
RAG(检索增强生成)系统通过利用大语言模型(LLM)并将其与特定数据源集成,使用户可以使用自然语言提出问题。
我将在本文重点介绍 RAG 的一个具体应用:将用户的自然语言转化成 SQL 查询并在数据库引擎上执行,最后以自然语言的形式返回结果。
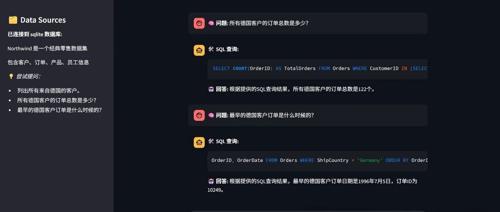
最终我们将会得到一个能执行单表和联表查询的 SQL 助手:

我们的主要技术栈:
-
LangChain 用于连接 LLM 与数据库 -
LangGraph 用于管理多步骤工作流和内存 -
Streamlit 作为聊天机器人用户界面 -
以 OpenAI API 兼容的形式调用阿里千问模型
用于 SQL 的 RAG 系统
SQL 的 RAG 系统通过将 LLM 与真实数据库上下文结合,帮助生成更准确的结果。LLM 不仅仅依赖通用训练数据,而是利用检索到的上下文生成精确、实时的响应。这些上下文来自数据库的模式元数据。
当用户提出问题时,系统会自动将上下文与问题一起作为提示的一部分提供。这帮助 LLM 理解 SQL 方言、可用表、关系和列数据,从而构建语法和语义正确的查询。
这些查询随后提交给数据库引擎,检索到的结果被转化为自然语言。
系统概览:工作原理
下图展示了整体系统架构——用户、数据库和大型语言模型如何通过应用层交互。
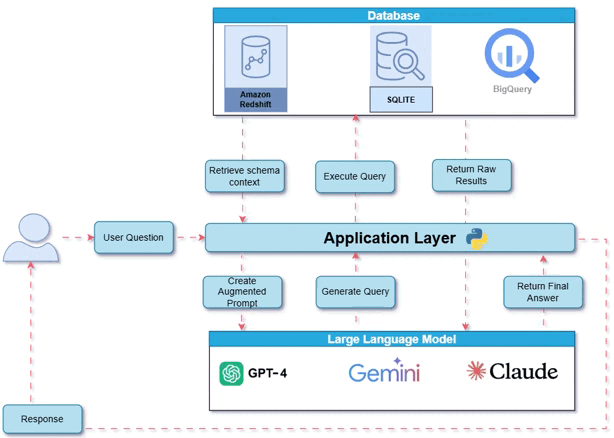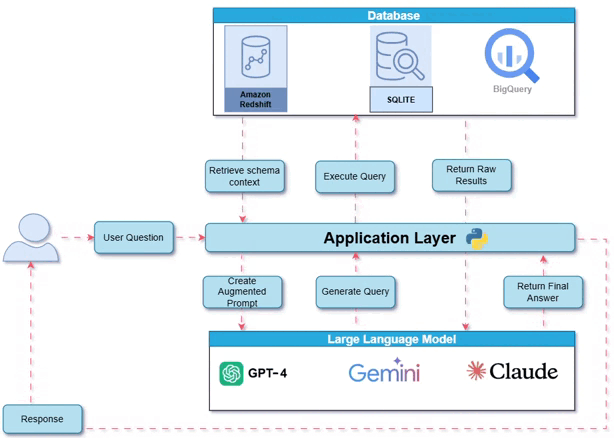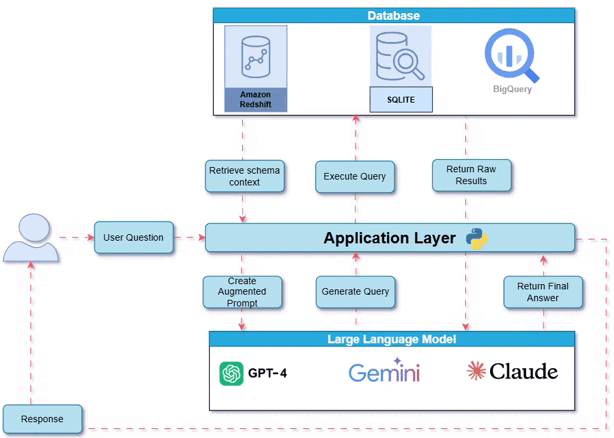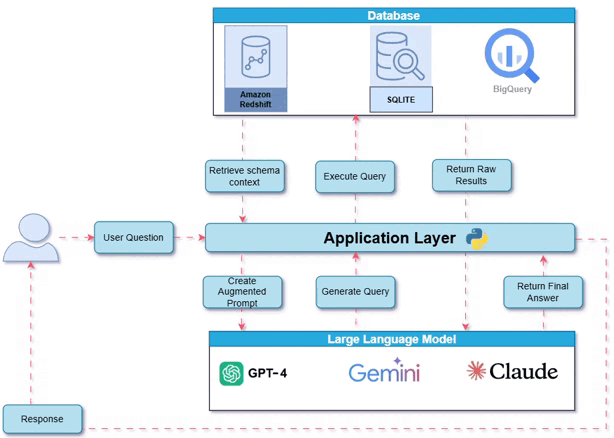
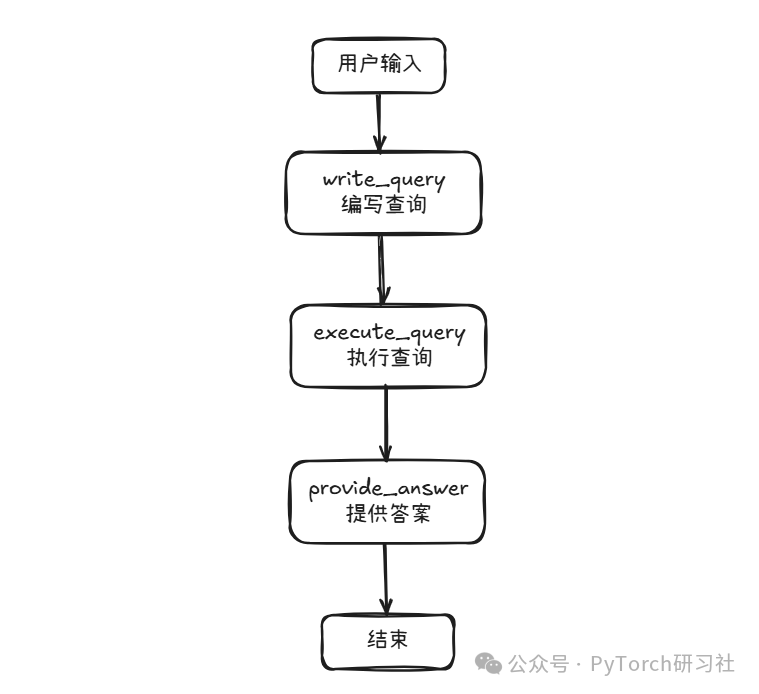
工作原理:内部工作流程和工具
应用层内的工作流程通常分为以下几个阶段:
工作流程背后的关键工具
-
LangChain 是一个框架,旨在帮助将 LLM 与外部系统(如 SQL 数据库、API 和文件存储)集成,简化 AI 应用的构建。
-
LangGraph 是 LangChain 的扩展,是一个编排框架,支持有状态的工作流程,允许系统在工作流程的多个步骤中保持上下文。
-
Streamlit 是一个开源 Python 库,可用于构建简单、交互式的 Web 应用,完全使用纯 Python。
技术细节
现在让我们逐步了解其构建过程——从项目设置到数据库连接、模型编排和前端集成。
项目结构和前提条件
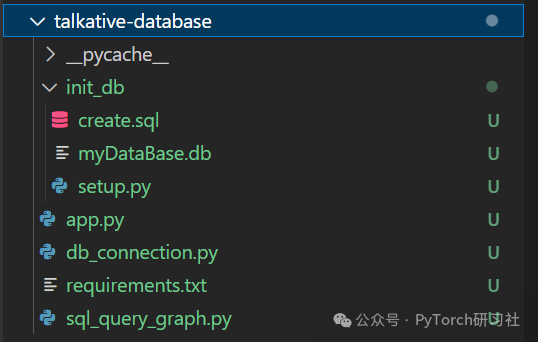
核心代码
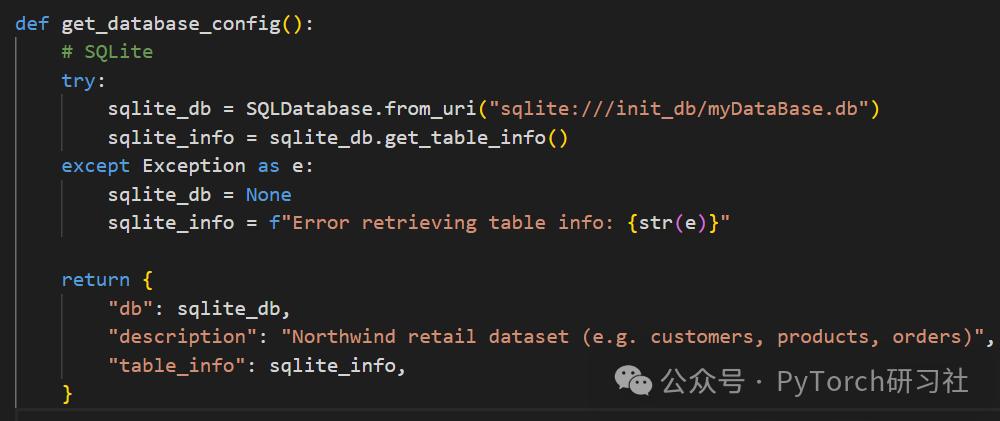
db_connections.py:负责管理数据库链接,以及获取数据库中表相关重要元数据的代码。
sql_query_graph.py:定义了从接收用户问题、编写 SQL 查询、执行查询到生成最终答案的 4 个核心函数,最后使用 LangGraph 将这 4 个核心函数组织成逻辑工作流。
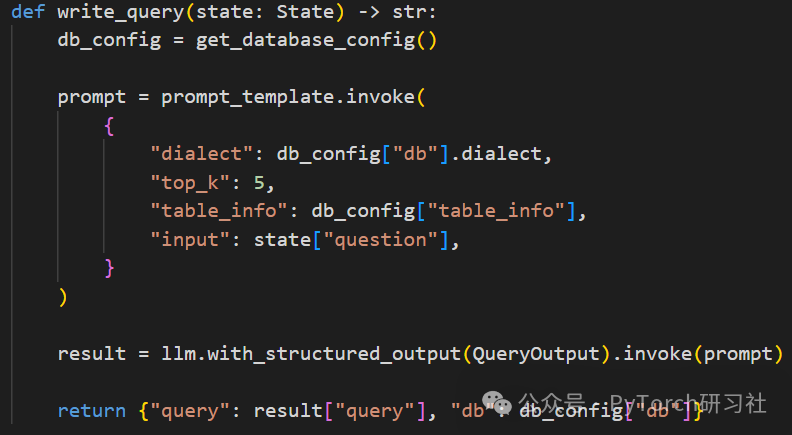
1. write_query:生成语法正确的 SQL 查询。
-
使用选定的数据库,提取其方言和表信息。 -
使用 SQL 特定的提示模板指导 LLM 生成与数据库结构匹配的 SQL 查询。

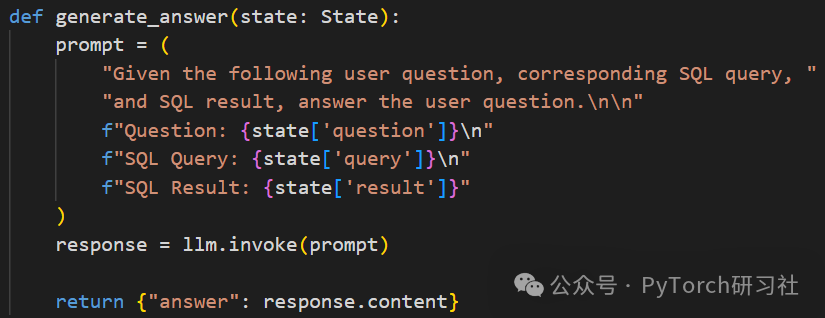
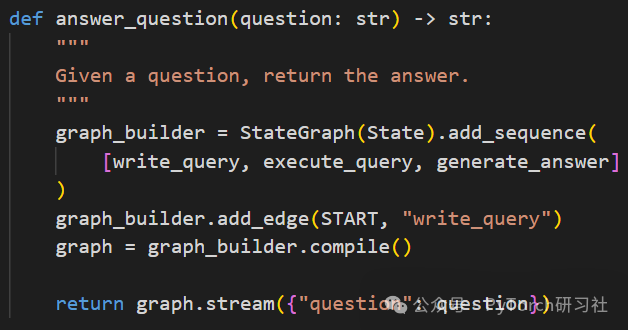
4. answer_question:创建基于图的执行流程,按逻辑顺序连接每个函数:
-
write_query → execute_query → generate_answer
-
使用 StateGraph 创建图工作流,编译并运行。
加入星球获取精心打造的提示工程、RAG和Agent开发实践教程。
(文:PyTorch研习社)