

编辑:泽南、+0
今年的两篇最佳论文一作均为华人。
近日,国际系统领域顶会 MLSys 2025 公布了最佳论文奖。
今年的大奖颁发给了来自华盛顿大学、英伟达、Perplexity AI、卡耐基梅隆大学的 FlashInfer,以及瑞典查尔摩斯理工大学的《The Hidden Bloat in Machine Learning Systems》。
对此,英伟达第一时间发出祝贺,并表示「FlashInfer」的「LLM 推理内核能力」已经被集成到 vLLM 项目、SGLang 以及自定义推理引擎中。

FlashInfer 最初是华盛顿大学 Paul G. Allen 计算机科学院、卡耐基梅隆大学及陈天奇的创业公司 OctoAI 共同发起的合作研究项目,旨在创建一个灵活的大语言模型(LLM)推理内核库,提供 LLM GPU 内核的高性能实现,如 FlashAttention、SparseAttention、PageAttention、Sampling 等。
英伟达表示,首个适用于 DeepSeek MLA 的 Blackwell 内核也出自 FlashInfer。
FlashInfer 独立于引擎,高度优化,并且易于扩展以支持新技术,例如键值缓存复用算法。现在,它已成为一个蓬勃发展的开源项目,可生产部署,并得到了来自整个 AI 系统社区研发团队的贡献。

-
论文:FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving -
论文链接:https://arxiv.org/abs/2501.01005 -
项目主页:https://flashinfer.ai/ -
GitHub 仓库:https://github.com/flashinfer-ai/flashinfer
Transformer 结构以注意力机制(Attention Mechanism)为核心,是大型语言模型(Large Language Models,LLMs)的基础。随着模型规模的不断扩大,高效的 GPU 注意力计算模块(attention kernel)对于实现高吞吐和低延迟(即更快、更高效)的推理至关重要。面对多样化的 LLM 应用场景,亟需灵活且高性能的注意力解决方案。
研究团队提出了「FlashInfer」:一款可定制且高效的注意力推理引擎,专为 LLM 部署优化设计。其主要特点如下:
-
优化内存访问并减少冗余:FlashInfer 通过采用块稀疏格式(block-sparse format)与可组合格式(composable formats)解决键值缓存(KV-cache)存储的异构性问题。
-
可定制的注意力计算模板:支持基于即时编译(Just-In-Time,JIT)的灵活配置,以应对不同应用需求。
-
高效的任务调度机制:FlashInfer 引入了基于负载均衡的调度算法,既能适应用户请求的动态变化,又与要求静态配置的 CUDAGraph 保持兼容性。
经过内核级(kernel-level)及端到端(end-to-end)的完整评估,FlashInfer 在多种推理场景下显著提升了计算性能:与当前最先进的 LLM 部署方案相比,FlashInfer 在 token 间延迟方面提高显著,相较通用编译器后端,能减少 29% 至 69% 的 inter-token 延迟;在长上下文推理任务中延迟降低 28% 至 30%;在并行生成场景下,推理速度提升达 13% 至 17%。
系统设计

近年来,为提升内存效率,KV-Cache 存储机制(如 PageAttention、RadixAttention)开始采用非连续内存布局,以块或 token 为最小存储单元。
FlashInfer 证明,这些不同的非连续 KV-Cache 数据结构都可以统一抽象建模为块稀疏矩阵格式(如图 2 所示)。

在此基础上,FlashInfer 进一步引入组合式稀疏格式(Composable Sparse Formats)来提升内存效率。与单一固定块大小的格式不同,组合式格式允许在同一稀疏矩阵中灵活采用多种块稀疏形式,从而显著提高内存利用率。
单一块格式的局限在于其固定大小(特别是行块大小 Br)导致的碎片化风险和共享内存互访限制。组合式格式则可以根据数据特征(如共享前缀形成逻辑上的稠密子矩阵)选用合适的块形式(例如为稠密子矩阵选用较大的 Br)。
如图 3 所示,这种方式无需数据移动,仅通过索引即可实现基于共享内存的高速访问,进一步优化内存效率。
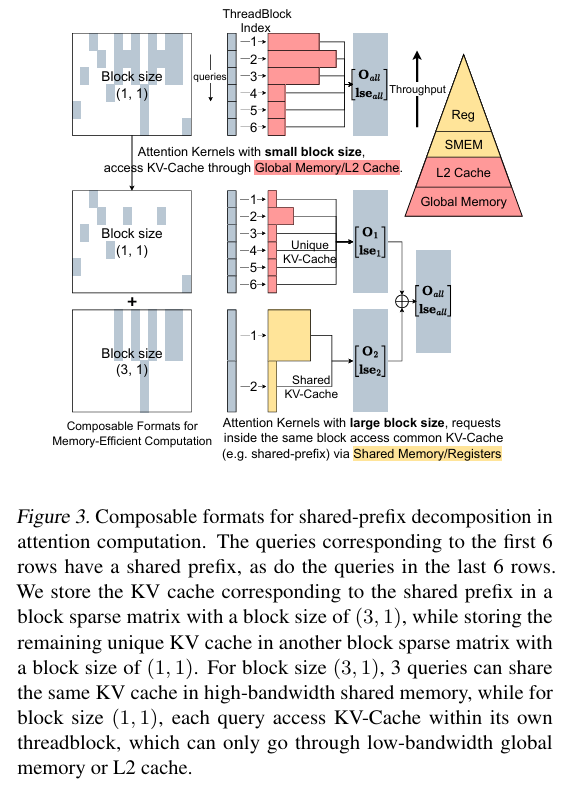
FlashInfer 的 KV-Cache 具体实现采用块稀疏行格式(Block-Sparse Row, BSR),其块大小 (Br,Bc) 可根据应用动态配置,内核支持对任意配置的高效处理。
2、计算抽象
在计算抽象层面,FlashInfer 基于 CUDA/CUTLASS 模板实现了对 FlashAttention 算法的高效支持。该实现兼容 NVIDIA Turing 到 Hopper 全系架构(即 sm75 至 sm90a),能够原生处理稠密和块稀疏的矩阵运算,与上层统一的 KV-Cache 存储格式紧密结合。
具体实现上,FlashInfer 针对 Ada(sm89)及以下的架构采用了 FlashAttention2(FA2)算法,而对于最新的 Hopper 架构则使用了优化后的 FlashAttention3(FA3)算法,以充分利用各代硬件特性。
3、计算内核优化与硬件适配
为了最大化 GPU 计算单元(如 Tensor Core)的效率,高效的数据加载是关键。FlashInfer 设计了专门机制,将 KV 缓存数据从全局内存快速载入共享内存,尤其针对其支持的块稀疏及非连续格式。加载时,根据块是稀疏或稠密采用不同地址计算(利用 BSR 索引 vs 仿射变换)。
KV 缓存最后一个维度(即注意力头维度 d)保持连续,这使得高效的合并访问(coalesced access)成为可能,显著提升访存效率。数据传输利用 GPU 的异步复制及硬件加速器(如 Hopper TMA,如图 4 所示,需注意其适用性),并自动回退通用路径。
加载到共享内存后,FlashInfer 基于 FlashAttention 算法的计算内核进一步优化。为适应大语言模型运行时多变的计算强度和不同 GPU 架构资源(如 Ada 共享内存限制),内核支持多种不同的 tile 尺寸组合。
这解决了传统固定尺寸在短序列解码等场景效率不高的问题(例如在 A100 上预填充表现最佳的 (128,64))。
FlashInfer 提供一系列 tile 范围,并结合启发式策略自适应选择最优尺寸:例如,基于平均查询长度选择行块大小 Br,或通过资源消耗模型最大化 SM 利用率。这种方法确保 FlashInfer 在不同负载和硬件平台均能高性能运行。
4、注意力变体灵活性、用户接口与动态调度
当前大语言模型使用了大量注意力变体,为每个变体定制高性能 CUDA 内核难以持续。借鉴 Flex Attention,FlashInfer 构建了可自定义的 CUDA 模板和 JIT 编译器。
用户只需通过定义一系列函数子模块(functor)来指定变体逻辑(如 Query/Key/Value/Output/Logits 的变换与掩码),JIT 编译器即可生成优化的变体专用内核。
这种设计使得 FlashInfer 能灵活支持自定义掩码、滑动窗口、非 Softmax 变体(如 FlashSigmoid,如图 5 所示其映射方式)以及将 RoPE、归一化、投影等前处理操作融合进 Attention 内核,实现高效计算。用户甚至可以直接传入 CUDA 代码。

生成的 CUDA 代码由 JIT 编译器(如 PyTorch 的 JIT)编译为自定义算子,并通过 DLPack 等接口支持框架无关部署。
FlashInfer 提供面向用户的 API,通过初始化 wrapper、传入变体描述和任务信息来完成内核的 JIT 编译和缓存。对于组合格式,会创建对应 wrapper。根据 KV 缓存配置(如平均查询长度),FlashInfer 在后台将不同内核编译并捕获到 CUDAGraphs 中。运行时,服务框架动态选择最合适的 CUDAGraph 执行。
FlashInfer 采用 Plan/Run 模式处理不规则负载:
-
Plan 函数在 CPU 上运行,处理序列长度等数据,生成负载均衡的调度方案(可缓存复用);
-
Run 函数在 GPU 上执行,接受输入和调度方案数据,执行注意力计算(可被 CUDAGraph 捕获)。这种 Plan/Run 分离设计借鉴了不规则并行计算中的 Inspector-Executor (IE) 模式。
作者介绍
FlashInfer 的第一作者叶子豪(Zihao Ye)是华盛顿大学(University of Washington)的博士生,导师为 Luis Ceze。

叶子豪与陈天奇在机器学习编译器方面有密切合作,也曾在英伟达实习,合作者为 Vinod Grover,他还曾获得 2024-2025 年度英伟达研究生奖学金。
加入华盛顿大学之前,叶子豪在 AWS 工作了两年,期间跟随王敏捷、张峥研究机器学习系统。他的本科毕业于上海交通大学 ACM 班。
叶子豪目前的主要研究方向是机器学习编译器和稀疏计算。
The Hidden Bloat in Machine Learning Systems
共同获得今年最佳论文奖项的还有来自瑞典查尔摩斯理工大学的一篇论文。

-
论文:The Hidden Bloat in Machine Learning Systems
-
链接:https://arxiv.org/abs/2503.14226
软件臃肿(software bloat)是指软件在运行时未使用的代码和功能。对于机器学习系统而言,臃肿是其技术债务的主要原因,会导致性能下降和资源浪费。
在该工作中,作者提出了 Negativa-ML,可通过分析 ML 框架的共享库来识别和消除其中的臃肿。作者提出的方法包括一些新技术,用于检测和定位设备代码中不必要的代码——这是现有研究(主要关注主机代码)所忽略的关键领域。
作者使用四种流行的 ML 框架,在 300 个共享库的十个工作负载中对 Negativa-ML 进行了评估。结果表明,ML 框架在设备和主机代码端都存在严重的臃肿问题。
平均而言,Negativa-ML 可将这些框架中的设备代码大小减少高达 75%,主机代码大小减少高达 72%,最终文件总大小减少高达 55%。
设备代码是 ML 框架中臃肿的主要来源。通过减少膨胀,新方法分别可将峰值主机内存使用量、峰值 GPU 内存使用量和执行时间减少了多达 74.6%、69.6% 和 44.6%。

Negativa-ML 概览,该研究中提出的组件以黄色矩形突出显示。
作者介绍
本文一作 Huaifeng Zhang 是查尔姆斯理工大学的博士生,主要研究方向是 MLsys、云计算、分布式系统和区块链。

(文:机器之心)