
梦晨 鹭羽 发自 凹非寺
量子位 | 公众号 QbitAI
AI视频的DeepSeek时刻什么时候来?没想到吧,这就来了。
最新开源模型LTXV-13B,免费可商用、推理速度快、游戏显卡就能跑,视觉效果也不错。要素都齐了,想不火都难。
从官方透露的信息看,新模型在速度、质量和控制三个方面有所提升。
生成速度——同类产品的30倍,提出想法可以获得接近实时的反馈。
视频质量——眼见为实,请看VCR。
可控制性——支持逐帧控制,能让你按照自己想法来打造视频,创作自由度直接拉满。
这个13B参数的模型,官方证实在24G显存的4090/5090上就能跑,也难怪网友纷纷为之疯狂。
大家晒出的“买家秀”,效果比官方卖家秀看起来也毫不缩水:
开源视频生成新标杆
LTX-Video支持文本转图像、图像转视频、基于关键帧的动画、视频扩展(正向和反向)、视频转视频,以及上述所有这些功能的任意排列组合。
-
视觉效果爆炸
LTXV-13B拥有超130亿个参数,即使在快速复杂的场景,也能提供更流畅的运动、更少的伪影和更清晰的视觉效果。
那么下面再直观感受一下效果。

Prompt:一位有着棕色长发和白皙皮肤的女人对着另一位女人微笑……一位有着棕色长发、肤色白皙的女子正对着另一位有着金色长发的女子微笑。这位棕色头发的女子身穿黑色夹克,右脸颊上长着一颗几乎难以察觉的小痣。镜头角度为特写镜头,聚焦于这位棕色头发女子的脸部。光线温暖自然,似乎是落日的余晖,在场景中投射出柔和的光芒。这幅场景似乎是真实拍摄的。
还可以不断地调整拍摄角度,营造出非常自然的航拍效果。

Prompt:海浪冲击着海岸线上嶙峋的岩石……海浪拍打着海岸线上嶙峋的岩石,溅起阵阵浪花。岩石呈深灰色,边缘锋利,裂缝深邃。海水清澈碧绿,浪花拍打岩石的地方泛起白色的泡沫。天空呈浅灰色,几朵白云点缀在地平线上。
这下谁还能分清什么是现实什么又是AI生成的呢?
但记得要在生成之前放大图片,不要像下面这位网友一样:
-
生成速度提升
相较于同类产品,LTXV-13B生成速度领先近30倍,但质量可是一点都没打折扣,相当适合快速迭代、实时反馈和大规模生产场景。
不仅效率大幅度提升,成本也跟着降低,用消费级GPU就能搞定,也可以选择官方平台LTX Studio云体验。
-
精细创意控制
此外,LTXV还有强大的创意控制功能,提供多关键帧调节(起始帧和结束帧)、摄像机控制(推拉、变焦、摇臂、轨道等)、面部表情控制等。

LTXV-Video:实时视频潜空间扩散模型
官方透露,LTX Video做到更流畅的运动和更一致的帧间连贯性,关键在于多尺度渲染技术,即同时以多种空间分辨率分析场景,保留精细细节的同时理解大规模结构。

如下面的例子,可以看到从左到右人物脸上的细节越来越丰富。

从团队几个月前发布的2B参数模型论文也可以看出,训练阶段就同时使用了多种分辨率和时长组合的数据。
训练时通过调整原始视频大小,使输入样本包含大致相同数量的token,并采用随机丢弃token的策略,避免复杂的token填充或打包操作,保持数据多样性。

上一代2B参数的模型就以速度和效率见长,能够以超过实时的速度生成高质量视频,在H100 GPU上仅需2秒就能生成5秒、24帧每秒、768×512分辨率的视频。

优化生成速度的秘诀在于一种整体式Latent Diffusion方法,将Video-VAE和去噪Transformer的任务无缝融合,在它们之间共享去噪目标。
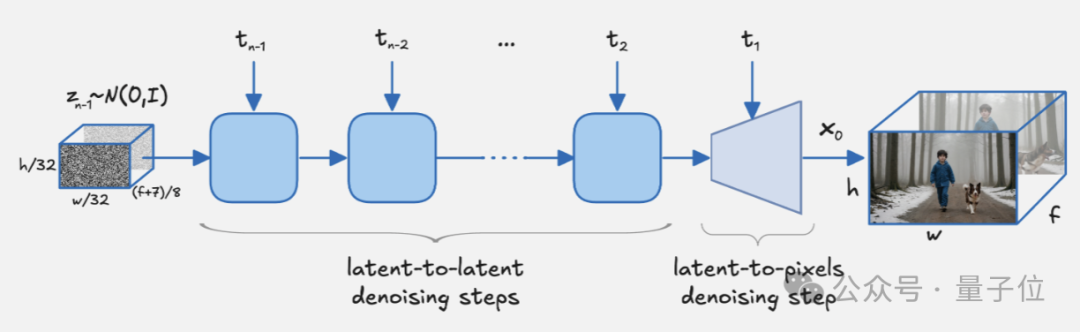
另外Video VAE部分对时空维度进行32×32×8的下采样压缩,将高分辨率的视频数据转换到低分辨率的潜在空间进行处理,通过空间和时间压缩来降低冗余。
它实现了1:192的压缩比,超过当时的主流开源模型如MovieGen、CogVideoX等的1:48或1:96的压缩比。
为实现这种高压缩率,团队将图像块化操作(patchify)从Transformer的输入移到了VAE的输入,使每个token能够表示更多的像素信息,帮助Transformer计算全时空自注意力(full spatiotemporal self-attention)。

高压缩率虽好,但会限制对细节的表示能力。为了解决这个问题,LTX-Video还采取了多种新策略。
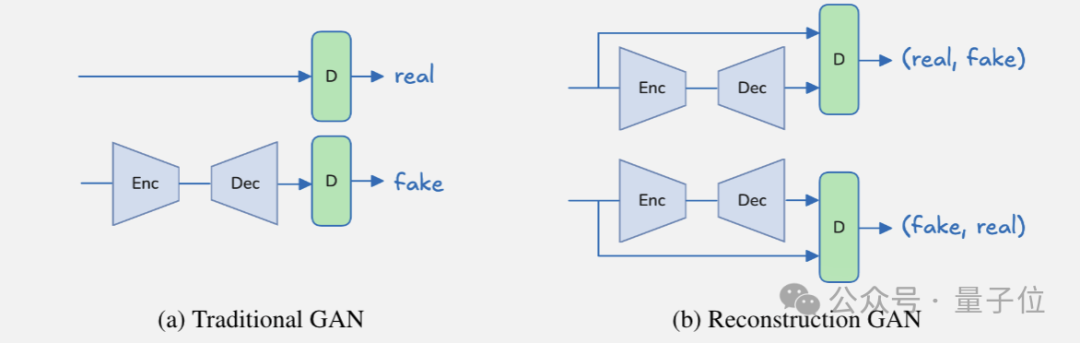
在训练Video VAE时引入GAN,减少高压缩率下L2 loss产生的模糊问题。
为此提出改进的Reconstruction GAN,判别器同时接收原始样本和重建样本,通过判断哪个是原始的、哪个是重建的,简化了判别器的任务,提高了其引导生成器的能力,使生成的视频在保持与原始样本相似性的同时,能更有效地平衡保真度和感知质量。
此外还有一些小的改动如下:
-
多层噪声注入:受StyleGAN启发,在VAE解码器的多个层注入噪声,允许生成更多样化的高频细节。 -
统一对数方差:使用宽潜空间(大量channels)时,标准KL损失会导致不均匀的利用。团队使用了所有潜通道共享的单一预测对数方差,均匀分配KL损失的影响。 -
视频DWT损失:引入了spatio-temporal Discrete Wavelet Transform (DWT) loss,确保高频细节的重建。
LTX-Video同时支持文本生成视频和图像生成视频两种能力。
对于文本条件生成,团队使用了预训练的T5-XXL文本编码器生成初始文本嵌入,并采用了交叉注意力机制,而非MM-DiT方法。
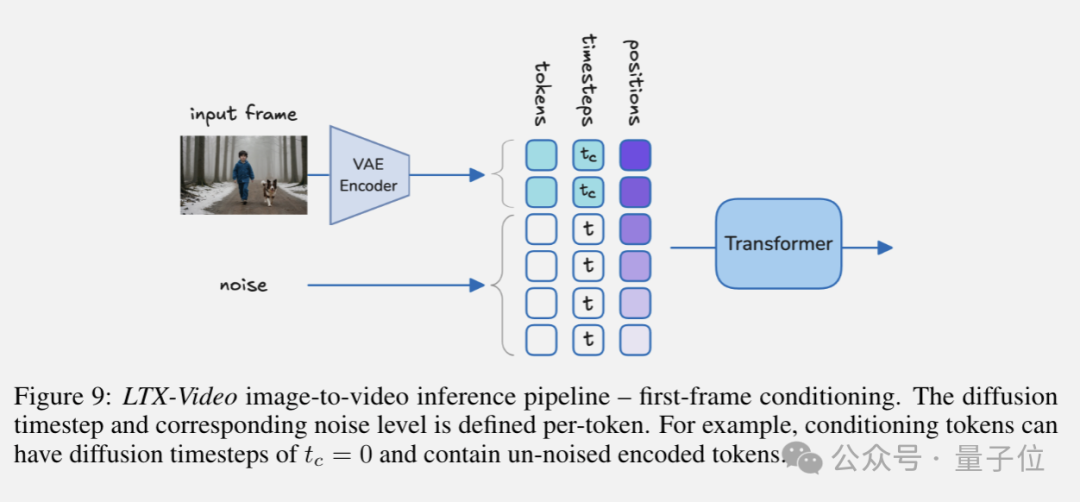
而对于图像条件生成,他们扩展了Open-Sora的方法,利用扩散时间步作为条件指示器,允许无缝条件化视频的任何部分。
这种方法不需要特殊的tokens或专门为图像到视频任务训练的模型,大大简化了流程。
2013年成立的老牌团队
LTX-Video开发团队Lightricks成立于2013年,前大模型时代有两个招牌产品,为美颜相机应用Facetune和视频剪辑应用Videoleap,在苹果商店至今仍排得上号。
2023转型AI后,推出LTX Studio视频生成平台,支持逐镜头地构建视频和时间线编辑,可以精细控制每个场景,并保持角色一致性,主要面向影视、广告和个人视频创作者。

除开源模型外,Lightricks还提供配套的训练工具,支持微调、预处理数据集、为视频添加字幕、分割场景等使用功能。
LTX Video 13B模型推出后开源社区也非常感兴趣,已经有人在一天之内就为其训练好了LoRA,让不同类型角色的眼睛都能冒电光特效,引起网友围观。

感兴趣(且趁24GB显存)的朋友们,可以下载起来了。
Github:
https://github.com/Lightricks/LTX-Video
论文:
https://arxiv.org/pdf/2501.00103
(文:量子位)