

AI自我进化,无需人工标注的强化学习来了!
过去,训练模型就像教小孩做题——必须提前准备好标准答案(标注数据)。但现实中,许多任务根本没有现成答案,比如解一道全新的奥数题。如何让AI在没有答案的情况下自我提升?
论文:TTRL: Test-Time Reinforcement Learning
链接:https://arxiv.org/pdf/2504.16084
这篇论文提出的TTRL(Test-Time强化学习) 给出了答案:让AI自己生成答案,通过“投票”选出共识,再用共识作为奖励信号驱动学习。简单来说,就是让AI“自己出题、自己批改、自己进步”。
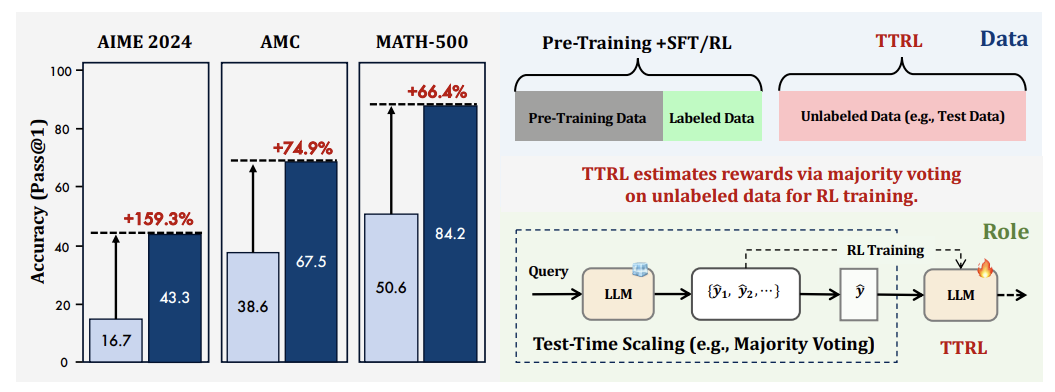
TTRL是什么?
第一步:疯狂刷题
面对一个问题(比如数学题),LLM先用当前能力生成N个答案(比如64个),相当于“多思考几种解法”。
第二步:民主投票
统计所有答案中出现次数最多的结果,作为“参考答案”。这一步类似“群众的眼睛是雪亮的”——多数人认可的答案更有可能是正确的。
第三步:自我奖励
根据生成的答案是否与“参考答案”一致,给AI打分:
-
匹配:奖励+1(鼓励正确行为) -
不匹配:奖励0(提示改进)
即:
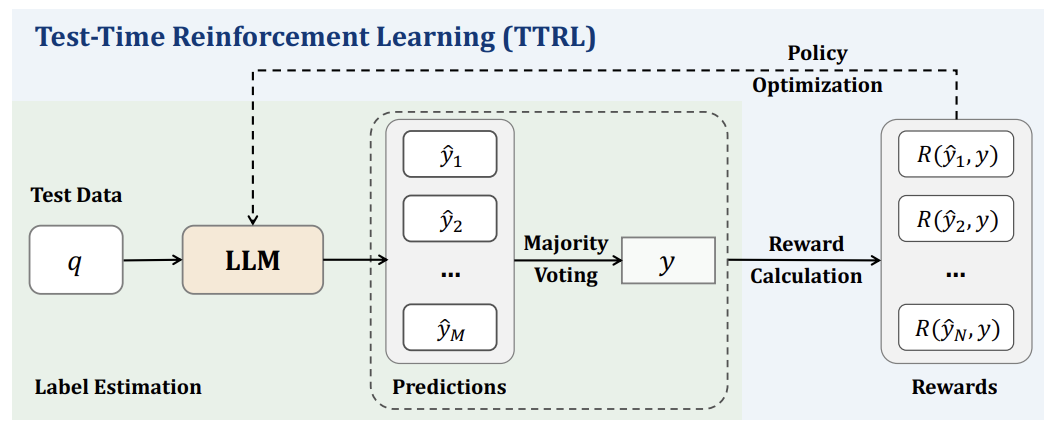
实验:数学题正确率飙升159%,模型越用越聪明
论文在多个数学推理任务上测试TTRL,结果惊人:
-
Qwen2.5-Math-7B模型在AIME奥数题上的正确率从13.3%提升到43.3%,涨幅159%! -
即使没有标注数据,TTRL训练后的模型表现接近“作弊模式”(直接用标注数据训练的效果)。
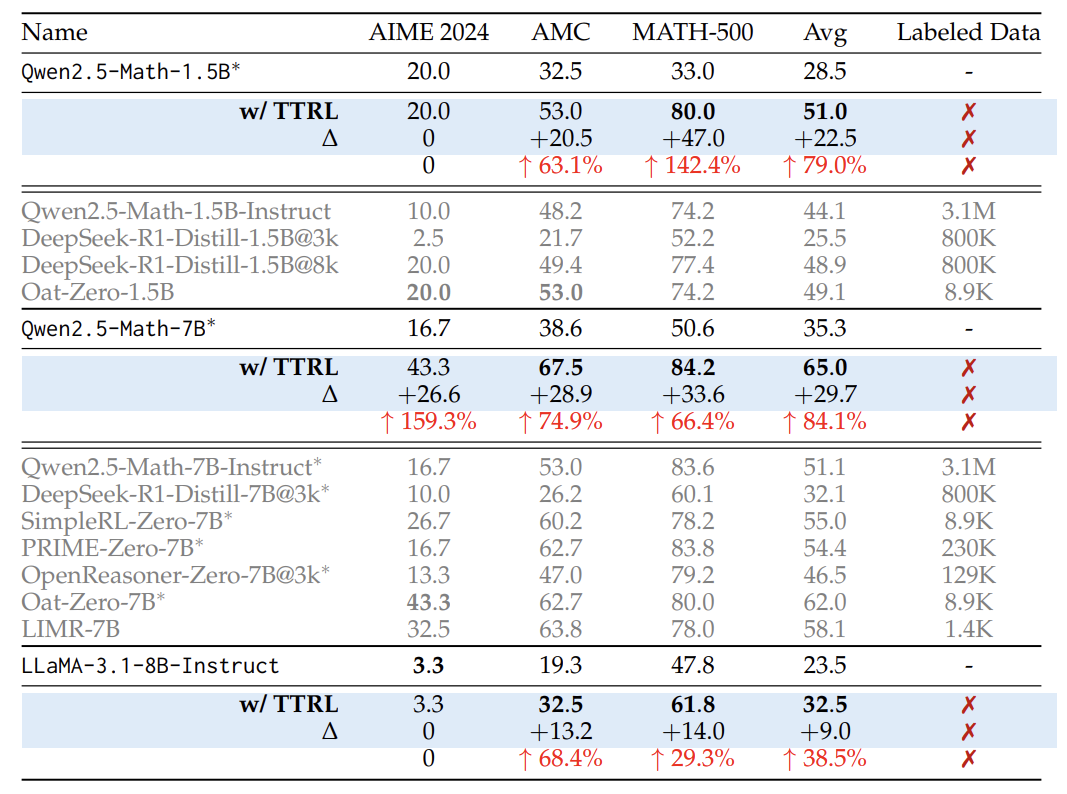
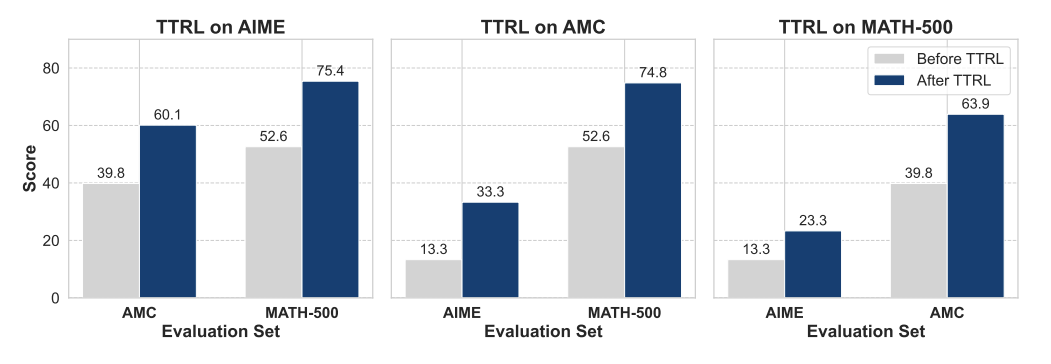
更厉害的是:
-
模型越大,提升越明显(7B模型 > 1.5B模型),说明“学霸越学越强”。 -
TTRL学到的能力可以跨任务迁移,不会“偏科”。
为什么TTRL有效?
关键一:奖励信号更“宽容”
即使投票选出的“参考答案”是错的,只要AI生成的答案与它不一致,也能获得正确反馈。比如:
-
参考答案是错的,但AI生成了另一个错误答案 → 奖励0(正确惩罚) -
参考答案是错的,但AI碰巧答对了 → 奖励1(意外鼓励)
关键二:模型先验知识是基础
TTRL依赖模型已有的知识(比如数学公式理解能力)。如果模型太“笨”(如1.5B小模型),可能连投票都选不出靠谱答案,导致学习失败。
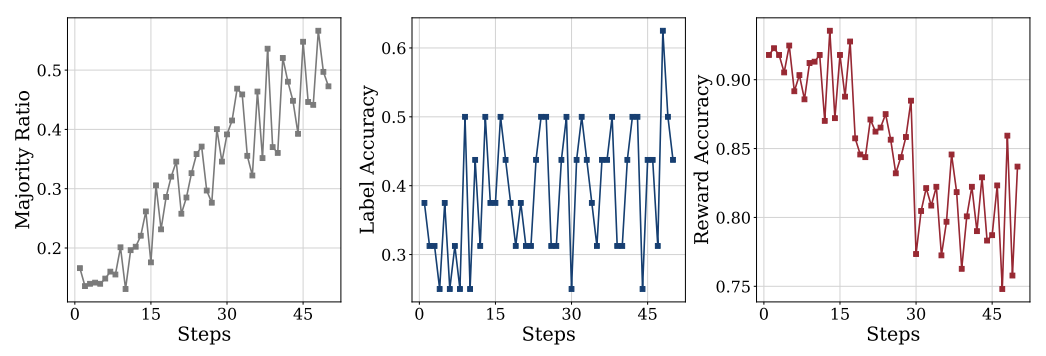
TTRL的局限性:模型太“笨”可能学不会
局限性一:学渣带不动
如果模型本身知识储备不足(比如LLaMA-8B在奥数题上正确率仅3.3%),TTRL也无法帮它逆袭。
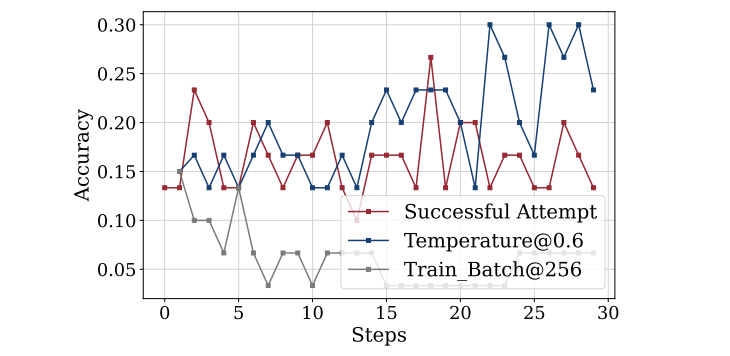
局限性二:超参数敏感
学习率、采样温度等参数需要精心调整。例如:
-
温度太高 → 答案太随机,投票结果混乱 -
温度太低 → 答案缺乏多样性,投票失去意义
未来展望
TTRL的潜力远不止数学题:
-
在线学习:让模型在用户交互中实时进化(比如客服机器人越聊越聪明)。 -
科学探索:自主设计实验、分析结果,加速科研发现。 -
无标注场景:医疗诊断、法律咨询等缺乏标准答案的领域。
论文作者也提出了下一步方向:
-
理论证明TTRL的收敛性 -
结合课程学习,让模型从易到难逐步进阶
总结:一场无声的AI进化革命
TTRL的核心价值在于:打破标注数据的枷锁,让AI真正“自主学习”。虽然目前主要用于数学推理,但其方法论可能重塑AI的训练范式。未来,我们或许会看到更多“越用越聪明”的模型,悄然改变各行各业。
(文:机器学习算法与自然语言处理)