
“ 数据召回是RAG技术的重要领域,而不同的召回策略甚至会产生完全不同的效果。”
RAG技术的核心原理很简单,本质上就是在外部维护一个资料库,在进行大模型问答之前,先从资料库中找到相关的内容,然后一起输入到大模型中。
但由于文档的复杂性,在进行文档处理时很难真正做到高质量的数据处理;因此,在做数据召回时就会面临着各种各样的问题。
所以,怎么进行高质量的数据召回,就成为RAG必须要研究的一个课题;而今天,我们就来简单介绍一下常见的几种召回策略。
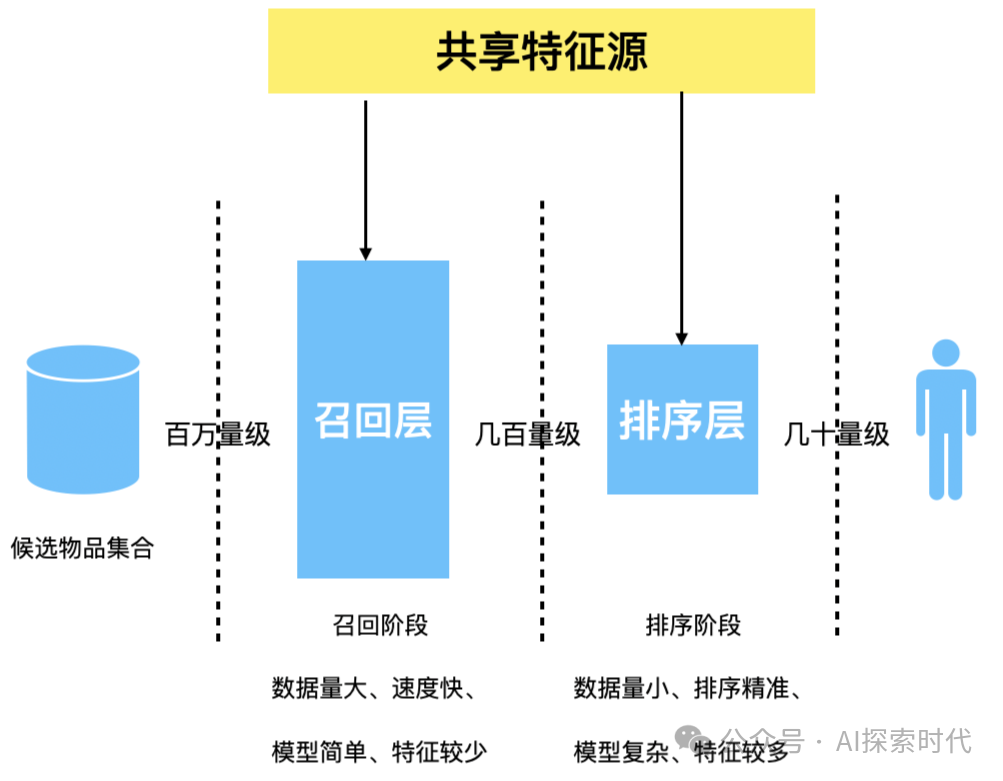
召回策略
RAG的难点主要有两个,一个是前期的文档处理;其次就是数据的召回;由于大模型本身无法分辨输入到模型中的文档质量,因此关于数据的召回只能进行人为的控制,而人为控制的方法只能通过技术手段来进行约束。
因此,在不考虑前期文档处理的情况下,RAG应用中最重要的一点就是解决数据召回的问题。
召回的本质其实很简单,就是快速准确地从外部资料库中找到与问题相关的数据;比如说,用户的问题是怎么学习人工智能?
然后就需要从大量的外部数据中快速找到与人工智能相关的内容,包括,书籍,视频,论文等多种不同的形式。
举例来说,以目前世界上现存的知识体系为例;涉及的领域没有一千也有八百;而一个人不可能什么领域都能涉及,什么领域都懂;因此,如果有一个人想快速入门一个领域应该怎么办?
首先,他可以通过互联网搜索任何他想从事的领域的内容资料;但现在的问题是,世界上的资料,文档那么多,搜索引擎怎么知道怎么找到与之相关的数据?
这就是搜索引擎要解决的事情,而RAG需要解决的也是这个事情。

RAG是基于神经网络模型做的语义性检索,因此其与传统的字符匹配方式检索有很大的区别,比较直观的体现就是向量计算;因此基于RAG系统有专门的向量数据库进行向量检索。
当然,并不是说RAG只能使用向量数据库,RAG的本质是快速找到相关数据,但RAG不会在意你的数据是使用向量数据库存储还是传统的关系数据库存储。也就是说RAG和数据持久化是无关的,或者说数据持久化只是RAG的一部分。
召回策略
关于RAG的召回策略有多种实现方式,最简单的就是基于传统的字符匹配和搜索技术,以及目前比较火的语义检索方式——向量计算。
什么是语义检索?
所谓的语义就是指,你不但要听到我所说的话,你还要能听懂我所说的意思。
比如说,问你吃饭了吗?这可能只是一种问候语,也可能是他想请你吃饭,顺便聊聊天,在不同的环境下其语义是不同的。
RAG的主要召回策略有以下几种:
-
基于传统的字符匹配和分词检索
-
基于向量计算的语义检索
-
数据重排技术——Rerank
-
问题拆分技术
-
多路召回

基于传统的字符匹配和分词检索
在大模型出现之前,搜索引擎主要采用的就是字符匹配和分词技术;常见的技术载体就是关系型数据库和ES这种分词检索工具。
在某些业务场景下,RAG依然会使用这些技术,原因就在于其技术体系比较成熟,解决方案也比较完善,并且效果也不错。
基于向量计算的语义检索
基于向量计算的语义检索,常见的就是向量数据库或者支持向量计算的传统关系型数据库;其本质是通过Embedding(嵌入)模型,把文本转化成向量,然后通过欧式距离或余弦计算等方式,计算其相似度。
数据重排技术——Rerank
数据重排也是基于向量计算的一种方式,其原理是通过把第一步检索到的结果通过重排技术,找到其“分数”也就是相似度最高的数据。
举例来说,你搜索孙悟空,可能会得到很多与之相关的内容,比如说介绍四大名著的内容,介绍三打白骨精的内容,亦或者大闹天宫的内容;
而你想了解的可能只是大闹天宫,或者三打白骨精,这时介绍四大名著的内容可能就不需要了。
而通过重排序就可以实现召回数据的二次筛选,达到更加精确的数据匹配。
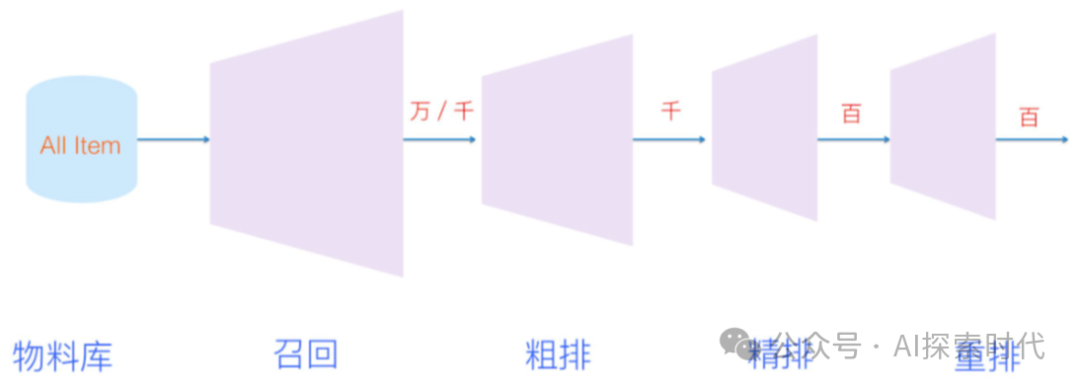
问题拆分技术
问题拆分原理很简单,本质上就是利用大模型来分析你的问题,然后给出几个相似的问题;然后通过这几个相似问题去进行召回,这样就可以提高召回数据的精度。
比如说,用户问题是我想去旅游,你有什么建议吗?
这时大模型就可以根据这个问题帮你拆分几个相似性的问题;比如说,我想去一个风景优美的地方;我想找个地方放松一下心情;亦或者我想去看看祖国的大好河山。
通过问题拆分的方式,用户就可以得到多个相似性的问题,这样就可以从更多的维度去向量数据库或者其它地方召回更多相关的问题;之后再通过重排序技术,来找到其中最相关的内容。
多路召回
多路召回的原理也很简单,就是通过多种不同的策略,或者模型或渠道,检索出多个与之相关的内容;其有点类似于问题拆分的思想,但区别是问题拆分是从问题入手,而多路召回是从检索策略或检索途径入手。
举一个比较形象的例子就是,如果你想了解某个行业;你可以选择从公网上查找数据,也可以选择找专门的行业论坛或社区了解内容;还可以通过找专业人士交谈来了解。
而这种通过多种不同的方式,以及不同的渠道进行数据召回的方式就是多路召回。
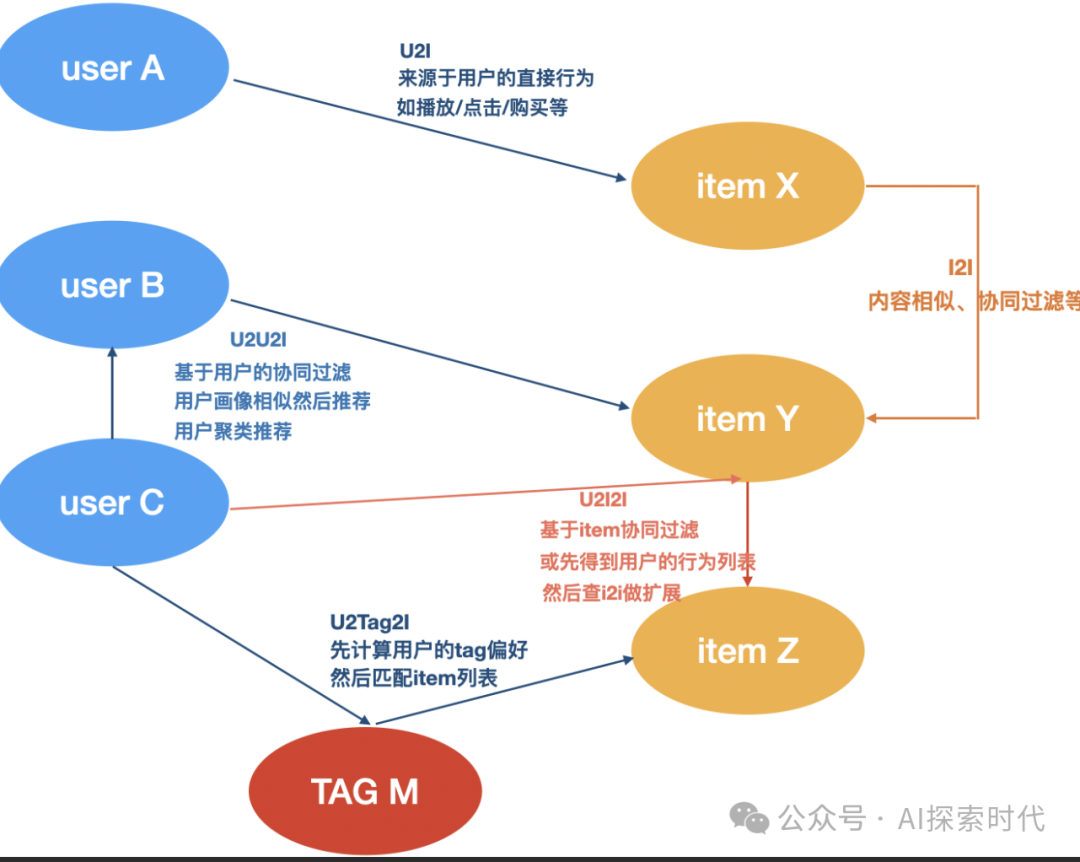
当然,召回技术并不仅仅只限于RAG领域,在传统的搜索引擎领域,召回技术同样扮演着重要角色;因此,RAG技术也同样可以应用于搜索引擎领域。
当然,这里仅仅只是介绍一下简单的,比较常见的召回策略;在RAG的具体实践中,在不同的场景下也会存在一些特殊的召回方式和策略;比如说数据分类,建立索引等方式,以及知识图谱等新型技术。
最重要的是,你要理解这些召回方式并不是互斥的;在很多场景下都是把这些策略进行组合使用,以此达到更加精准的召回质量;特别是在大数据量的情况下,完全基于向量相似度计算的方式,其对算力和响应的要求,是不被允许的。
因此,在大数据量的情况下,先进行快速的非精确匹配,然后再进行更加精确的相似度计算是一种常见的召回方式。
(文:AI探索时代)