

克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
不用动作捕捉,只用一段视频就能教会机器人学会人类动作,效果be like:
UC伯克利团队研发出了一套新的机器人训练系统,可将视频动作迁移到真实机器人。
这个名为VideoMimic的新系统,已经让宇树G1机器人成功模仿了100多段人类动作。
VideoMimic的核心原理是从视频当中提取姿态和点云数据,然后在模拟环境中训练并最终迁移到实体机器人。
这项成果引起了网友们的一片哇声,还有人联想到了《加勒比海盗》中的杰克·斯帕罗,表示简直就像装上了一个Jack的API一样。
适应各种地形,还会爬台阶
为了训练机器人策略,研究团队收集了一个包含123个视频片段的数据集。
这些视频由手持设备在日常环境中拍摄,涵盖了不同的人体运动技能和场景。
在VideoMimic的训练下,宇树Go1已经学会了适应各种地形:

学会了跨越路肩:

而且学会了爬台阶,过程中还表演出了花式走位:

既然会上,当然也就能下:

并且在下楼梯的过程中,作者发现即使机器人的脚底发生较大滑动,训练得到的策略也能够快速做出反应并恢复平衡,从而避免跌倒。
除了以上各种行进动作之外,也会站起和坐下:

总之,作者的一系列实验,证明了VideoMimic方法,能够有效地通过视频训练机器人模仿人类动作。
那么,VideoMimic具体是如何工作的呢?
一段视频训练机器人
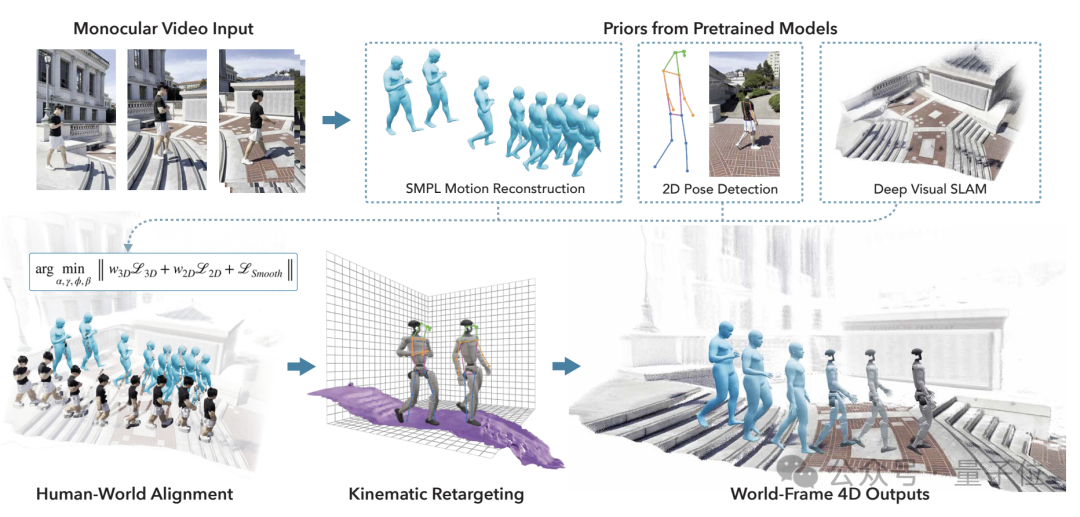
VideoMimic的核心是从单目视频中重建人体运动和场景几何,将其转换为仿真环境中的参考运动,并通过强化学习训练出一个单一的策略,使人形机器人能够根据环境和指令执行对应的技能。
其工作流程主要包括视频到仿真环境的转换、仿真中的机器人控制策略训练以及在真实机器人上的策略部署验证三大步骤。
从视频中构建仿真环境
第一步中,VideoMimic利用现有的人体姿态估计和场景重建方法,从输入的单目RGB视频中获取每一帧的人体三维姿态(通过SMPL人体模型表示)和稠密场景点云。
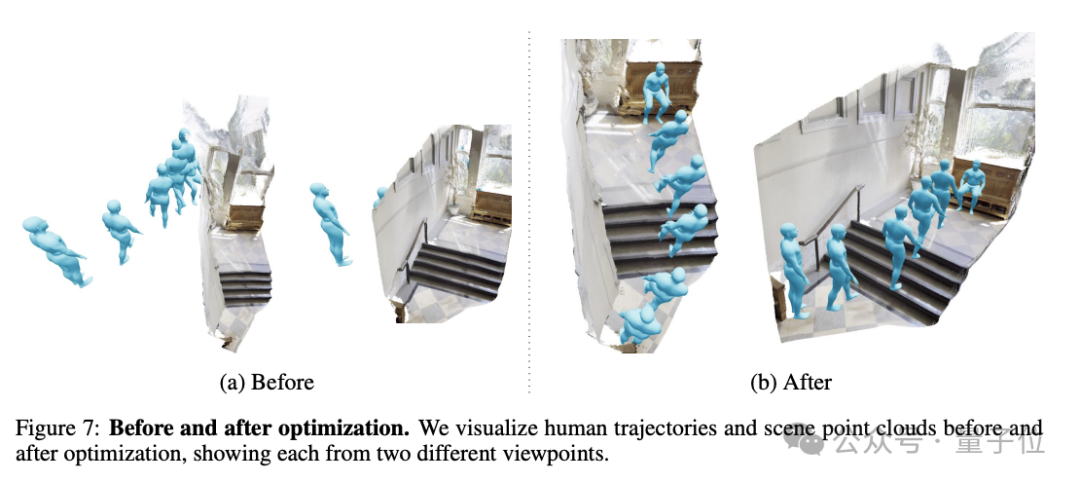
为了解决人体轨迹与场景不完全一致的问题,VideoMimic还提出了一个联合优化过程,同时优化人体轨迹、局部姿态以及场景点云尺度,最终在得到准确对齐的人体运动和场景几何。
接下来,为使重建的场景能够在物理仿真环境中使用,VideoMimic需要进一步处理场景点云,将原始的稠密点云转换为具有一定拓扑结构的轻量级三角网格模型,以提高碰撞检测和渲染效率。
最后是将视频中的人体运动重定向到机器人模型:VideoMimic考虑了机器人的运动学结构差异,通过优化人形机器人各关节的旋转角度,将人体运动中的末端位置映射到对应的机器人关节位置。
在仿真环境中训练策略
在获得视频对应的参考运动轨迹和环境网格模型后,VideoMimic进入了机器人控制策略的仿真训练阶段。
这个阶段的目标是训练出一个单一的策略网络,使其能够克服视频重建中的噪声,根据环境感知做出对应的运动控制。
整个训练过程分为四个渐进的阶段:
-
第一阶段是在大规模数据上进行策略预训练,以掌握基本的运动控制能力,该阶段只需要根据参考的关节角度、躯干朝向和位置等运动学信息进行控制; -
第二阶段引入从重建场景中采样得到的高度图作为策略的观察输入,使得策略能够感知环境地形,根据当前环境做出决策; -
第三阶段使用Dataset Aggregation方法对策略进行蒸馏,得到一个不依赖完整参考运动,只依赖机器人躯干位置指令的新策略; -
在第四个阶段,VideoMimic在蒸馏后的策略基础上进一步应用强化学习算法进行微调,使策略可以更好地适应观察和环境的噪声,提高其鲁棒性。
经过上述四个阶段的训练,VideoMimic最终得到了一个泛化能力较强的控制策略。
这个策略只需要机器人自身的本体感受信息(如关节角度、角速度等)、局部高度图以及期望躯干运动方向作为输入,就可以输出连续的低层控制指令。
这些指令驱动机器人执行行走、爬楼梯、坐下、站立等各种动作,为实际机器人部署做好了准备。

将策略迁移到实体机器人
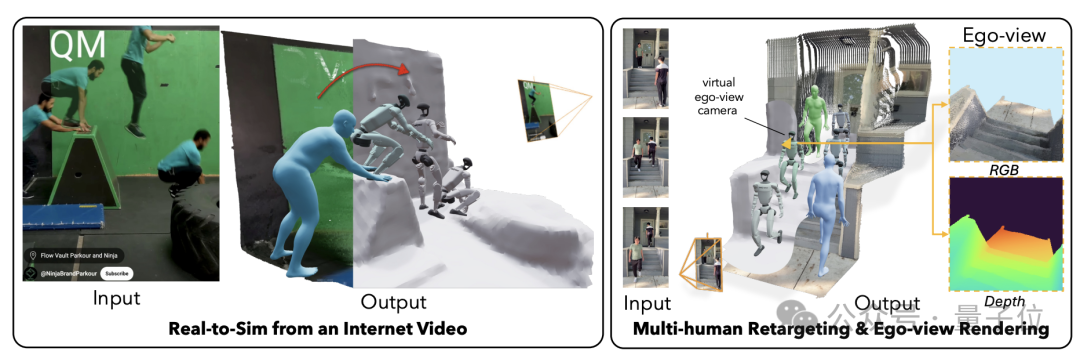
VideoMimic选择了宇树Go1作为实物测试平台,Go1是全身拥有12个自由度,其关节配置与仿真环境中的机器人模型相似。
同时,Go1还搭载了用于感知环境的深度相机和惯性测量单元(IMU)等传感器,可以为控制策略提供必要的观察信息。

在部署到实物机器人之前,研究团队首先对Go1进行了一些基本设置。他们参考了MuJoCo仿真器中的机器人模型参数,对Go1的底层PD控制器进行了配置,使其与仿真环境保持一致。
在真实环境中,VideoMimic利用Go1自带的深度相机获取环境的三维几何信息,结合彩色图像SLAM算法,实时重建出以机器人为中心的局部环境三维点云。
最终,VideoMimic得到了一个覆盖机器人周围4平方米区域、分辨率为2.5厘米的高度图,作为策略模型的环境观察输入。
除了环境信息外,Go1的关节编码器和IMU也以200Hz的频率提供了机器人关节角度、角速度、线加速度等本体感受信息。
VideoMimic直接将这些数据作为策略模型的输入,用于估计机器人当前的姿态和运动状态。
Go1搭载的嵌入式计算平台,让VideoMimic可以将训练好的策略模型直接部署到机器人上进行实时推理。
研究团队基于ROS机器人操作系统,利用C++实现了策略模型的前向推理和与机器人底层控制的通信。
策略模型以50Hz的频率运行,与机器人控制的周期相匹配。在每个控制周期内,策略模型读取当前的环境高度图和机器人本体感受信息,输出预测的机器人关节角度。
这些关节角度经过必要的平滑和限幅处理后,直接作为PD控制器的目标值,驱动机器人运动。
作者简介
本项目论文的共同一作共有四位,均为UC伯克利博士生,其中包括一位华人。
Arthur Allshire,导师是强化学习大牛、吴恩达带的第一届博士Pieter Abbee,以及被李飞飞尊称为“学术祖父”的Jitendra Malik。
Arthur的研究兴趣为“智能软件系统与物理世界的交互”,主攻机器人、计算机视觉和机器学习。
他本科毕业于多伦多大学,其间曾到苏黎世联邦理工学院访学,以及在英伟达实习。

Hongsuk Choi,同样是Jitendra Malik的学生,另一名导师是伯克利助理教授Angjoo Kanazawa。
Angjoo此前在伯克利从事博士后研究,期间的合作导师也包括Jitendra。
Hongsuk的研究兴趣是生成先验、3D计算机视觉和机器人技术。
他本科和硕士均毕业于首尔大学,2022年毕业后先后到NAVER和三星公司工作,去年开始到伯克利读博。

华人作者章俊一(Junyi Zhang),导师是伯克利AI实验室(BAIR)的联合创始人Trevor Darrel教授。
章俊一的研究兴趣为计算机视觉、深度生成模型和表示学习,现阶段重点关注扩散模型的应用。
他去年本科毕业于上海交大,其间曾到微软实习,并以本科生研究员身份与李永露助理教授合作研究,导师是卢策吾教授。
2023年起,章俊一还成为了DeepMind的合作研究者,至今仍与DeepMind的杨明玄(Ming-Hsuan Yang)、Deqing Sun等人保持合作。

David McAllister,研究兴趣是计算机视觉、成像和数字创意有,导师为Angjoo Kanazawa。
David本科和硕士同样就读于UC伯克利,并且硕士期间的导师也是Angjoo。
去年夏天,David曾到英伟达投资的AI初创公司Luma实习,Luma推出了与公司同名的视频生成模型。

除了四位共同一作和他们的导师之外,UC伯克利硕士生Anthony Zhang和博士生Chung Min Kim也参与了这一项目。

项目主页:
https://www.videomimic.net/
论文地址:
https://arxiv.org/abs/2505.03729
— 完 —
📪 量子位AI主题策划正在征集中!欢迎参与专题365行AI落地方案,一千零一个AI应用,或与我们分享你在寻找的AI产品,或发现的AI新动向。
💬 也欢迎你加入量子位每日AI交流群,一起来畅聊AI吧~

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
(文:量子位)