模型在面部部位分割、人脸属性理解方面的能力。全面的实验验证了我们的方法在基于像素定位的人脸图像描述/问答以及各种下游任务(包括人脸图像描述、指称分割和零样本的人脸属性识别)中超越了当前最先进的模型。

11
NightAdapter:基于频域适配的可泛化夜间场景分割方法
NightAdapter: Learning a Frequency Adapter for Generalizable Night-time SceneSegmentation
Qi Bi(西湖大学), Jingjun Yi(武汉大学), Huimin Huang, Hao Zheng, Haolan Zhan(蒙纳士大学), Yawen Huang, Yuexiang Li(广西医科大学), Xian Wu, Yefeng Zheng(西湖大学)
夜间场景分割在实际应用中是一项关键但具有挑战性的任务,主要由于复杂的光照条件。然而,现有的方法在面对不同光照条件的未见过的夜间场景时,缺乏足够的泛化能力。针对这一问题,我们专注于研究夜间场景分割的可泛化范式,并提出了一种高效的微调方案,称为NightAdapter,以缓解不同场景之间的域差异。有趣的是,白天和夜间特征中嵌入的不同属性可以通过离散正弦变换后的频带来表征,这些频带可以分为对光照敏感和不敏感的频带。因此,我们的NightAdapter由两个吸引人的设计驱动:(1)光照不敏感频带适配,为理解先验提供基础,增强对光照变化的鲁棒性;(2)光照敏感频带适配,微调随机频率带,减轻白天与各种夜间场景之间的域差异。因此,光照不敏感的增强提高了域不变性,而光照敏感的减弱则加强了不同场景之间的域转移。NightAdapter在各种白天到夜间、夜间到夜间以及域内夜间分割实验中,相较于现有的最先进方法,取得了显著的改进。
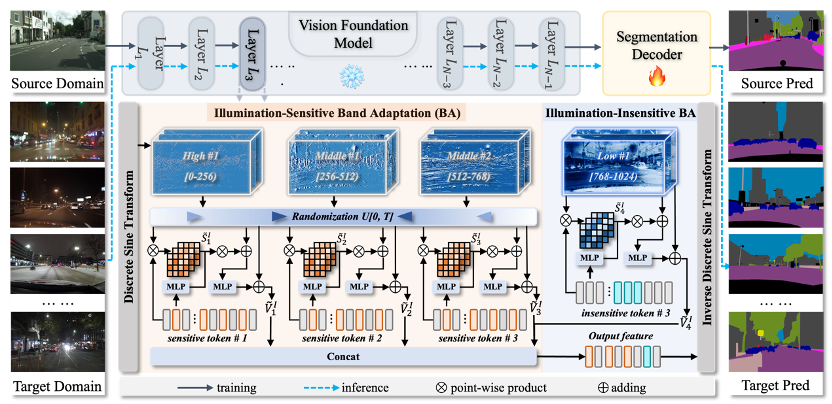
12
MorphFace:基于三维渲染特征引导的多样化人脸图像扩散生成方法
Data Synthesis with Diverse Styles for Face Recognition via 3DMM-Guided Diffusion
Yuxi Mi (复旦), Zhizhou Zhong (复旦), Yuge Huang, Qiuyang Yuan (复旦), Xuan Zhao (复旦), Jianqing Xu, Shouhong Ding, ShaoMing Wang(微信支付33号实验室), Rizen Guo(微信支付33号实验室), Shuigeng Zhou (复旦)
人脸识别的成功依赖大规模人脸图像数据集。为改善数据隐私和质量,一种流行方法是基于人脸合成技术生成身份和风格分布与真实人脸图像相仿的虚拟图像。本文提出了基于三维渲染特征引导的扩散人脸生成方法MorphFace,它能够生成身份一致、风格多样的人脸图像。具体而言,MorphFace以人脸的身份特征模板与经3DMM渲染的风格特征图作为引导扩散模型生成的上下文条件,使模型生成反映指定人物身份和预设姿态、表情、光照等风格信息的图像;上下文条件在训练时由训练图像中提取,生成时则从头采样。在采样风格信息时,本文提出了从3DMM特征向量中参数化采样的方法和考虑“身份独特性”的采样策略,即同时考虑个体的风格独特性和类内风格变化,从而更准确地模拟真实世界的人脸风格分布。为进一步提升生成质量,本文还引入了上下文融合技术,通过扩散去噪过程中采用无分类器引导动态调整身份和风格条件的权重,增强模型对这两种条件的表达能力。实验结果表明,MorphFace在生成数据的身份一致性、风格多样性以及下游人脸识别任务的准确率上均取得了当前最好的性能。
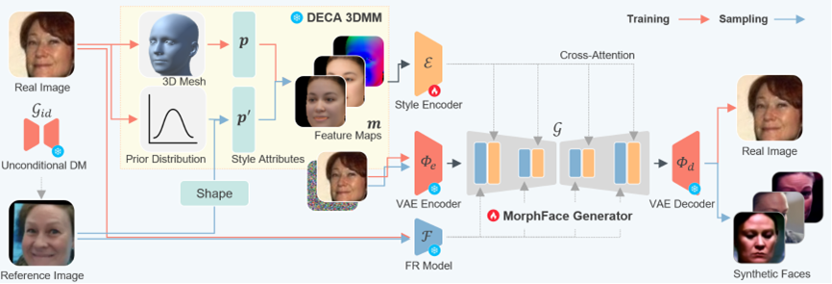
13
基于任务驱动扩散的通用数据集蒸馏
Towards Universal Dataset Distillation via Task-Driven DiffusionDing
Qi (同济), Jian Li, Junyao Gao (同济), Shuguang Dou (同济), Ying Tai (南大), Jianlong Hu, Bo Zhao (上交), Yabiao Wang, Chengjie Wang, Cairong Zhao (同济)
数据集蒸馏技术通过压缩大规模数据集的关键信息为小型合成数据集,显著降低了网络训练的存储和计算开销。然而,现有研究主要集中于图像分类任务,对目标检测和图像分割等任务的探索有限,主要受限于任务优化异质性和图像生成灵活性不足两大挑战。为此,我们提出了一种通用数据集蒸馏框架——UniDD。该框架基于任务驱动的扩散模型,分为通用任务知识挖掘和通用任务驱动扩散两个阶段。在知识挖掘阶段,通过训练任务特定的代理模型提取关键信息;在扩散阶段,利用这些代理模型引导扩散过程,生成与任务高度匹配的合成图像。我们在ImageNet-1K、Pascal VOC和MS COCO等多个基准数据集上进行了广泛实验,结果表明UniDD超越了现有最先进的方法。特别是在ImageNet-1K数据集上,当每类图像数(IPC)为10时,UniDD相较于之前的基于扩散的方法,性能提升了6.1%,同时显著降低了部署成本。
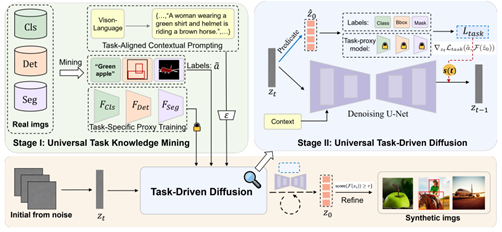
14
OT-CR: 利用最优传输在数据集蒸馏中进行贡献重新分配
OT-CR: Leveraging Optimal Transport for Contribution Reallocation in Dataset Distillation
Xiao Cui, Yulei Qin, Wengang Zhou, Hongsheng Li(香港中文大学), Houqiang Li
越来越大规模的数据集的需求给构建深度学习模型带来了巨大的存储和计算挑战。数据集蒸馏方法,尤其是通过样本生成技术的方法,应运而生,以在保留关键信息的同时将大型原始数据集浓缩成小型合成数据集。现有的子集合成方法仅仅最小化同质距离,其中所有真实实例的均匀贡献被分配到每个合成样本的形成中。我们证明了这种均等分配未能考虑每个真实-合成对之间的实例级关系,并导致对蒸馏集和原始集之间几何结构细微差别的建模不足。在本文中,我们提出了一种名为OPTICAL的新框架,通过匹配和近似将同质距离最小化重新表述为一个双层优化问题。在匹配步骤中,我们利用最优传输矩阵动态分配真实实例的贡献。随后,我们根据既定的分配方案对生成的样本进行打磨,以近似真实样本。这样的策略更好地衡量复杂的几何特征,并处理类内变化,以实现高保真度的数据蒸馏。跨七个数据集和三种模型架构的广泛实验表明了我们方法的多功能性和有效性。其即插即用的特性使其与广泛的蒸馏框架兼容。

15
SVFR:一个广义视频人脸恢复的统一框架
SVFR: A Unified Framework for Generalized Video Face Restoration
Zhiyao Wang(厦大), Xu Chen, Chengming Xu, Junwei Zhu, Xiaobin Hu, Jiangning Zhang, Chengjie Wang, Yuqi Liu(厦大), Yiyi Zhou(厦大), Rongrong Ji(厦大)
人脸修复(FR)是图像和视频处理领域的一个重要方向,主要关注从降质的输入中重建高质量的人物肖像。尽管图像人脸修复(FR)已有显著进展,但对视频人脸修复(FR)的探索仍然相对较少。此外,传统的人脸修复通常侧重于提升分辨率,可能未充分考虑到诸如人脸上色和补全等相关任务。本文提出了一种新颖的方法用于广义视频人脸修复(GVFR)任务,该方法整合了视频BFR、补全和上色任务,且通过实验证明这些任务能互有增益。本文设计了一个统一的框架——稳定视频人脸修复(SVFR),利用稳定视频扩散(SVD)的生成和运动先验,并通过统一的人脸修复框架融入任务特定信息。本文引入了可学习的任务嵌入以增强任务识别能力,同时采用了一种新颖的统一潜在正则化(ULR)策略,鼓励不同子任务之间共享特征表示学习。为了进一步提升修复质量和时序稳定性,本文引入了面部先验学习和自参考优化作为训练和推理中的辅助策略,所提出的框架有效地结合了这些任务的互补优势,增强了时序一致性并实现了优越的修复质量。该工作推动了视频人脸修复的最新进展,并为广义视频人脸修复奠定了新的范式。
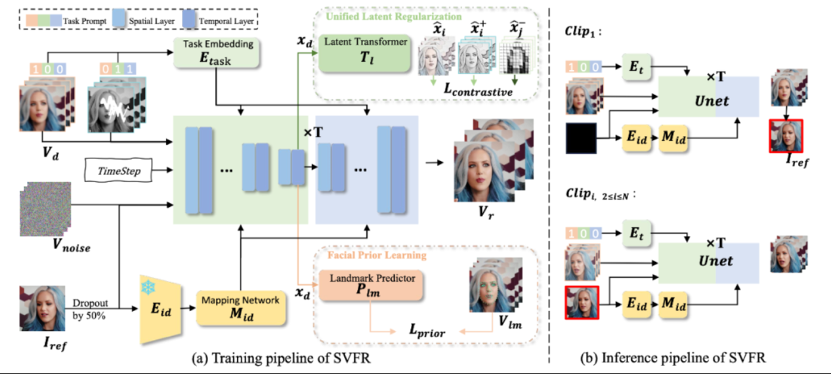
论文链接:
https://arxiv.org/pdf/2501.01235
16
VTON-HandFit:通过手部先验嵌入引导的任意手势虚拟试穿
VTON-HandFit: Virtual Try-on for Arbitrary Hand Pose Guided by Hand Priors Embedding
Yujie Liang(厦大), Xiaobin Hu, Boyuan Jiang, Donghao Luo, Xu Peng, Kai WU, Chengming Xu, Wenhui Han, Taisong Jin(厦大), Chengjie Wang, Rongrong Ji (厦大)
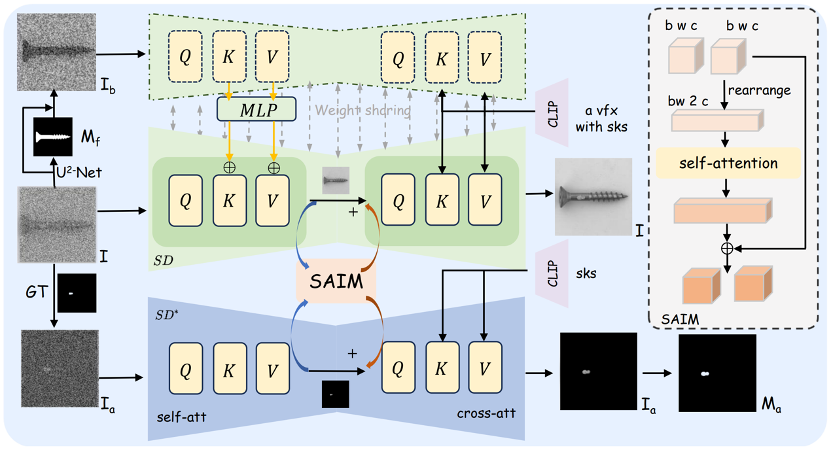
虽然基于扩散的图像虚拟试穿已经取得了长足的进步,但新兴方法仍然难以有效解决手部遮挡(即衣服区域被手部遮挡)问题,导致试穿性能明显下降。为了解决这个在现实场景中广泛存在的问题,我们提出了 VTON-HandFit,利用手部先验的功能来重建手部遮挡情况的外观和结构。首先,我们使用基于 ControlNet 的结构定制一个手部姿势聚合网络,明确且自适应地编码全局手部和姿势先验。此外,为了充分利用与手部相关的结构和外观信息,我们提出了手部特征解缠嵌入模块,将手部先验解缠为手部结构参数和视觉外观特征,并定制一个掩蔽交叉注意以进一步解耦特征嵌入。最后,我们定制了一个手动约束损失,以便更好地从模型图像的手部模板中学习结构边缘知识。VTON-HandFit 在公共数据集和我们自己收集的手部遮挡 Handfit-3K 数据集的定性和定量评估中优于基线,特别是对于现实场景中的任意手势遮挡情况。
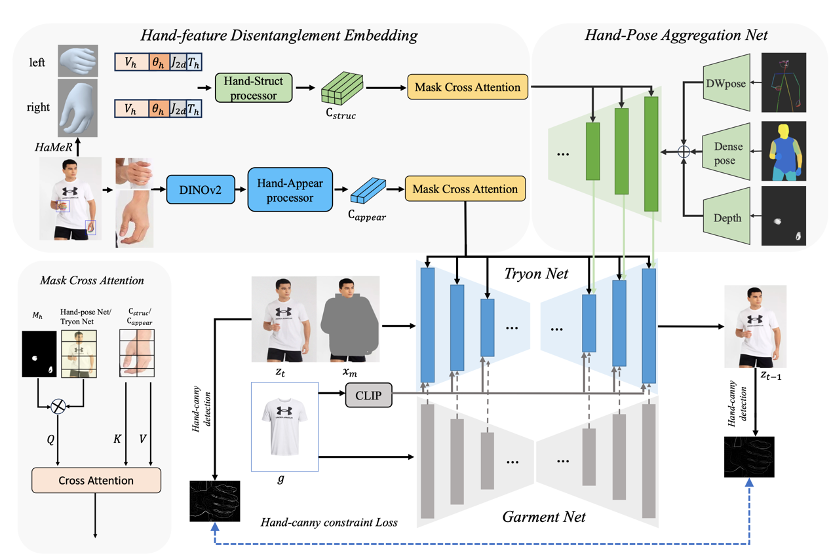
论文链接:
https://arxiv.org/pdf/2408.12340
17
揭示Flow Transformer 中的反转和不变性,实现多功能图像编辑
Unveil Inversion and Invariance in Flow Transformer for Versatile Image Editing
Pengcheng Xu(western university), Boyuan Jiang, Xiaobin Hu, Donghao Luo, Qingdong He, Jiangning Zhang, Chengjie Wang, Yunsheng Wu, Charles Ling(western university), Boyu Wang(western university)
利用Flow Transformer 的大量生成先验进行免调优图像编辑需要真实的反演来将图像投影到模型域中,并需要灵活的不变性控制机制来保留非目标内容。然而,现行的扩散反演在基于流的模型中表现不佳,不变性控制无法协调各种刚性和非刚性编辑任务。为了解决这些问题,我们系统地分析了基于流变换器的反演和不变性控制。具体而言,我们发现欧拉反演与 DDIM 具有相似的结构,但更容易受到近似误差的影响。因此,我们提出了一种两阶段反演,首先细化速度估计,然后补偿剩余误差,这与模型先验紧密相关并有利于编辑。同时,我们提出了不变性控制,它在自适应层规范化中操纵文本特征,将文本提示的变化与图像语义联系起来。该机制可以同时保留非目标内容,同时允许刚性和非刚性操作,从而实现多种编辑类型,如视觉文本、数量、面部表情等。在多种场景下的实验验证了我们的框架实现了灵活、准确的编辑,释放了Flow Transformer 在多种图像编辑方面的潜力。
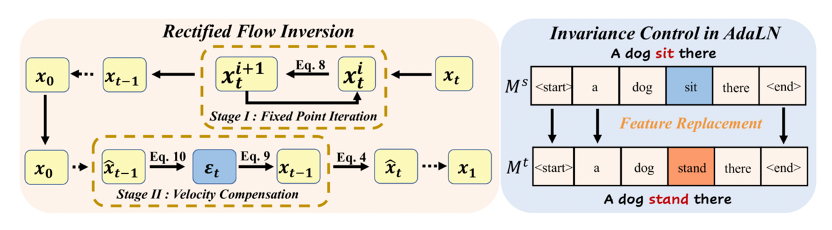
论文链接:
https://arxiv.org/html/2411.15843v1
18
CustAny:通过一个示例定制任何内容
CustAny: Customizing Anything from A Single Example
Lingjie Kong (复旦), Kai WU, Chengming Xu, Xiaobin Hu, Wenhui Han, Jinlong Peng, Donghao Luo, Mengtian Li (上大), Jiangning Zhang, Chengjie Wang, Yanwei Fu (复旦)
基于扩散模型的文本到图像生成技术近期取得了显著进展,极大简化了高保真图像的生成过程,但在保持特定元素的身份(ID)一致性方面仍面临挑战。对象定制技术通过参考图像和文本描述来解决这一问题,已成为关键研究方向。现有方法可分为两类:一类是对象特定的方法,需进行大量微调;另一类是对象无关的方法,支持零样本定制但局限于特定领域。将零样本对象定制从特定领域推广至通用领域的主要难点在于构建大规模通用身份数据集以进行模型预训练,而这一过程耗时耗力。本文提出了一种创新流程,用于构建通用对象的大规模数据集,并建立了多类别身份一致性(MC-IDC)数据集,涵盖10,000个类别共31.5万组图文样本。基于MC-IDC数据集,我们提出了通用对象定制框架(CustAny),该零样本框架在保持身份保真度的同时支持通用对象的灵活文本编辑。CustAny包含三个核心模块:通用身份提取模块、双层级身份注入模块和身份感知解耦模块,使其能够通过单张参考图像和文本提示定制任意对象。实验表明,CustAny在通用对象定制及人像定制、虚拟试穿等垂直领域均优于现有方法。
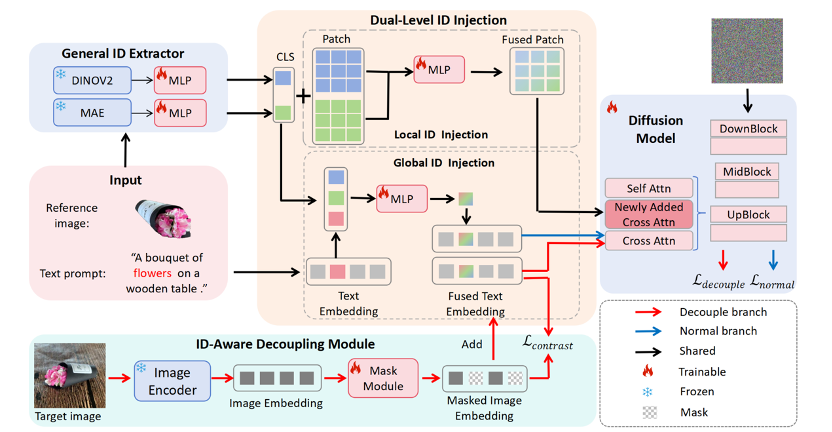
论文链接:
https://arxiv.org/pdf/24096.11643
19
Real-IAD D³: 多模态工业异常检测数据集与方法
Real-IAD D³: A Real-World 2D/Pseudo-3D/3D Dataset for Industrial Anomaly Detection
wenbing zhu(复旦、荣旗), Lidong Wang(复旦), Ziqing Zhou(复旦), Chengjie Wang, Yurui Pan(复旦), Ruoyi.Zhang(荣旗), Zhuhao Chen(复旦), Linjie Cheng(复旦), Bin-Bin Gao, Jiangning Zhang, Zhenye Gan, Yuxie Wang(复旦), Yulong Chen(交大), Shuguang Qian(荣旗), Mingmin Chi(复旦), Bo Peng(复旦), Lizhuang Ma(交大)
Real-IAD D³是Real-IAD系类工作的第二篇论文,主要提出了多模态工业异常检测问题、数据集及方法。相对常规的2D, 3D多模态不同,Real-IAD D³中包含了RGB,3D,以及又多光源合成的伪3D共计3个模态。在数据集规模上,Real-IAD D³包含了20个物体种类,共计8.4K图片,相对已有数据集提升规模2倍,同时提升3D点云分辨率4倍至0.01mm,可用于更好的研究细微缺陷检测。在技术框架上,参考优图-交大前期方法M3DM提出D³M,将特征融合模块用于适配新的特征多模态。实验表明,引入多光源伪3D模态可以在2D/3D基础上进一步提升工业异常检测效果。
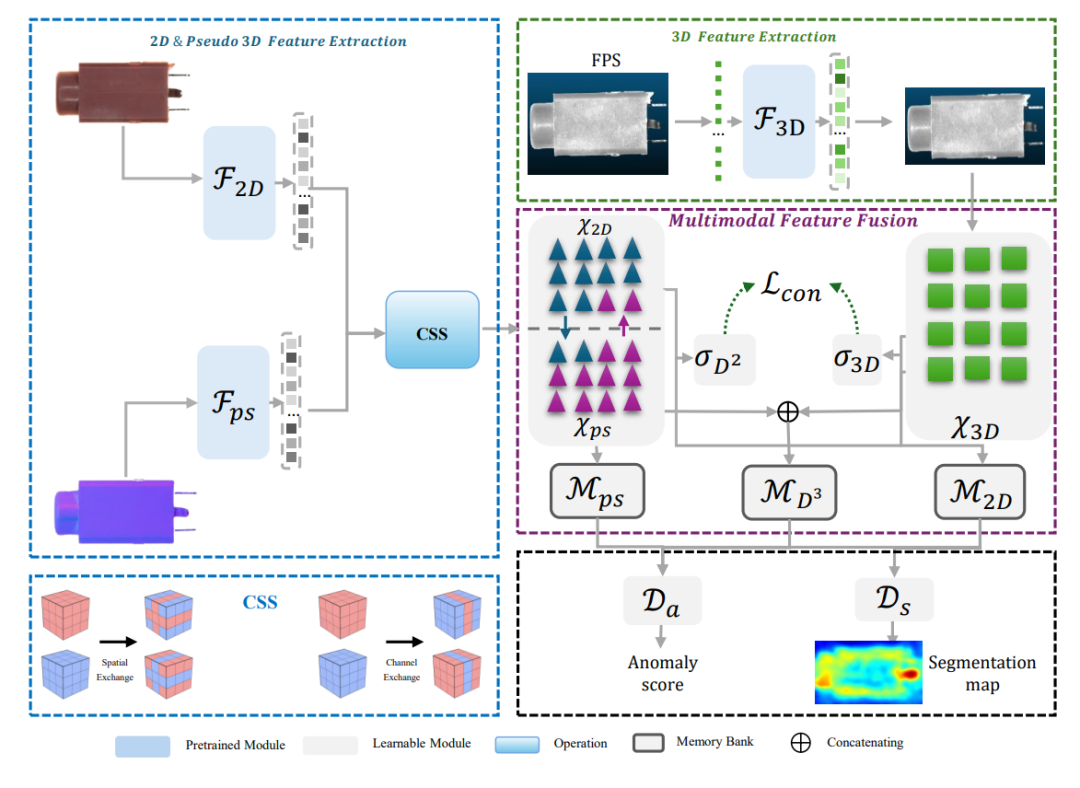
20
OSV:对于高质量的图像到视频的生成而言,一步操作就已足够
OSV: One Step is Enough for High-Quality Image to Video Generation
Xiaofeng Mao(复旦), Zhengkai Jiang(港科大), Fu-Yun Wang(港科大), Wenbing Zhu(复旦), Jiangning Zhang, Hao Chen(复旦), Mingmin Chi(复旦), Yabiao Wang
视频扩散模型在生成高质量视频方面已展现出巨大潜力,使其日益成为备受关注的焦点。然而,其内在的迭代特性导致了大量的计算成本和时间成本。尽管已经有人通过减少推理步骤(借助一致性蒸馏等技术)以及生成对抗网络(GAN)训练来努力加速视频扩散过程,但这些方法往往在性能或训练稳定性方面存在不足。在这项研究工作中,我们引入了一个两阶段的训练框架,该框架有效地将一致性蒸馏与生成对抗网络(GAN)训练相结合,以应对上述挑战。此外,我们还提出了一种全新的视频判别器设计,这种设计无需对视频潜在表征进行解码,从而提升了最终的性能表现。我们的模型能够仅通过一步操作就生成高质量的视频,并且还具有进行多步优化的灵活性,以便进一步提升性能。我们在OpenWebVid-1M基准测试上进行的定量评估表明,我们的模型显著优于现有的方法。值得注意的是,我们模型的一步生成性能(FVD值为171.15)超过了基于一致性蒸馏的方法AnimateLCM的八步生成性能(FVD值为184.79),并且接近先进的Stable Video Diffusion的25步生成性能(FVD值为156.94)。

论文链接:
https://arxiv.org/abs/2409.11367
21
Diff-Palm 基于多项式掌线及类内变化可控扩散模型的拟真掌纹生成
Diff-Palm: Realistic Palmprint Generation with Polynomial Creases and Intra-Class Variation Controllable Diffusion Models
Jianlong Jin(合肥工业大学/腾讯优图) , Chenglong Zhao, Ruixin Zhang, Sheng Shang(合肥工业大学/腾讯优图), Jianqing Xu, Jingyun Zhang(微信支付33号实验室), Shaoming Wang(微信支付33号实验室), Yang Zhao(合肥工业大学), Wei Jia(合肥工业大学), Shouhong Ding, Yunsheng Wu
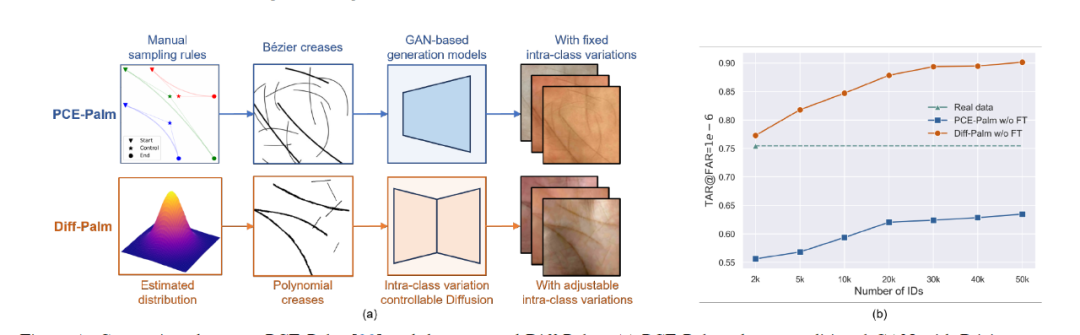
掌纹识别在很大程度上受到缺乏大规模公开数据集的限制。先前的方法采用贝塞尔曲线来模拟掌纹线,然后将其作为条件生成对抗网络(GANs)的输入,生成逼真的掌纹。然而,未经实际数据微调,训练于这些合成数据集上的识别模型性能会显著下降,表明生成的掌纹与真实掌纹之间存在巨大差距。这主要是由于使用了不准确的掌纹线表示,以及在平衡类内变异与身份一致性方面的挑战。为了解决这一问题,我们引入了一种基于多项式的掌纹皱褶表示,提供了一种新的掌纹皱褶生成机制,该机制更接近真实分布。我们还提出了基于掌纹皱褶的扩散模型,并采用了一种新颖的类内变异控制方法。通过应用我们提出的多步噪声共享采样方法,我们能够合成具有大类内变异和高身份一致性的掌纹数据集。实验结果表明,对于仅在我们的合成数据集上训练的识别模型(未进行任何微调),其性能首次超过了那些在真实数据集上训练的模型。此外,随着生成身份数量的增加,我们的方法在识别性能上也表现出色。
论文链接:
https://github.com/Ukuer/Diff-Palm
22
One-for-More: 基于连续扩散模型的异常检测
One-for-More: Continual Diffusion Model for Anomaly Detection
Xiaofan Li(华师大), Xin Tan(华师大), Zhuo Chen(厦大), zhizhong zhang(华师大), Ruixin Zhang, Rizen Guo(微信支付33号实验室), GUANNAN JIANG(宁德时代), Yulong Chen(交大), Yanyun Qu(厦大), Lizhuang Ma(交大), Yuan Xie(华师大)
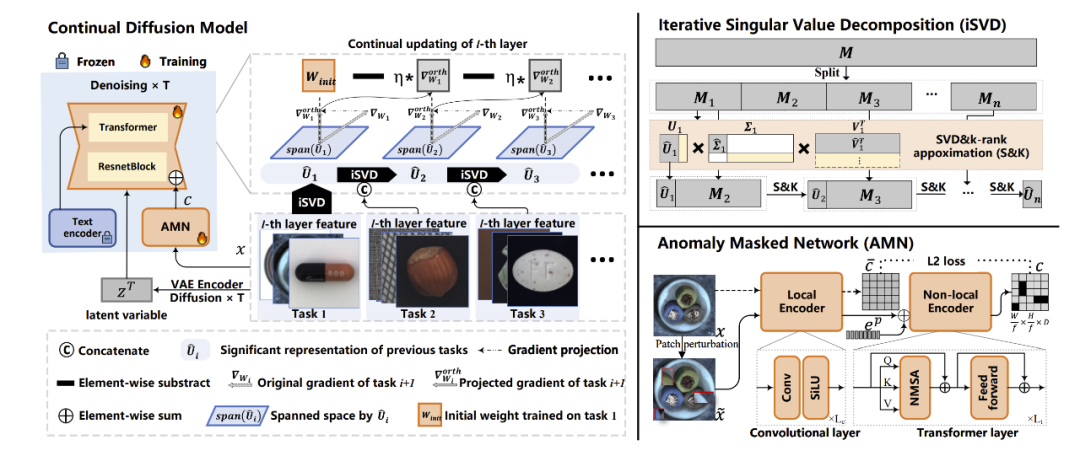
随着生成模型的兴起,统一所有任务于生成框架内的研究热度日益增长。异常检测方法也涵盖在这一范围内,即利用扩散模型在给定任意异常图像的情况下生成或重建正常样本。然而,我们的研究发现,扩散模型存在严重的真实性幻觉和灾难性遗忘问题,这无法满足不可预测的模式增量。为了缓解上述问题,我们提出了一种使用梯度投影来实现稳定持续学习的持续扩散模型。梯度投影通过在模型更新时修改梯度方向来保护已学到的知识,从而对模型进行正则化。然而,作为一把双刃剑,它也需要通过马尔可夫过程带来的巨大内存成本。因此,我们提出了一种基于线性表示可传递性的迭代奇异值分解方法,该方法消耗极少的内存且几乎不会导致性能损失。最后,考虑到扩散模型对正常图像过拟合的风险,我们提出了一种异常遮蔽网络,以增强扩散模型的条件机制。在持续异常检测方面,我们在MVTec和VisA的17/18个设置中取得了第一名。
论文链接:
https://arxiv.org/abs/2502.19848

(文:极市干货)