

在复杂推荐场景中,多任务联合优化面临 “联合训练耗时冗长、新任务泛化能力差” 的低效困境,行业亟待突破性解决方案。
北京邮电大学-腾讯联合提出两阶段多任务提示调优框架 MPT-Rec,精准攻克知识迁移中任务无关性难题:通过两阶段解耦和多任务提示调优机制,大幅降低任务无关噪声干扰对新任务的负面影响,实现新任务训练效率提升,新任务泛化性能显著增强。
两阶段多任务提示调优框架 MPT-Rec 仅用 10% 的训练参数超越全参训练学习的性能,为多任务推荐系统打破 “性能 – 效率” 双瓶颈提供了前沿思路,研究成果被 CCF-A 类顶刊 TOIS接收。

论文标题:
Efficient Multi-task Prompt Tuning for Recommendation
论文链接:
https://doi.org/10.48550/arXiv.2408.17214
代码仓库:
https://github.com/BAI-LAB/MPT-Rec

引言
随着业务场景的不断拓展,真实的推荐系统在应对多任务学习框架中不断涌现的新任务时,面临着诸多挑战。本文旨在提升多任务推荐在处理新任务时的泛化能力。
如图 1 所示,我们发现,在多数多任务学习方法中,联合训练虽能提升新任务的性能,却总会对现有任务造成负面影响。此外,全面重新训练的机制不仅增加了训练成本,还限制了多任务推荐模型的泛化效率。
我们的目标是合理设计不同任务间的共享机制,在提高新任务学习效率的同时,维持模型处理已有任务的性能。我们提出了一种创新的两阶段任务提示调优多任务学习框架(MPT-Rec),以解决推荐系统中新任务的泛化问题和多任务训练效率问题。
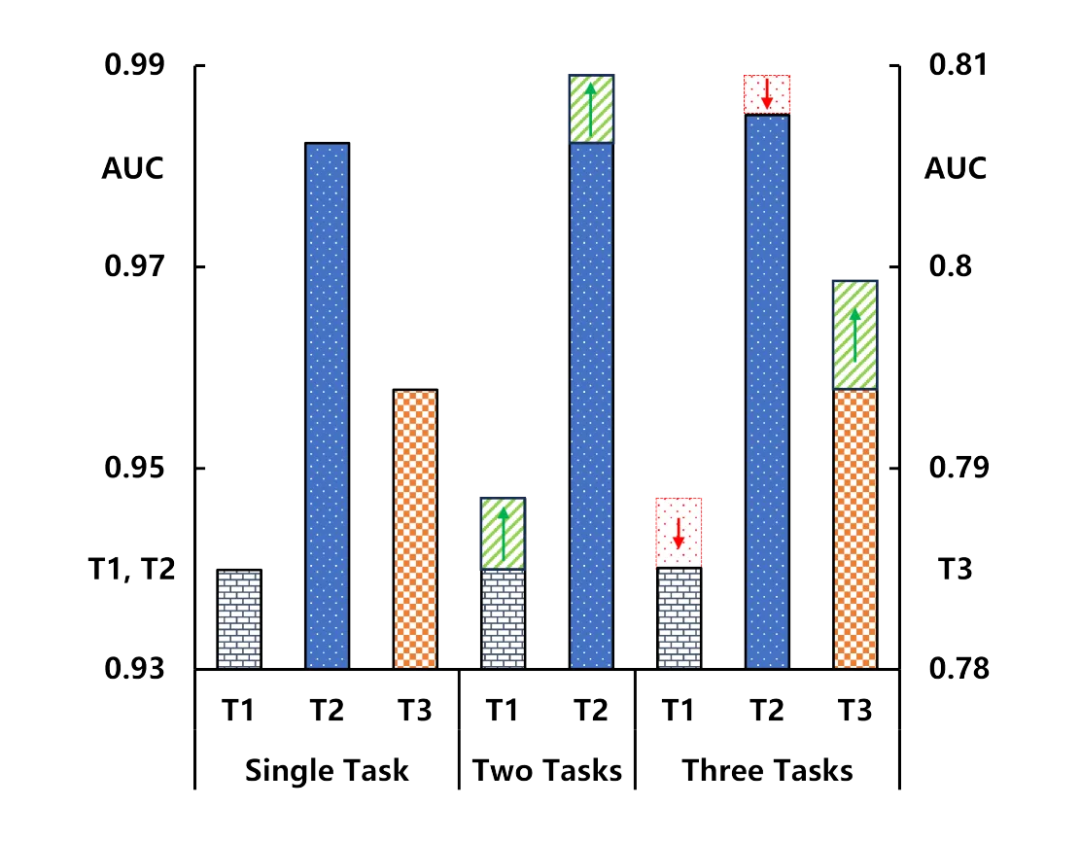
▲ 图1:新增任务对已有任务性能的影响

方法
在多任务预训练阶段,我们将任务共享信息与任务特定信息分离,随后利用任务感知提示向量,将已有任务的知识高效迁移至新任务。在多任务提示调优阶段,MPT-Rec 通过冻结预训练任务中的参数,有效避免了新任务可能带来的负面影响,同时大幅降低了训练成本。
如图 2 所示,MPT-Rec 由两个部分组成:多任务预训练组件和多任务提示调优组件,分别对应于 MPT-Rec 中的两个训练阶段。
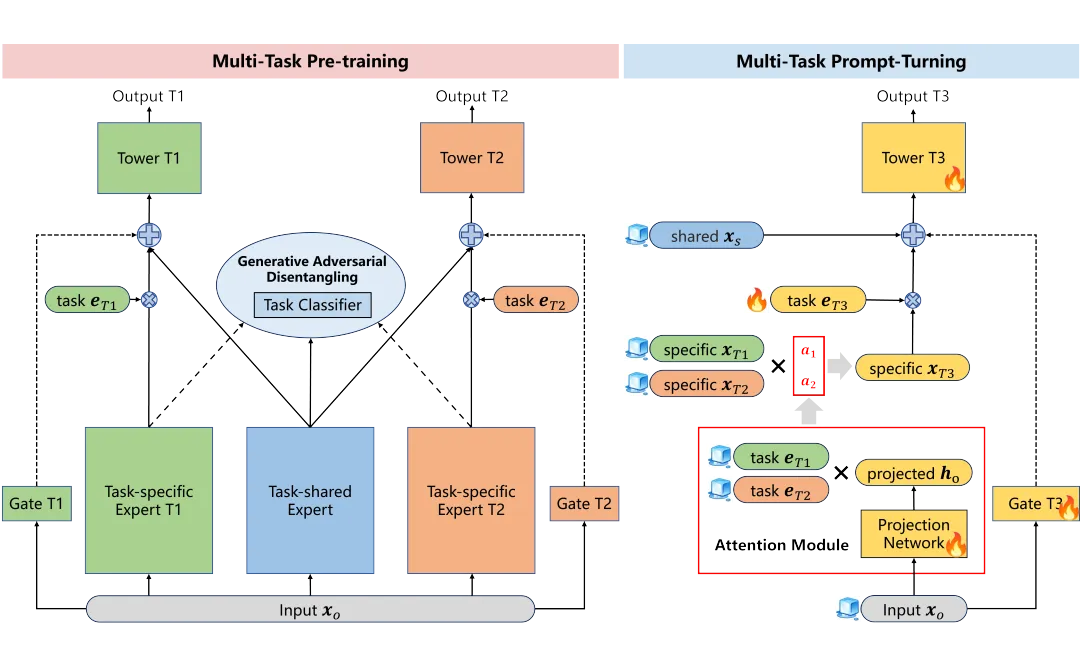
▲ 图2:MPT-Rec 的整体框架
2.1 多任务预训练
多任务预训练阶段旨在提高现有任务的性能,同时提取可转移的知识以促进新任务的泛化,主要包括两个操作:学习解耦信息和学习融合信息。
Step1:学习解耦信息
为解决任务间负迁移问题,我们采用生成对抗网络实现任务共享信息与任务特定信息的显式分离,保障新任务学习时两类信息的高质量传输。
该网络由任务共享专家(生成器)和任务分类器(判别器)构成。生成器致力于生成不含任务特定信息的表征,以此迷惑任务分类器;判别器则尝试依据任务共享表征判断任务标签。经训练,任务共享专家习得的共享信息能规避判别器识别,从而实现两类信息在不同类别专家间的显式分离。
具体而言,多任务预训练组件按照以下步骤学习解耦信息:
1. 输入向量经专家网络处理,得到任务共享表征 xₛ 与任务特定表征 xₖ;
2. 利用共享表征 xₛ 通过塔型网络生成首个预测结果,并计算损失值 Lossₛ;
3. 借助共享表征 xₛ 经任务分类器获取任务标签预测值,与真实标签对比计算环境损失 Lossₑ;
4. 对 Lossₛ 与 Lossₑ 进行加权组合,得到生成对抗网络训练损失:
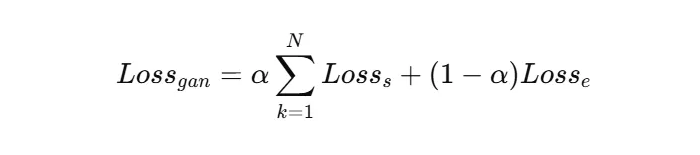
生成对抗网络训练损失的第一项确保共享表征蕴含有效信息,第二项则过滤任务特异性内容。通过生成对抗机制的迭代优化,实现任务共享信息与任务特定信息的有效分离。
Step 2:学习融合信息
在利用生成对抗网络分离任务共享信息与任务特定信息后,设计融合网络,通过为各任务分配任务标签向量引导信息融合,将两类信息整合用于任务最终预测。
具体而言,多任务预训练组件按照以下步骤学习融合信息:
1. 融合任务特定表征与标签向量,构建任务感知表征xₑ;
2. 利用门控网络生成的权重,融合任务共享表征与任务感知表征,得到融合表征 x₍f₎ ;
3. 通过塔形网络对融合表征 x₍f₎ 进行预测,得到结果 ŷ₍f₎,并结合真实标签 yₖ 计算融合表征预测损失。

最后,多任务预训练阶段的总损失为生成对抗网络训练损失与融合表征预测损失之和:

2.2 多任务提示调优
多任务提示调优阶段旨在利用现有知识,加快新任务的训练过程。此目标非常适合由于业务场景的变化而频繁请求新任务优化的推荐情况。
我们提出了一种任务感知提示调优方法,将任务标签向量当作提示,组合在多任务预训练阶段训练好的任务特定表征当作新任务的特定表征,因此大大提高了新任务的训练效率。多任务提示调优主要包括两个操作:任务特定信息迁移和任务感知提示调优。
Step3:任务特定信息迁移
在任务特定信息迁移过程中,我们首先将输入向量投影到任务标签向量的语义空间中,然后计算投影后的向量与不同任务标签向量之间的内积,以此作为相似度。接着,我们对这些内积应用 softmax 函数,得到对应的权重分数。最后,我们利用这些权重来融合现有的任务特定表征,从而获得新任务的特定表征。
Step 4:任务感知提示调优
在任务感知提示调优过程中,我们首先将融合生成的新任务专属表征与新任务标签向量深度融合,构建出具备强语义关联的任务感知表征。随后,该表征与迁移而来的任务共享表征进行有机整合,形成兼顾任务独特性与跨任务共性的复合特征,为新任务预测提供核心依据。
基于此融合表征的预测输出,我们通过计算预测结果与真实标签间的损失函数,利用梯度反向传播机制对模型参数进行精准更新,实现模型在新任务场景下的高效优化与性能提升。

实验
我们在三个数据集上进行了实验,并将我们的模型与几种具有代表性的多任务学习模型进行比较,以展示 MPT-Rec 的有效性和高效率。
验证1:多任务推荐实验结果
三个数据集的实验结果如表 1 所示。所有任务在这三个数据集上都是二分类任务,我们使用 AUC 作为评估指标。由表 1 可知:
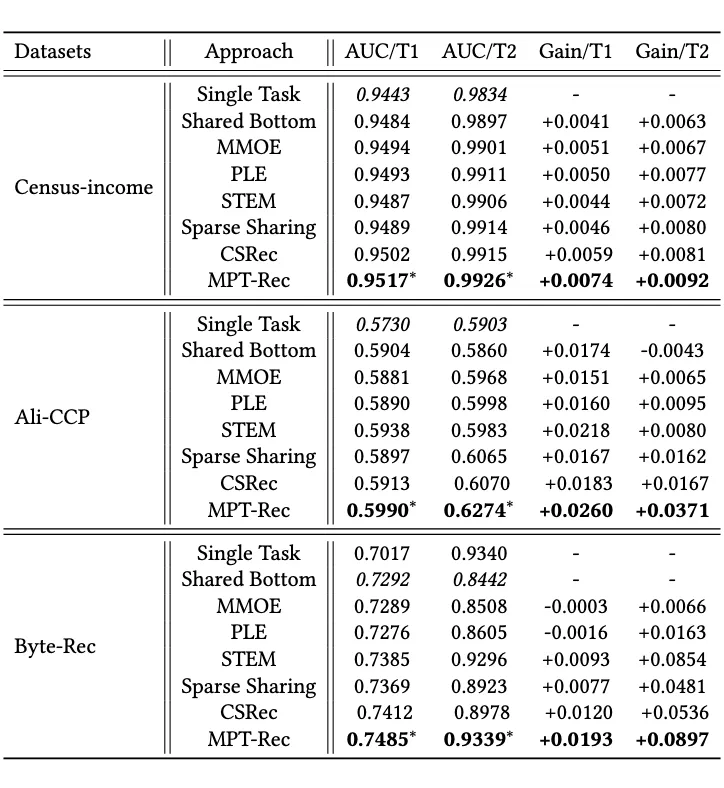
▲ 表1:MPT-Rec 的多任务学习能力
实验结果表明:我们提出的方法 MPT-Rec 在所有数据集上都取得了最佳性能。与使用任务共享专家和任务特定专家来区分信息的 PLE 不同的是,MPT-Rec 通过生成对抗网络在学习过程中施加了更明确的限制,使其更能避免任务无关信息的转移。
验证2:新任务泛化实验结果
为了评估多任务学习方法的泛化能力,我们通过排除预测特征构建了一个新任务 T3。
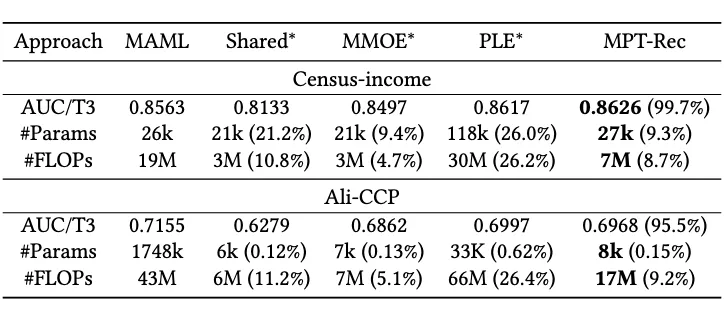
▲ 表2:MPT-Rec 的新任务泛化能力
实验结果表明:我们提出的 MPT-Rec 模型具有以下显著优点:
(1)性能卓越:通过生成对抗网络学习高质量任务共享信息,避免混杂无用噪声,在性能表现上更为出色。
(2)高效低耗:相比全参数训练方案,在两个数据集上 FLOPs 减少超 90%;以较小性能下降为代价大幅提升训练效率。
(3)适应性强:数据集越大,MPT-Rec 在多任务学习中采用微调方案的优势越显著,随着输入特征维度增加,展现出更好的新任务泛化性。
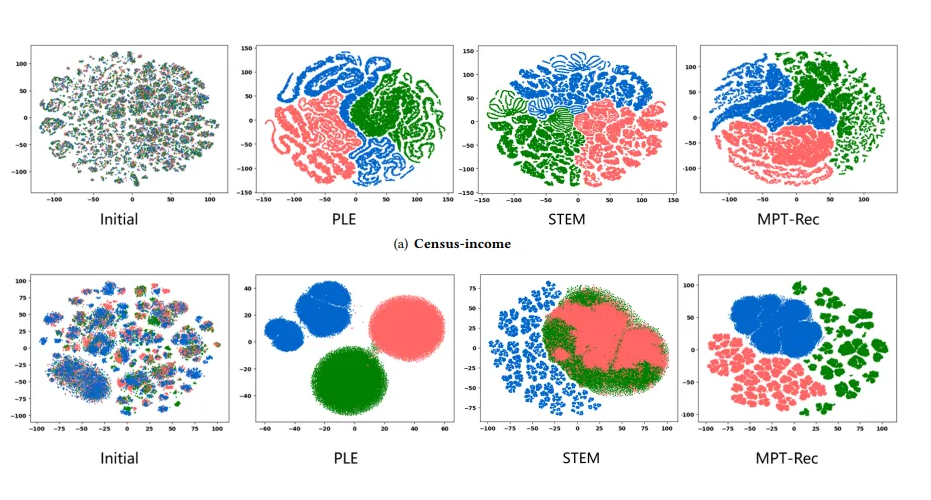
多任务解耦效果可视化展示

结论
在本文中,我们提出了一种两阶段解耦多任务提示推荐框架 MPT-Rec,旨在解决多任务推荐系统中新任务学习的负迁移和高成本问题。MPT-Rec 由预训练和提示调优两个阶段组成。在预训练阶段,我们将任务共享信息和任务特定信息分离开,使其在提示调优阶段得到有效利用。
对三个现实数据集的大量实验表明了我们提出的多任务学习框架的有效性。与 SOTA 多任务学习方法相比,MPT-Rec 取得了最好的性能。此外,它在新任务学习中保持相当模型性能的情况下,大幅提高了训练效率(训练参数不到全参训练的十分之一)。
(文:PaperWeekly)