
西风 发自 凹非寺
量子位 | 公众号 QbitAI
和人工标记数据说拜拜,利用预训练语言模型中的注意力机制就能选择可激发推理能力的训练数据!
字节Seed团队最新宣布了一个重要成果——AttentionInfluence。
无需训练,无需标签,只需用1.3B模型给7B模型选择数据,就能提升模型推理能力,甚至也能提升代码生成能力。

以往,筛选数据的方法通常依赖于监督分类器,需要人工或大语言模型进行标注,难免引入领域特定偏见。
字节Seed团队注意到:
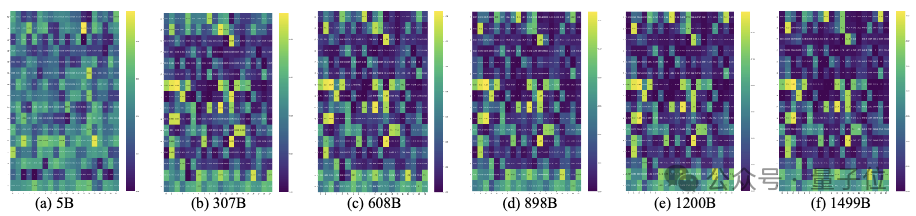
预训练模型中的检索头与检索和上下文推理紧密相关。
检索头在训练早期就会出现,逐渐增强,并最终在训练的中后期阶段牢固建立,对模型性能起到至关重要的作用。
1.3B参数稠密模型中检索头的演化过程,be like:
但如果直接关闭它们会怎样?
他们用小型预训练语言模型通过简单的注意力头屏蔽操作,充当强大的模型的数据选择器。
具体操作是,识别重要检索头,屏蔽这些头以创建性能下降的“弱”模型,计算“弱”模型与原始“强”模型之间的损失差异,根据损失增加幅度对数据进行排名,形成影响分数。
没想到,实验后他们得到了一个惊人结果。
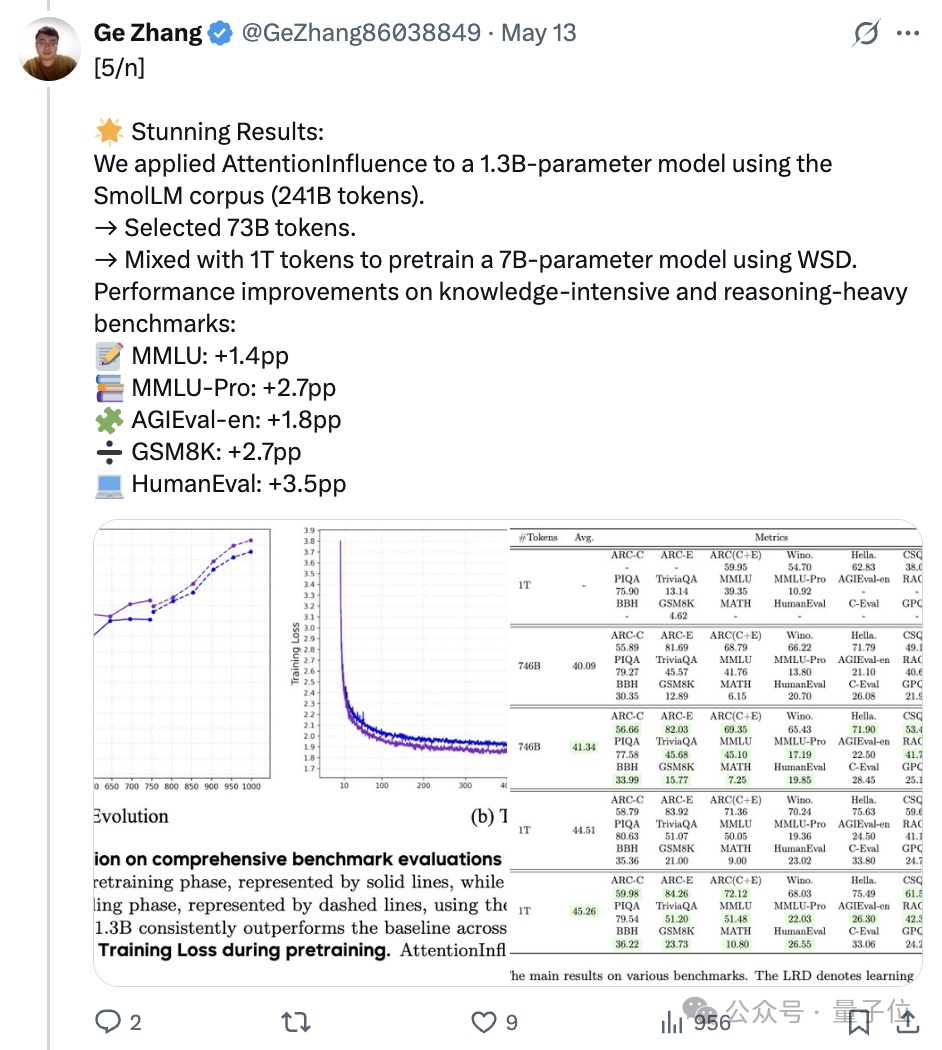
将AttentionInfluence方法应用于1.3B参数预训练语言模型,对SmolLM语料库进行数据选择,筛选出73.1B tokens与完整的SmolLM语料库组合,使用WSD方法预训练7B模型。
在知识密集型和推理密集型基准测试中模型性能均有提升,具体来说:
MMLU+1.4个百分点、MMLU-Pro+2.7个百分点、AGIEval-en+1.8个百分点、GSM8K+2.7个百分点、HumanEval+3.5个百分点。
这项研究发布后引来不少网友关注,谷歌DeepMind研究科学家都转发为其点赞:
有网友看后表示:
多么简单而巧妙的数据选择思路!

关于这项研究的更多细节,我们接着往下看。

让预训练模型识别重要数据
如前所述,AttentionInfluence方法的核心思想是通过比较基础模型和弱化参考模型之间的损失差异来评估训练数据的对推理的影响程度。
实现方法包含两个主要步骤:检测特定重要头部、计算AttentionInfluence分数。
检测特定重要头部
在本研究中,作者主要关注检索头,此前已有研究表明检索头与大语言模型的检索和推理能力高度相关。
受CLongEval中提出的关键段落检索评估任务启发,团队采用了一种类似的简单proxy task,在可控环境下评估大语言模型的检索能力,并识别与检索和推理强相关的注意力头。
为此,他们构建了一个包含800个样本的合成测试数据集。每个样本被格式化为一个3-shot自然语言检索任务,由上下文、三个上下文中的示例和一个查询hash_key组成。

每个上下文是一个包含k个键值对(key-value pairs)的JSON对象,其中每个键是随机生成的32字符字母数字字符串(hash_key),每个值(text_val)是从网络文档语料库中采样的自然语言句子。
该任务要求模型从上下文中检索text_val,并输出与给定查询hash_key对应的text_val。
包含三个上下文中的示例(即3-shot)旨在模拟小样本学习场景,并帮助模型理解任务。考虑到现有预训练模型的上下文长度限制,团队将每个测试样本的总长度(包括输入提示和答案)限制为接近但不超4096token。
接下来,计算每个注意力头在测试样本上的检索分数。
在这项工作中,团队使用一个基于类Llama 2架构的1.3B参数模型作为小型预训练语言模型,使用平均分数作为头的最终检索分数,并按该分数对其进行排序,选择排名前5%的头作为特别重要的头。
计算AttentionInfluence分数
获得重要头部后,接下来计算每个样本的AttentionInfluence分数。
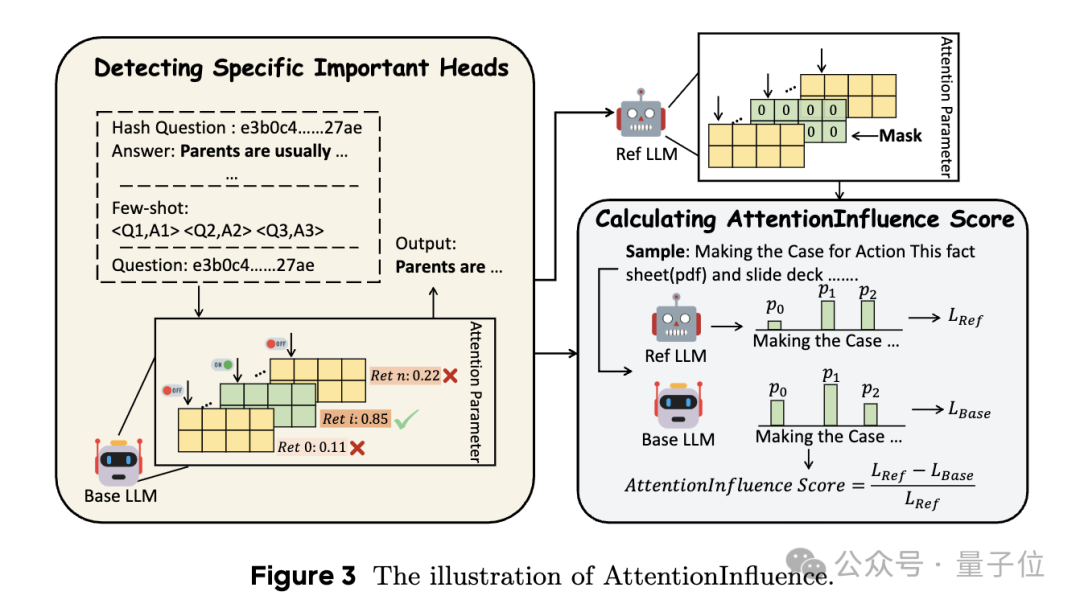
首先是创建参考模型,通过屏蔽在第一阶段检测到的基础模型的重要头部,获得参考模型。
然后,使用基础模型计算语料库中每个样本的平均token级交叉熵损失(Lbase),使用参考模型计算相应的损失(Lref)。
最后将Lbase和Lref之间的相对差值作为注意力影响分数,以量化每个样本的推理影响程度,其计算公式如下:
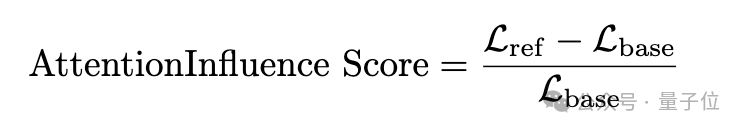
由于语言模型对来自不同领域(如通用领域、数学领域、代码领域)的数据的损失,因分布差异显著而无法直接比较,团队将注意力影响分数的比较限制在相同领域内。
团队认为,注意力影响分数越高,表明样本具有更高的推理强度。
效果全面分析
实验设置上,团队使用Llama2类似的1.3B参数模型作为小型预训练语言模型,对SmolLM语料库进行数据选择.
根据AttentionInfluence分数选择排名前20%的样本,约73.1B tokens,使用选定的73.1B tokens与完整的SmolLM语料库组合,预训练7B参数模型。
作为对比,基线模型则是仅使用SmolLM语料库训练的相同架构和大小的模型。
然后,在小样本学习设置下,团队采用一套涵盖四大类别的综合基准评估,对模型与基线模型进行全面比较:
-
综合基准,包括AGIEval-en、MMLU、MMLU-Pro、GPQA、C-Eval; -
数学、代码和推理,包括GSM8K、MATH、HumanEval、ARC Challenge、DROP、BBH; -
常识推理与理解,包括HellaSwag、ARC-Easy、WinoGrande、CommonSenseQA、PiQA、OpenBookQA、TriviaQA; -
阅读理解,以RACE为代表。
主要研究结果显示,使用AttentionInfluence选择的数据训练的模型在多个关键基准上显著优于基线:

研究还跟踪了预训练过程中的性能演变,AttentionInfluence模型在整个预训练过程中始终优于基线,性能差距在训练早期(约100B tokens之前)就已显现,并在整个训练过程中保持稳定,即使在学习率衰减(LRD)阶段,性能优势仍然存在。
另外,当特定重要头部被屏蔽时,1.3B模型在某些任务上的性能显著下降,而AttentionInfluence方法选择的数据往往能改善7B模型在这些任务上的性能,表明该方法具有预测能力。
将AttentionInfluence应用于更大的7B参数模型进行数据选择时,能在多个知识密集型和推理密集型基准上获得更好的性能,表明增加模型规模有助于选择更高推理强度的样本。

为验证AttentionInfluence的有效性,团队还设计了两个指标来量化所选数据的质量:
-
Education Score:评估内容的教育价值 -
Reasoning Score:评估内容的推理强度
实验结果显示,AttentionInfluence和FineWeb-Edu分类器在教育相关内容上获得相当的分数;在推理方面,AttentionInfluence获得显著更高的分数;在Python-Edu和OpenWebMath领域,AttentionInfluence选择的样本平均长度几乎是FineWeb-Edu分类器选择样本的两倍。
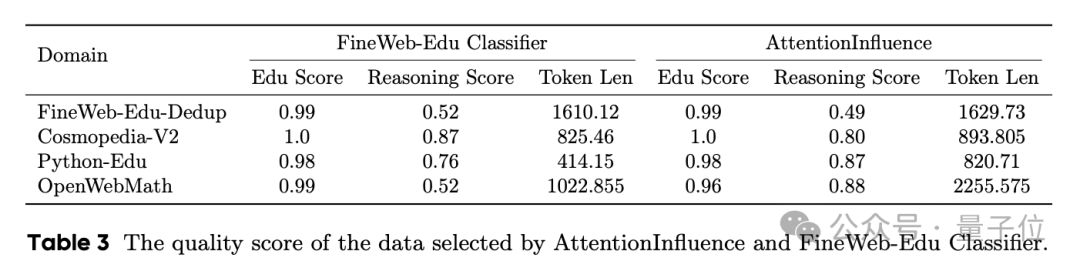
团队也对所选数据进行了多样性分析,感兴趣的童鞋可以查看原论文。
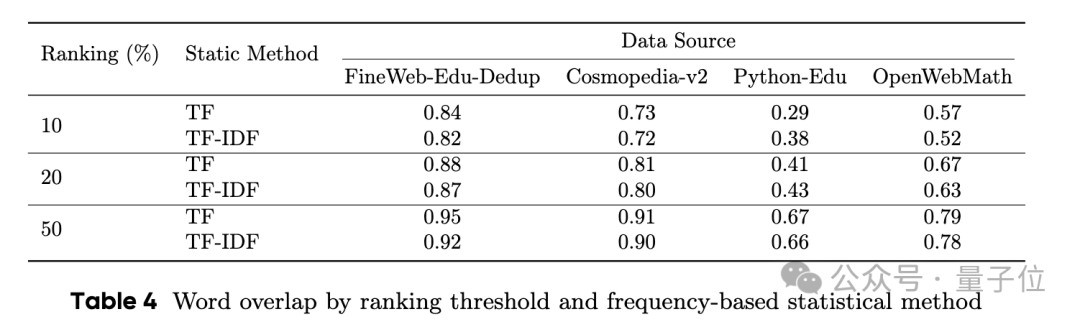
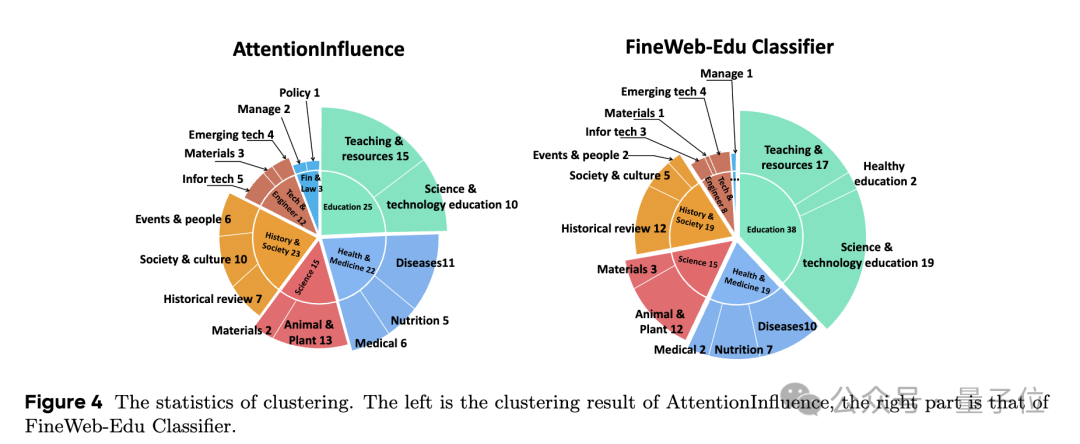
总之,团队表示这些结果验证了AttentionInfluence法能有效地识别高质量的预训练数据,从而增强大语言模型的知识和推理能力,尤其在需要综合知识和复杂推理的基准测试中取得了显著提升。
此外,AttentionInfluence可与 FineWeb-Edu分类器结合使用,以在需要简单事实性知识、高级推理或两者兼具的任务中全面提升大语言模型的性能。
论文链接:https://arxiv.org/pdf/2505.07293
(文:量子位)