


Unlocking General Long Chain-of-Thought Reasoning Capabilities of Large Language Models via Representation Engineering
原文:https://arxiv.org/pdf/2503.11314

这篇文章探索如何解锁大语言模型中潜在的通用长链思考推理能力。现有研究表明,通过少量样本的微调,大语言模型可以展现出长链思考(long CoT)推理的能力,并且这种能力可以迁移到其他任务上。这引起了新的猜测:长链思考推理是否是大语言模型内在的一种通用能力,而不仅仅是在特定任务上通过训练获得的。
研究者首先从大模型中提取表征,具体来说,他们通过将问题及其对应的vanilla CoT和long CoT输入模型,提取隐藏状态作为表征。
-
LLMs确实将long CoT推理编码为一种通用能力:通过可视化和量化分析,研究者发现long CoT的表征在模型的参数空间中集中在特定区域,并且与vanilla CoT的表征有明显区分。 -
Long CoT推理的可迁移性:此外,不同领域(如数学、物理、化学、生物)的long CoT和vanilla CoT之间存在相似的对比表征。
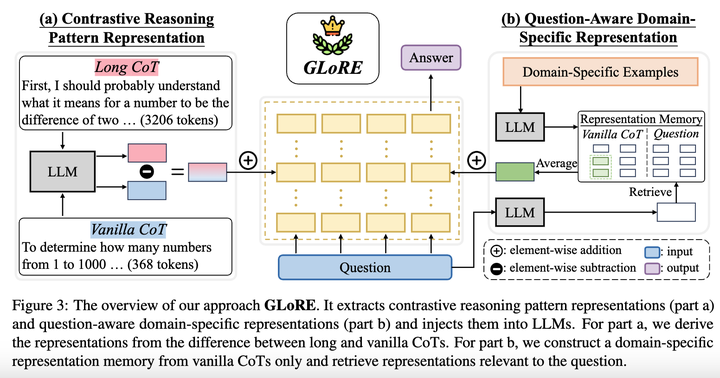
基于上述发现,研究者提出了GLoRE,一种基于表征工程的新方法,用于解锁LLMs的通用long CoT推理能力。
-
对比推理模式表征:研究者首先利用高资源领域的long CoT和vanilla CoT数据,计算对比推理模式表征。在推理过程中,将这个推理模式表征注入到LLMs的特定层中,引导模型从vanilla CoT模式向long CoT模式转变,从而激发模型进行深入推理。 -
问题感知的领域特定表征:由于不同领域的问题需要特定的领域知识来支持long CoT推理,研究者提出构建一个领域特定的表征记忆。在推理时,根据具体问题检索与之相关的领域特定表征,为模型提供领域特定的信息,实现对推理过程的精细控制。
实验证明了该方法在领域内(数学领域)和跨领域(物理、化学和生物领域)两种场景下的有效性、高效性与可扩展性。
Echo Chamber: RL Post-training Amplifies Behaviors Learned in Pretraining
原文:https://arxiv.org/pdf/2504.07912
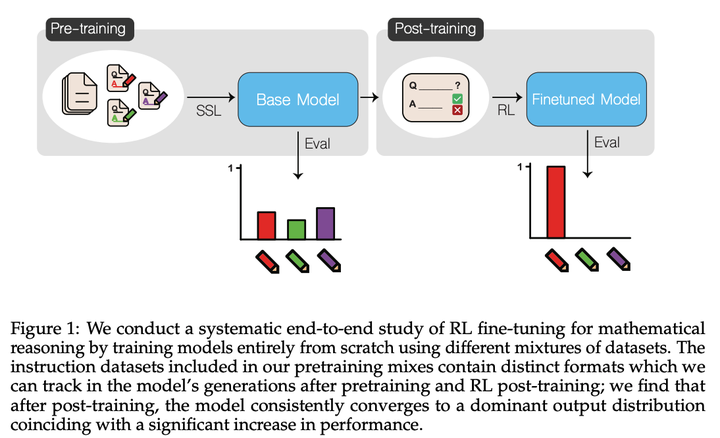
这篇论文探索强化学习在大语言模型后训练(post-training)阶段对数学推理能力提升的机制和效果如何受到预训练数据组成、模型规模和RL算法选择等因素的影响。该文章利用两种规模的解码器大语言模型(OLMo-150M和OLMo-1B),使用数学相关文档和合成指令数据集,使用多种RL算法进行后训练。
实验发现:
-
RL后训练使模型的输出分布迅速收敛到预训练数据中的单一分布,同时抑制其他分布的输出。虽然模型倾向于选择预训练中表现最佳的分布,但并非总是如此。在某些情况下,模型可能会选择一个在预训练时表现较差的分布,导致性能下降。 -
RL后训练不仅提高了模型在训练数据上的表现,还在未见过的评估数据集上表现出正向迁移。
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
原文:https://arxiv.org/pdf/2504.13837
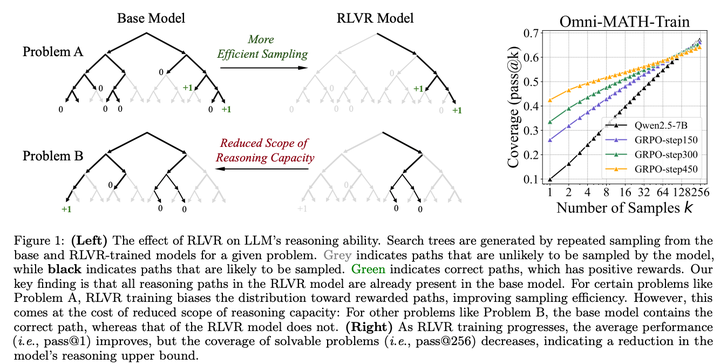
这篇文章旨在探索强化学习是否真的能够激励大语言模型在推理能力上超越基础模型的限制。
-
使用Pass@k指标评估使用RL推理能力边界的变化情况,发现随着RL训练步骤的增加,Pass@k在所有数据集上均有所下降,表明RL训练减少了模型的输出熵和探索能力,从而限制了推理能力的边界。 -
通过计算困惑度发现RL训练模型生成的推理路径已经存在于基础模型的输出分布中,这表明RL训练并没有引入全新的推理能力,而是优化了模型的输出分布,使其更倾向于生成能够获得奖励的路径。 -
对比RL训练和知识蒸馏对模型推理能力的影响,发现知识蒸馏与RL不同,能够真正引入新的知识,从而扩展模型的推理能力边界。
Understanding R1-Zero-Like Training: A Critical Perspective
原文:https://arxiv.org/pdf/2503.20783
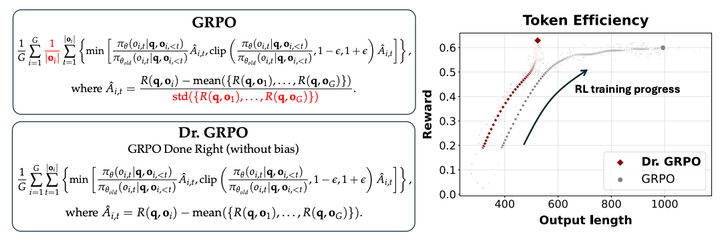
该论文研究了多种基础模型,探讨这些模型在经过预训练后是否已经具备某些推理能力,以及这些能力如何影响后续的强化学习的效果。
研究发现基础模型在RL训练之前已经表现出自我反思行为,而RL在训练后自我反思行为更加频繁,表明这些模型在预训练阶段可能已经具备了一定的推理能力。
同时这篇文章指出 GRPO 算法中存在的优化偏差,如响应长度偏差和问题难度偏差,这些偏差可能导致模型生成越来越长的错误响应。并通过去除 GRPO 中的长度和标准差归一化项,解决了优化偏差问题,提高了模型的 token 效率。
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
原文:https://arxiv.org/pdf/2503.18892
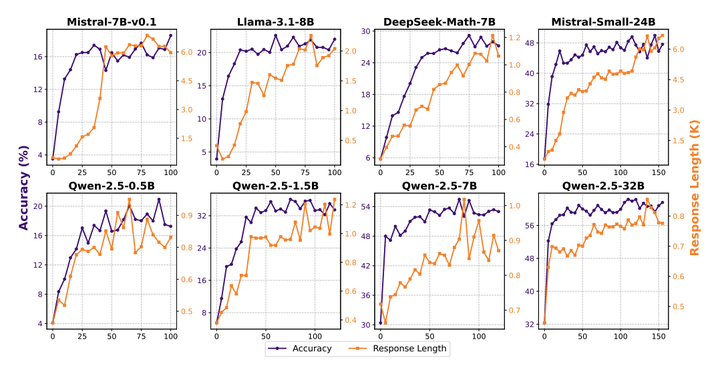
这篇论文试图解决的问题是如何在不同的基础模型上有效地应用zero-RL训练,以提升这些模型在复杂推理任务中的表现。
实验观察到不同基础模型在训练过程中表现出不同的推理行为变化模式。例如,较小的模型在训练后显著增加了“验证”和“枚举”行为的频率,而较大的模型则表现出更稳定的推理行为。
同时,该论文发现过于严格的格式奖励会限制模型的探索能力,而训练数据的难度必须与模型的能力相匹配,否则会导致训练失败。此外,还探讨了在RL训练之前使用传统监督微调作为冷启动的影响。结果表明,虽然SFT可以快速提升模型的初始性能,但它会限制模型在RL训练中的探索能力,最终导致推理能力的提升受限。
FastCuRL: Curriculum Reinforcement Learning with Progressive Context Extension for Efficient Training R1-like Reasoning Models
原文:https://arxiv.org/pdf/2503.17287
论文通过提出FASTCURL(Curriculum Reinforcement Learning with Progressive Context Extension) 方法来解决高效训练推理模型的问题。
-
长度感知的训练数据分割:根据输入提示的长度将原始训练数据分割成不同层级的数据集。 -
带有逐步扩展上下文窗口的课程强化学习:采用课程强化学习方法,逐步扩展上下文窗口长度来训练模型。首先使用短数据集和短上下文窗口开始训练,优化模型生成更简洁的推理理由。当模型的响应长度开始增加时,将上下文窗口不断扩展,并使用长数据集继续训练。最后,使用“长短混合”数据集进行训练,以巩固模型对整个数据集的掌握。
Climbing the Ladder of Reasoning: What LLMs Can-and Still Can’t-Solve after SFT?
原文:https://arxiv.org/pdf/2504.11741
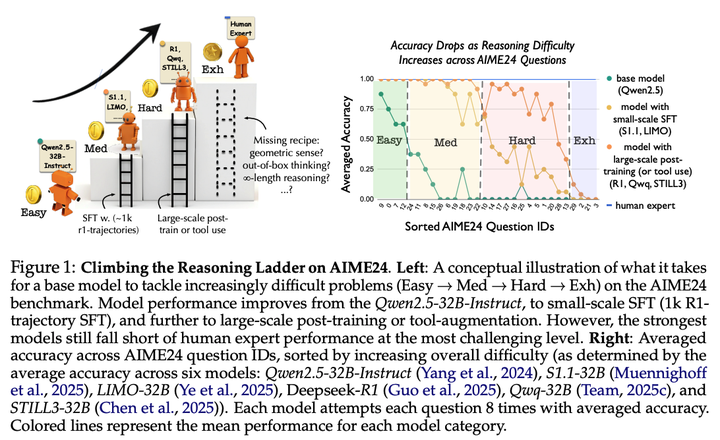
这篇论文试图解决的问题是:通过监督微调方法,大语言模型在数学推理任务上的能力得到了怎样的提升,以及这些提升背后的具体机制是什么。
-
论文发现模型在AIME24数据集上的表现呈现出阶梯状的难度结构,即模型能够解决的问题难度存在明显的分层。 -
从Easy到Medium的提升:发现模型在Medium级别问题上的表现提升主要依赖于采用R1推理风格和长推理上下文,通过在不同数学类别上进行小规模SFT即可实现。 -
从Medium到Hard的提升:发现模型在Hard级别问题上的表现提升遵循对数规律,随着数据集规模的增加,准确率逐渐趋于平稳,最终达到约65%的准确率。这表明Hard级别问题需要更稳定的深度探索和计算能力。 -
从Hard到Exh的提升:发现模型在Exh级别问题上普遍表现不佳,主要原因是这些问题需要非常规的解决方案,如独特的几何直觉或创新的推理策略。当前模型在这类问题上存在根本性的局限性。
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
原文:https://arxiv.org/abs/2412.21187
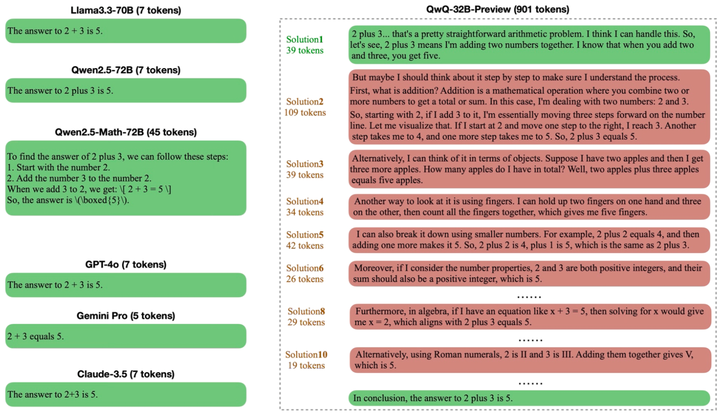
这篇论文关注o1类语言模型在处理简单任务时出现的“过度思考”问题,即模型在无需复杂推理的任务中仍生成冗长的推理路径,造成计算资源浪费和推理效率低下。作者提出一个系统分析框架,用于评估模型在不同任务难度下的推理资源使用情况,并探索多种减缓冗余推理的优化方法。
主要贡献包括:
-
提出从“推理结果准确性”与“过程token效率”两个角度出发的评估指标,衡量模型是否存在过度思考; -
设计多种优化策略,包括SFT、DPO、RPO、SimPO等微调方法,以及FCS、GDS等解码约束策略; -
在多个任务难度跨度大的数据集(如ASDIV、GSM8K、MATH500、GPQA和AIME)上进行实验,显著减少推理长度和生成样本数,同时保持准确率不降。
该研究揭示了当前主流CoT模型在处理简单问题时的效率瓶颈,并提供了一套系统的方法用于缓解这一问题。
O1-Pruner: Length-Harmonizing Fine-Tuning for O1-Like Reasoning Pruning
原文:https://arxiv.org/abs/2501.12570
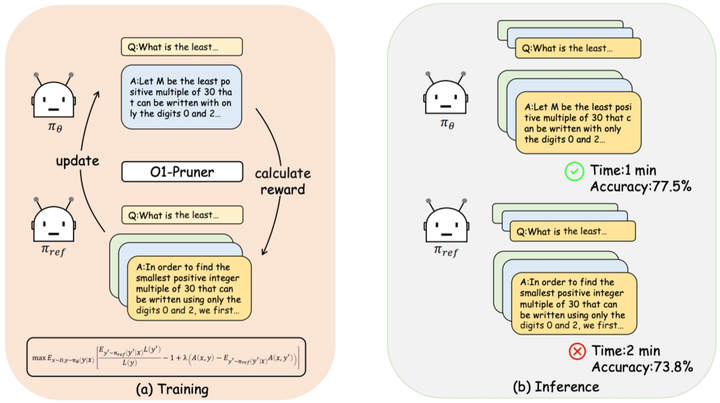
本文指出长链式推理模型中存在“推理长度与任务难度不匹配”的普遍现象,即在简单任务中模型仍倾向输出复杂路径,带来推理效率下降。为此,作者提出了O1-Pruner,一种结合强化学习思想的长度协调微调策略,用于动态压缩不必要的推理过程。
主要贡献包括:
-
明确提出并量化“长度不协调”现象,即推理路径长度与任务难度不一致; -
提出Length-Harmonizing Fine-Tuning方法,通过预采样模型输出和RL风格奖励,引导模型输出更短路径; -
在GSM8K、MATH、Gaokao等多个数据集上实验,证明该方法在减少推理长度的同时提升准确率,优于SFT和DPO等基线。
O1-Pruner为实现推理深度与任务复杂度相适应提供了有效手段,在不损性能的前提下显著提升了推理效率。
CoT-Valve: Length-Compressible Chain-of-Thought Tuning
原文:https://arxiv.org/abs/2502.09601
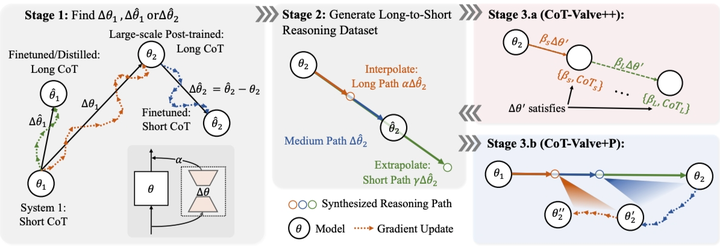
该论文关注思维链(CoT)推理路径冗长问题,指出传统模型缺乏根据任务难度调整推理链长度的能力。为提升模型推理效率,作者提出了CoT-Valve方法,通过引入参数方向控制策略,引导模型输出压缩后的推理路径。 主要贡献包括:
-
提出在LoRA参数空间中寻找“压缩方向”,实现推理路径的可控缩短; -
构建MixChain数据集,为每个问题提供多尺度推理路径以训练压缩能力; -
引入两种增强版本:CoT-Valve++(精细压缩)与CoT-Valve+P(渐进压缩),提升控制效果; -
在GSM8K和AIME上实验显示推理长度平均减少近70%,准确率下降不超过0.15%。
CoT-Valve为CoT路径压缩提供了通用性强、训练开销低的解决方案,能显著降低token成本而保持准确性。
L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning
原文:https://arxiv.org/abs/2503.04697
L1致力于解决语言模型在推理过程中“无法控制思考时间”的问题。作者通过引入强化学习机制,使得模型能够针对不同任务自动调节推理链的长度,实现计算效率与准确性的灵活权衡。
主要贡献包括:
-
提出长度控制策略优化(LCPO)方法,在训练过程中引入长度偏差惩罚与准确性奖励; -
设计LCPO-Exact与LCPO-Max两种推理长度约束模式,分别对应硬性与弹性控制; -
在多个高难度数据集(如AIME、MATH、AMC)中验证L1模型,相同长度下优于S1模型,有时甚至超过GPT-4o; 实验中发现,L1模型在短推理链场景也表现出良好适应能力,具备推理泛化性。
L1提供了一种灵活调节推理时间的新范式,能够更精细地平衡计算开销与推理性能。
s1: Simple Test-Time Scaling
https://arxiv.org/abs/2501.19393
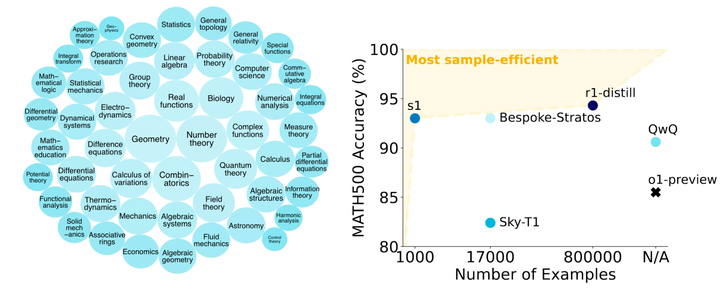
这篇论文提出一种无需重训练即可提升模型推理质量的测试阶段增强方法。通过引入“思维延时”机制,模型被鼓励在生成答案前进行更充分的内部验证,从而提高推理准确性。
主要贡献包括:
-
提出“预算强制”技术,通过添加“Wait”指令延长模型推理时间,引导其自我修正; -
构建小规模高质量数据集s1K,涵盖多种数学题型和高难任务; -
在Qwen2.5-32B模型上高效微调,仅用1000样本、26分钟训练时间实现显著性能提升; -
实验中s1-32B在AIME24任务中准确率由50%提升至57%,超过OpenAI o1-preview。
s1展示了在测试阶段通过简单干预提升推理表现的潜力,适合低成本推理增强场景。
ThinkPrune: Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning
原文:https://arxiv.org/abs/2504.01296
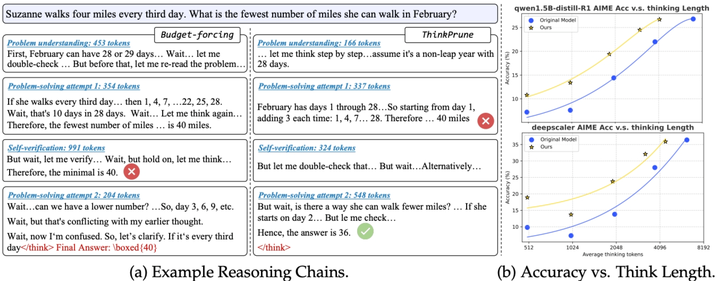
ThinkPrune旨在通过强化学习训练模型生成更简洁的推理路径,解决当前CoT推理中普遍存在的“路径过长”问题,尤其适用于token预算敏感的应用场景。
主要贡献包括:
-
提出引入长度限制的强化学习框架,以惩罚长路径并鼓励有效压缩; -
设计迭代剪枝机制,逐步收紧推理长度约束,确保模型稳定适应; -
在AIME24等数据集上,推理长度减少一半仅带来2%准确率下降,远优于early-stopping策略。
该方法在性能几乎无损的前提下实现了大幅度压缩,适用于需要动态调整计算预算的推理任务。
DAST: Difficulty-Adaptive Slow-Thinking for Large Reasoning Models
原文:https://arxiv.org/abs/2503.04472
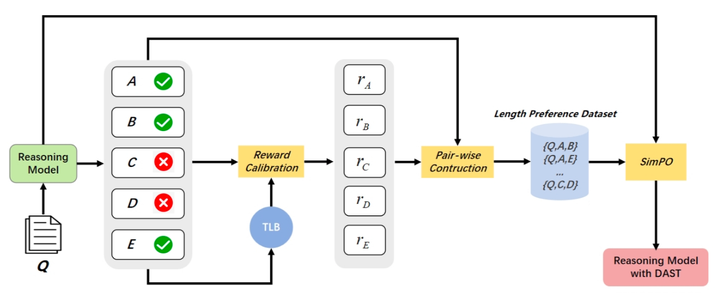
DAST针对“慢思考”模型在简单任务中过度推理的问题,提出引入任务难度感知机制,让模型根据问题复杂度灵活调整推理深度,从而优化资源使用。
主要贡献包括:
-
提出Token Length Budget指标,作为问题难度的计算资源分配依据; -
基于强化学习的奖励机制,在简单任务中惩罚冗余推理,复杂任务中鼓励深度思考; -
在多个模型和数据集上实验证明,平均推理长度减少超30%,准确率保持稳定。
DAST提供了一种任务难度驱动的推理控制路径,是适应型推理机制的重要探索方向。
Fast-Slow Thinking for Large Vision-Language Model Reasoning
原文:https://arxiv.org/abs/2504.18458

这篇论文将快慢思维策略首次扩展到视觉语言模型(LVLMs),解决其在不同任务复杂度下推理路径“过一不及”的问题。
主要贡献包括:
-
提出FAST-GRPO方法,根据视觉问题难度动态切换快思维与慢思维; -
引入复合奖励机制,结合准确性、结构清晰性和推理长度控制; -
使用难度感知KL正则机制,增强推理稳定性与泛化能力; -
在7个视觉推理数据集上实验证明,在推理链减少32.7%至67.3%的同时,准确率普遍提升10%以上。
FAST将“思维切换”理念从语言推理迁移至多模态任务,为视觉大模型推理优化提供了新方向。
Deconstructing Long CoT: A structured Reasoning Optimization Fframework for Long CoT
原文:https://arxiv.org/abs/2503.16385

随着大语言模型的发展,模型通过长链推理进行推理的能力显著提升。然而,长链推理的训练成本高昂,且现有蒸馏方法的普遍性存在争议。为了提高推理效率和成本效益,本文提出了DLCoT(Deconstructing Long Chain-of.Thought)框架,旨在优化长链推理数据,通过智能分割、冗余消除和错误纠正来提升模型性能。DLCoT框架包括五个核心步骤:宏观结构解析、方法与验证解析、冗余分析、优化整合和连贯性重构。该方法通过系统地解构长链推理结构,消除冗余和错误,保留关键逻辑,显著提高了模型性能和 token 效率。本文在三个公开数据集NuminaMath、Bespoke-Stratos和MATH500上验证了 DLCoT的有效性。实验结果表明,DLCoT在多个基准测试上显著提升了模型性能,同时减少了token 使用量。
Towards Thinking-Optimal Scaling of Test-Time Compute for LLM Reasoning
原文:https://arxiv.org/abs/2502.18080
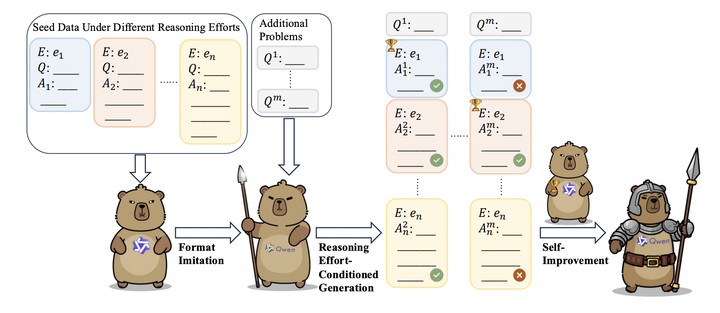
近期研究表明,通过延长思维链能够促使模型进行更长时间的思考,进而显著提升其在复杂推理任务中的表现。当前研究持续探索通过扩展大语言模型的思维链长度来增加测试时计算量的效益,但本文发现这种测试时扩展的追求背后潜藏着个关键问题:过度延长思维链长度反而会损害模型的推理性能。本文通过实验证明:在某些领域,过长的思维链确实会弱LLMs的推理能力,且不同领域存在各自最优的扩展长度分布。基于这些观察,本文提出了”最优思维扩展”策略,首先利用包含不同响应长度分布的少量种子数据,指导模型针对深度思考调整推理强度,随后让模型在额外问题上根据不同推理强度选择其最短的正确响应以实现自我改进。基于Qwen2.5-32B-Instruct构建的自我改进模型,在多项数学基准测试中超越了其他基于蒸馏的32B o1类模型,并与QwQ-32B-Preview达到同等性能水平。
ShorterBetter: Guiding Reasoning Models to Find Optimal Inference Length for efficient Reasoning
原文:https://arxiv.org/abs/2504.21370
大语言模型通过延长思维链的长度,在需要深入推理的任务上表现优异。虽然更长的推理链有助于对复杂问题的解法路径进行更全面的探索,但实验发现,这些模型常常“过度思考”,导致推理效率低下。为此,本文提出了 ShorterBetter——一种简单而有效的强化学习方法,使推理语言模型能够在无需人工干预的情况下,自主发现最优的 CoT 长度。具体地,本文对每个问题采样多个输出,并将“样本最优长度”定义为所有正确响应中最短的那个。该方法通过动态引导模型向该最优长度收敛,从而实现高效推理。在 DeepSeek-Distill-Qwen-1.5B 模型上的实验证明,ShorterBetter 能在内外部域的推理任务中,将输出长度最多压缩 80%,同时保持准确率不变。本文的分析表明,过长的推理链往往会丧失推理方向性,进一步说明推理模型产生的冗长 CoT 具有很高的可压缩性。
How Well do LLMs Compress Their Own Chain-of-Thought? A Token Complexity Approach
原文:https://arxiv.org/abs/2503.01141

思维链提示已成为提升大型语言模型推理能力的有力工具,但这些推理链往往过于冗长,从而降低了推理效率。已有研究尝试通过诸如“保持回答简洁”等简单提示策略来缩短响应长度。本文首次系统地研究了在不同压缩指令下,推理链长度与模型性能之间的关系。实验表明,在各类推理任务中,推理长度与准确率之间普遍存在权衡:无论推理链形式如何变化,过度压缩或过度冗长都会影响最终表现。本文进一步提出并验证了“token 复杂度”概念——即成功完成给定任务所需的最小 token 数量。基于这一概念,本文推导出信息论意义下的准确率–压缩极限,并发现现有的基于提示的压缩策略与该理论极限相距甚远,表明仍有巨大改进空间。本文的框架不仅为评估推理效率的进展提供了基准,还强调了自适应压缩的重要性:对于简单问题应输出更简短的回答。最后,本文展示了 token 复杂度如何作为衡量和指导这种自适应能力的有效工具。
Demystifying Long Chain-of-Thought Reasoning in LLMs
原文:https://arxiv.org/abs/2502.03373
随着推理计算规模的扩大,大语言模型在长链推理方面表现出色。然而,Long-CoT的生成机制及其在强化学习中的稳定训练仍面临挑战。为了提升长链推理的稳定性和效率,本文系统地研究了长思维链生成的关键因素,特别是监督微调和强化学习在训练中的作用。本文提出的方法主要包括: (1)使用长思维链数据进行监督微调,以简化训练过程并提高效率;(2)引入余弦长度缩放奖励和重复惩罚,以稳定长思维链的生成;(3)利用噪声但多样化的Web数据,通过适当的过滤机制,生成高质量的奖励信号。本文在多个公开数据集上进行了实验,包括MATH、AIME 2024、TheoremQA和MMLU-Pro-1k,以评估不同训练策略的效果。实验结果表明,长思维链有监督微调可以显著提升模型性能,并且在强化学习训练中表现出更好的稳定性和效率。
TokenSkip: Controllable Chain-of-Thought Compression in LLMs
原文:https://arxiv.org/abs/2502.12067
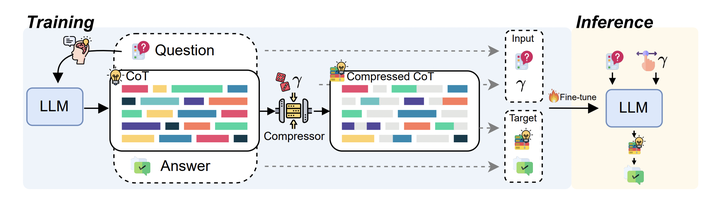
思维链方法已被证明可以增强大型语言模型的推理能力。然而,随着CoT长度的增加,自回归解码导致推理延迟线性增加,严重影响用户体验。为了提高推理效率,本文分析了CoT输出中各个token的语义重要性,发现它们对推理的贡献不同。并基于这一发现,提出了 TokenSkip方法,通过选择性跳过不重要的token来实现可控的CoT压缩。该方法首先计算每个CoT token的语义重要性,然后根据重要性值对token进行排序并修剪。经过修剪的CoT序列用于训练目标LLM,使其在推理过程中能够自动跳过不重要的token,从而实现高效推理。本文在GSM8K和MATH-500两个数学推理基准数据集上进行了实验,评估了 TokenSkip在不同压缩比下的性能。结果表明,TokenSkip能够在减少token使用量的同时保持较强的推理性能,特别是在Qwen2.5-14B-Instruct模型上,实现了40%的token减少,性能下降不到0.4%。
Missing Premise exacerbates Overthinking: Are Reasoning Models losing Critical Thinking Skill
原文:https://arxiv.org/abs/2504.06514

本文发现推理模型(如DeepSeek-R1)遇到条件缺失的问题时,平均响应长度和正常的问题导致的过度思考相比平常会增长2-4倍,但却仍然无法有效识别问题的合理性。这一现象和大家广泛讨论的test-time scaling law相悖,更长的长度反而带来了更糟糕的结果。相比之下,非推理模型反而更为清醒,用更短回答果断质疑问题合理性,体现出在缺失条件的情况下更强的鲁棒性。通过对输出的详细分析,本文发现,与正常情况下的思维链相比,模型在面对条件缺失的问题常常陷入自我怀疑的泥潭,不断地回顾问题、回顾定义、猜测用户意图,最后导致了回答长度的爆炸性增长。实验证明,其实模型常常能在非常早的阶段就能对条件缺失的问题产生质疑,但没有足够的自信和勇气直接承认这样的结果,而是不断的进行无效的思考。
Small Models Struggle to Learn from Strong Reasoners
原文:https://arxiv.org/abs/2502.12143
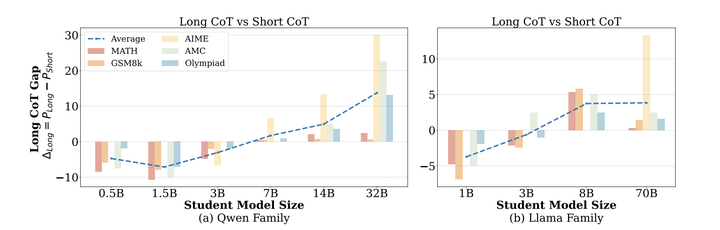
大型语言模型在复杂推理任务中表现出色,将它们的推理能力提炼到较小的模型中也显示出潜力。然而,本文发现小型模型(参数量≤3B)并不能始终从长链思考推理或从较大模型中提炼受益。相反,当它们在更短、更简单的推理链上进行微调时,表现得更好,这些推理链更符合其内在的学习能力。为了解决这一问题,本文提出了混合蒸馏,这是一种简单而有效的策略,通过结合长链和短链思考示例或来自较大和较小模型的推理,平衡推理复杂性。实验表明,与仅使用单一数据集训练相比,混合蒸馏显著提高了小型模型的推理性能。这些发现突显了直接强模型蒸馏的局限性,并强调了适应推理复杂性以有效转移推理能力的重要性。
(文:机器学习算法与自然语言处理)