

本文作者李宏康,博士毕业于美国伦斯勒理工大学,本科毕业于中国科学技术大学,并即将前往宾夕法尼亚大学担任博士后研究员。研究方向包括深度学习理论、大语言模型理论等等。本文的通讯作者为伦斯勒理工大学的汪孟教授。
任务向量(task vector)方法近来在许多视觉和语言任务中表现出了在效率与可迁移性方面的优势。但是由于人们尚未深入理解任务向量的理论机制,其在更广泛与更大规模的应用中面临挑战。
近期,一个来自美国伦斯勒理工大学、密歇根州立大学 OPTML 实验室、和 IBM 研究院的研究团队从神经网络的优化和泛化理论的角度分析了任务向量在模型编辑中的有效性。该工作已经被 ICLR 2025 录取,并被选为前 1.8% 的 Oral 论文。

-
论文标题:When is Task Vector Provably Effective for Model Editing? A Generalization Analysis of Nonlinear Transformers
-
论文地址:https://openreview.net/pdf?id=vRvVVb0NAz
背景介绍
任务向量(task vector)是指微调得到的模型与预训练模型之间的权重差值。人们发现,将不同的任务向量进行线性算术运算后叠加在一个预训练模型上可以直接赋予此模型多种全新的能力,例如多任务学习(multi-task learning)、机器遗忘(machine unlearning)、以及分布外泛化(out-of-domain generalization),其优势是无需使用下游任务的训练数据对模型进行微调。
这种基于任务向量的直接运算对模型进行编辑从而做下游任务预测的方法被称为任务运算(task arithmetic)。
由于缺乏对该方法的理论研究,本文重点探索任务向量方法能够被有效且高效使用的深层原因。我们的贡献如下:
-
我们为任务加法和减法运算的有效性提供了一个特征学习的理论分析框架。
-
我们给出了任务运算在分布外泛化的理论保证。
-
解释了任务向量的低秩近似和模型剪枝的理论机制。
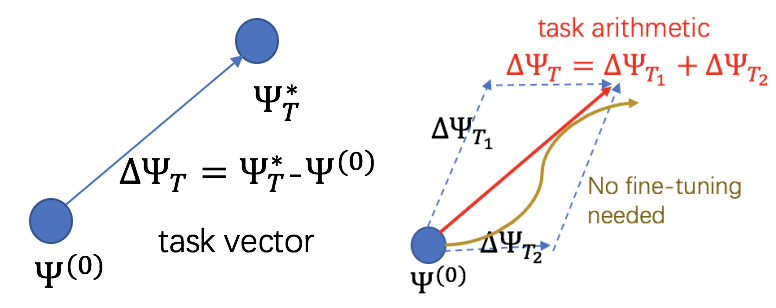
初步观察
我们从一个简单的问题出发:组合多个任务向量的系数会受到哪些因素的影响?
直觉告诉我们,任务间的关系可能是一个关键因素。比如说,在多任务学习中,让一个模型具备两个相似任务的能力,理应是更容易的。
为了论证这一点,我们用 Colored-MNIST 数据集构建了一组二分类实验。其中,分类的标准是数字的奇偶性。我们通过调整数字的颜色来控制任务之间的关系。
于是,我们设计了「相似任务」(aligned tasks)、「无关任务」(irrelevant tasks)、「相反任务」(contradictory tasks) 的任务关系。


根据上图所示的实验结果,我们有以下观察:
-
在多任务学习和机器遗忘的实验中,最佳的任务运算系数会随着给定的任务向量间的关系的不同而改变。
-
在分布外泛化的实验中,目标任务与给定任务的正反相关性可以被最佳的任务运算系数的正负性反映出来。
以上的两点发现引向了一个重要的研究方向:任务关系会如何影响任务运算。
理论分析
我们在二分类问题的设定下研究该问题。我们以一层单头的带有 softmax attention 的 Transformer 为理论分析的基本模型,用 Ψ 来表示所有权重参数的集合,其中包括 attention 层的参数 W 以及 MLP 层的参数 V。仿照许多特征学习(feature learning)的理论工作,我们做如下的数据建模:定义 μ_T 为当前任务的 discriminative pattern。数据 X 中的每一个 token 都是从 μ_T、-μ_T 以及无关的 pattern 中选择的。如果对应于 μ_T 的 token 个数多于 -μ_T 的个数,那么 X 的标签 y=1。如果对应于 -μ_T 的 token 个数多于 μ_T 的个数,那么 X 的标签 y=-1。
接下来我们给出使用两个任务向量进行多任务学习和机器遗忘的理论结果。
具体而言,给定预训练模型 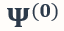 以及两个已经被训练到可以取得 ϵ 的泛化误差的模型所对应的任务向量
以及两个已经被训练到可以取得 ϵ 的泛化误差的模型所对应的任务向量 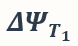 和
和 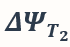 ,融合得到的模型被计算为
,融合得到的模型被计算为 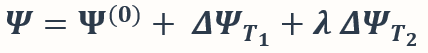 。我们定义
。我们定义 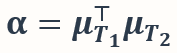 表示任务 T_1 与 T_2 之间的相关性。α>0,=0,<0 分别表示任务之间的相似、无关、以及相反关系。β 为一个很小的数值。那么我们有以下结果:
表示任务 T_1 与 T_2 之间的相关性。α>0,=0,<0 分别表示任务之间的相似、无关、以及相反关系。β 为一个很小的数值。那么我们有以下结果:

定理 1 的结果表明:当两个任务是相似的关系的时候,将任务向量叠加可以得到理想的多任务学习性能,即泛化误差在两个任务上都达到 ϵ。
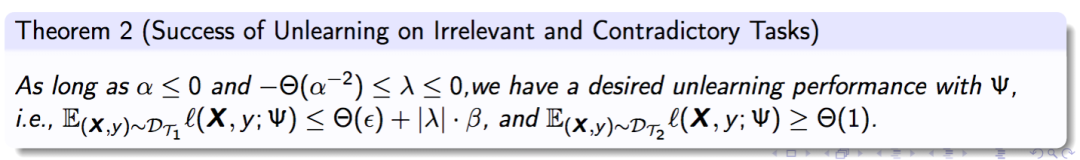
定理 2 的结果表明:当两个任务是相反关系时,用 T_1 的任务向量减去 T_2 的任务向量可以得到理想的机器遗忘性能,即 T_1 的泛化误差达到ϵ,而 T_2 的泛化误差较大。
然后,我们给出利用一组任务向量 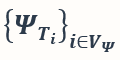 对一个从未见过的分布外的目标任务 T’进行预测的理论结果。我们假设所有给定任务 T_i 的 discriminative pattern 互相正交,目标任务 T’ 的 discriminative pattern 可以被写为各个给定任务的 discriminative pattern 的线性组合,并以 γ_i 为第 i 个任务的 discriminative pattern 的系数。假设 γ_i 不全为 0。我们有定理 3 的结果:
对一个从未见过的分布外的目标任务 T’进行预测的理论结果。我们假设所有给定任务 T_i 的 discriminative pattern 互相正交,目标任务 T’ 的 discriminative pattern 可以被写为各个给定任务的 discriminative pattern 的线性组合,并以 γ_i 为第 i 个任务的 discriminative pattern 的系数。假设 γ_i 不全为 0。我们有定理 3 的结果:

定理 3 的结果表明:总是存在一组 λ_i,使得融合多个任务向量得到的模型可以在目标任务 T’ 上取得理想的泛化性能。
我们还在理论上论证了对任务向量进行高效应用的方法。在我们的一层 Transformer 以及二分类问题的框架下,我们得出了推论 1:任务向量可以被低秩近似,同时只会造成很小的预测误差。这意味着人们可以将各种低秩训练和推断方法用在任务向量中,从而大大节省任务向量的计算和存储开销。
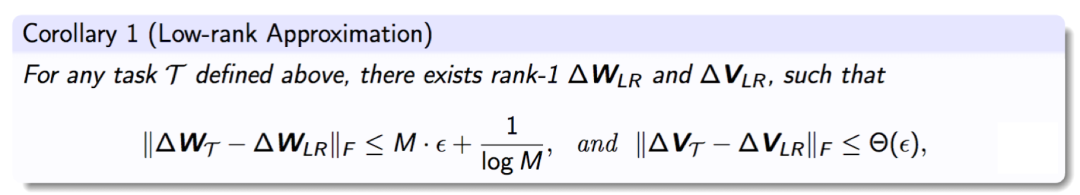
我们还可以得到推论 2:训练得到的任务向量在 MLP 层中的部分神经元权重较大,而剩余的神经元权重很小。对这些小的神经元进行剪枝只会引起很小的误差,从而使得前面所有定理依然成立。这个推论为对于任务向量进行权重剪枝与稀疏化提供了理论保障。

实验验证
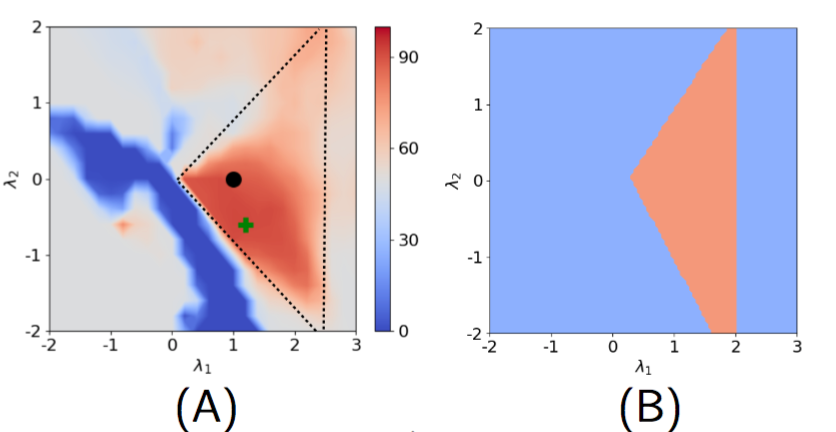
我们首先用 ViT-small/16 模型对任务向量的分布外泛化能力进行了测试。我们使用 Colored-MNIST 数据集设计训练任务 T_1,T_2,以及目标测试任务 T’,用训练任务的任务向量合成一个模型,即  。我们对 T’分别与 T_1,T_2 之间的相关性 γ_1,γ_2 进行了估计。
。我们对 T’分别与 T_1,T_2 之间的相关性 γ_1,γ_2 进行了估计。
我们下图的结果表明:实验中得到的能够带来出色的分布外泛化性能的 λ_1,λ_2 区域(图 A 的红色部分)与定理 3 中证明得到的(图 B 的红色部分)一致。
我们接下来用 Phi-3-small (7B) 模型对任务向量在机器遗忘中的表现进行验证,所使用的数据集为《哈利波特 I》(HP1),《哈利波特 II》(HP2),《傲慢与偏见》(PP)。其中,由于出自相同的作者 J.K. 罗琳,《哈利波特 I》与《II》的语义相似度较高,而《傲慢与偏见》与另外两个数据集不太相似。
下表的结果展示了使用从《哈利波特 I》训练得到的低秩任务向量  构建模型
构建模型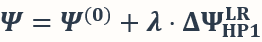 对三个数据集进行机器遗忘的表现。我们发现通过叠加反向的(λ<0)任务向量,新模型在相似任务上也可以取得很好的遗忘效果,而在不相似任务上的遗忘效果较差。
对三个数据集进行机器遗忘的表现。我们发现通过叠加反向的(λ<0)任务向量,新模型在相似任务上也可以取得很好的遗忘效果,而在不相似任务上的遗忘效果较差。

总结
本文定量证明了如何根据任务间关系确定任务运算系数,从而实现理想的多任务学习、机器遗忘、以及分布外泛化的方法,解释了使用低秩和稀疏任务向量的可靠性。本文的理论通过实验得到了验证。
©
(文:机器之心)