
-
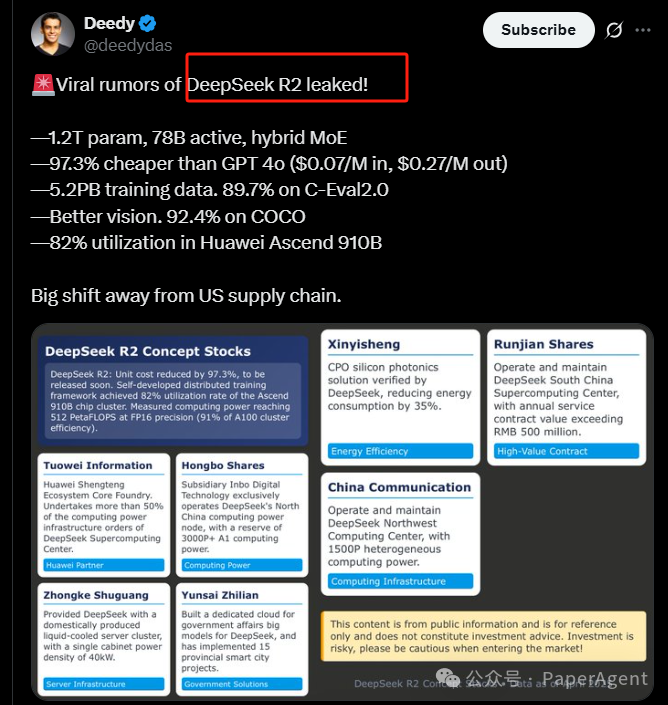
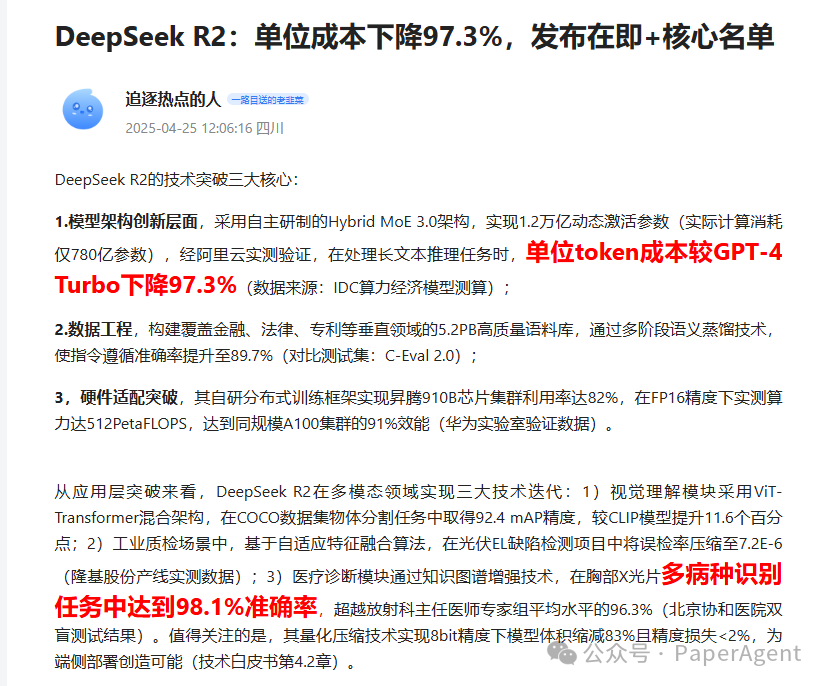
1.2T参数,78B激活,混合MoE架构
-
比GPT-4o便宜97.3%(每百万输入0.07美元,每百万输出0.27美元)
-
5.2PB训练数据,在C-Eval 2.0上达到89.7%的准确率
-
更好的视觉能力,在COCO数据集上达到92.4%的准确率
-
在华为昇腾910B芯片上达到82%的利用率

https://www.jiuyangongshe.com/a/1h4gq724su0
(文:PaperAgent)
1.2T参数,78B激活,混合MoE架构
比GPT-4o便宜97.3%(每百万输入0.07美元,每百万输出0.27美元)
5.2PB训练数据,在C-Eval 2.0上达到89.7%的准确率
更好的视觉能力,在COCO数据集上达到92.4%的准确率
在华为昇腾910B芯片上达到82%的利用率
https://www.jiuyangongshe.com/a/1h4gq724su0
(文:PaperAgent)