


刚刚,腾讯混元发布了全新的图片生成模型——Hunyuan Image2.0。
模型基于超高压缩倍率的图像编解码器、全新的扩散架构、超大模型尺寸和RL后训练,实现了超快推理速度和超高质量图像生成。
有多快呢?我一句Prompt还没打完,它已经生成了3-4张图片。等我Prompt敲完,终版图片当场直接生成(如果是英文prompt,还会更快)。
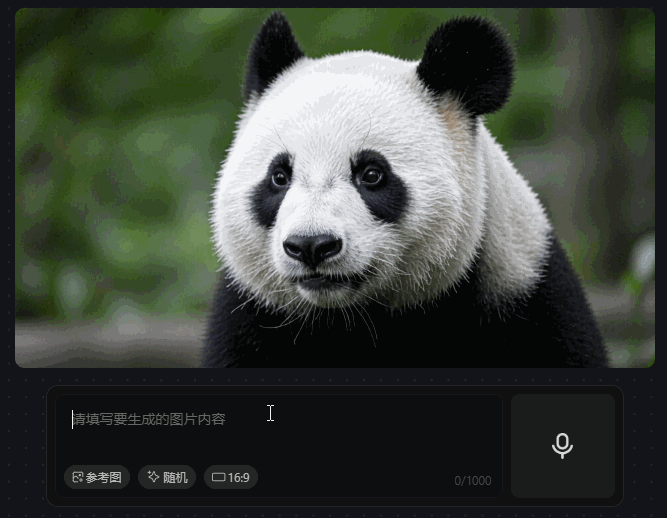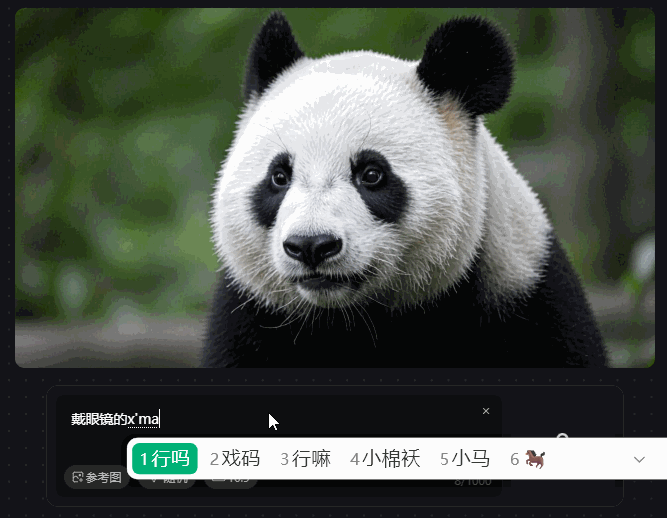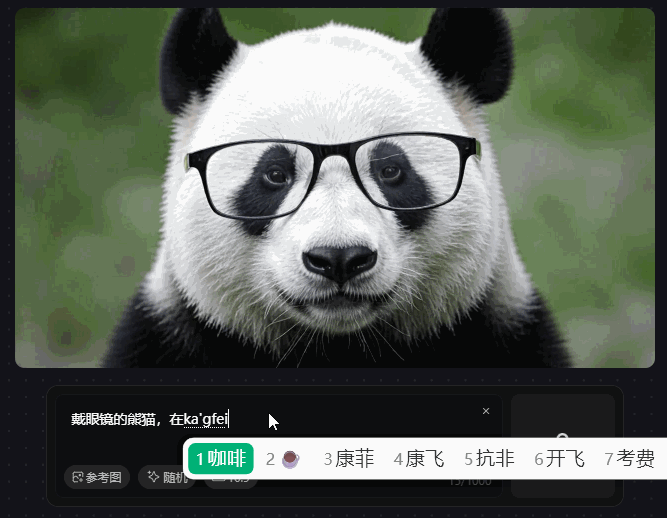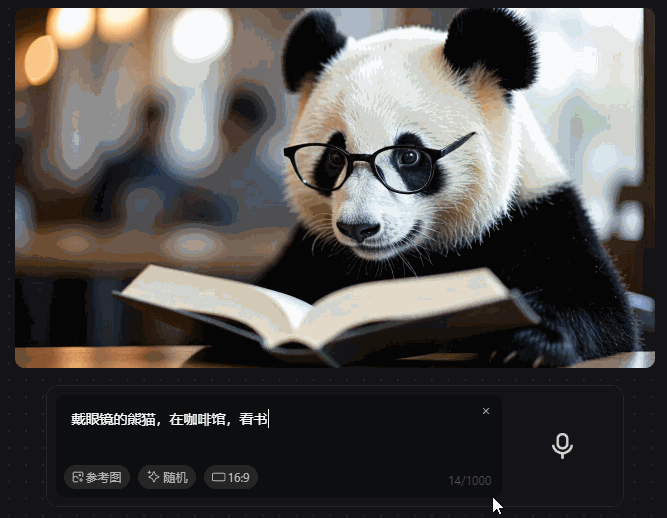
如果我没记错,这可能是有LLM以来第一款能够实时生图的模型。
体验地址:https://hunyuan.tencent.com
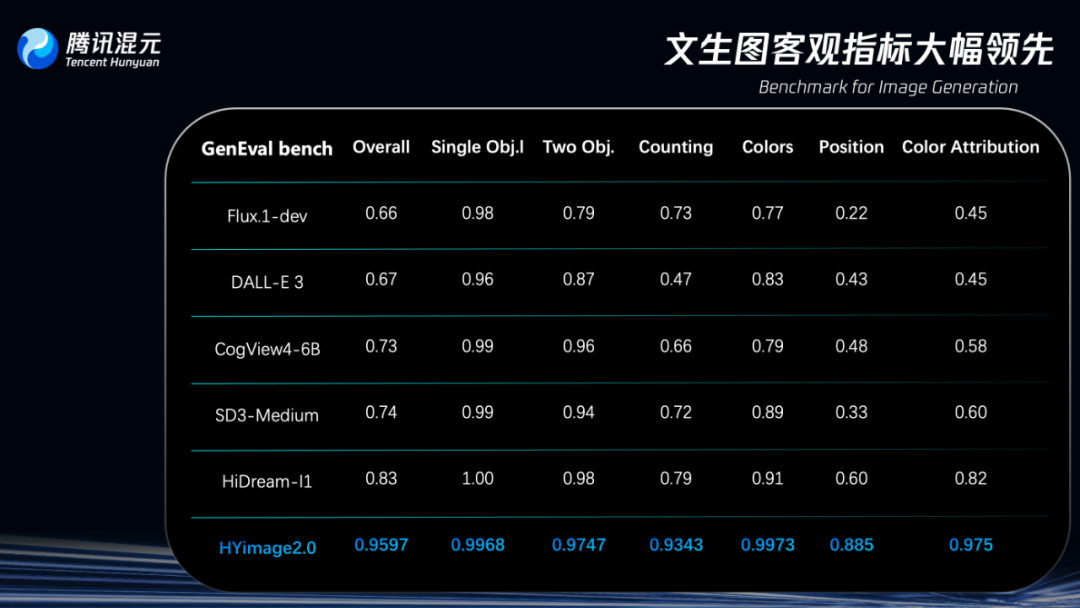
在快这件事情上,Hunyuan真NB。语义响应速度遥遥领先,以0.9597分超过了所有生图模型。

一手实测
1、毫秒出图
1分钟有60秒,1秒又分1000毫秒。Hunyuan Image2.0模型,说“秒出图片”已经有点侮辱它了,实际体验是“毫秒出图”。
Prompt输完,图片也就直接生成,比目前市面上所有的生图模型都要快。

无论多复杂的Prompt,都是毫秒出图。

即使1000字的Prompt,照样“高超响应速”出图。
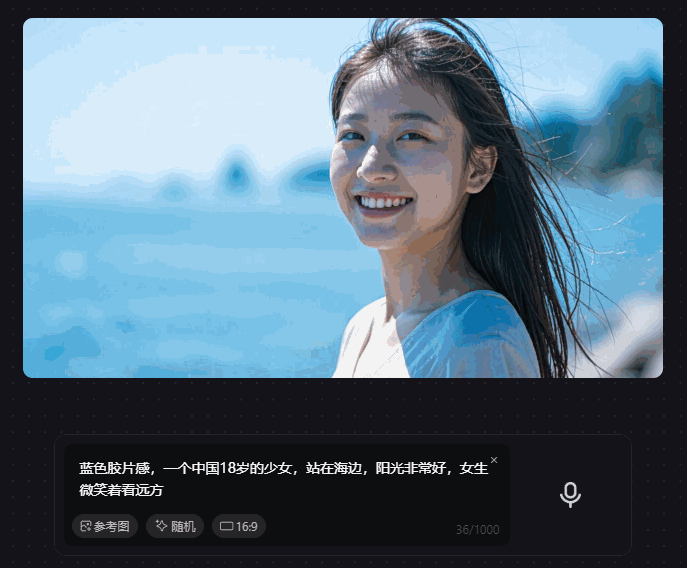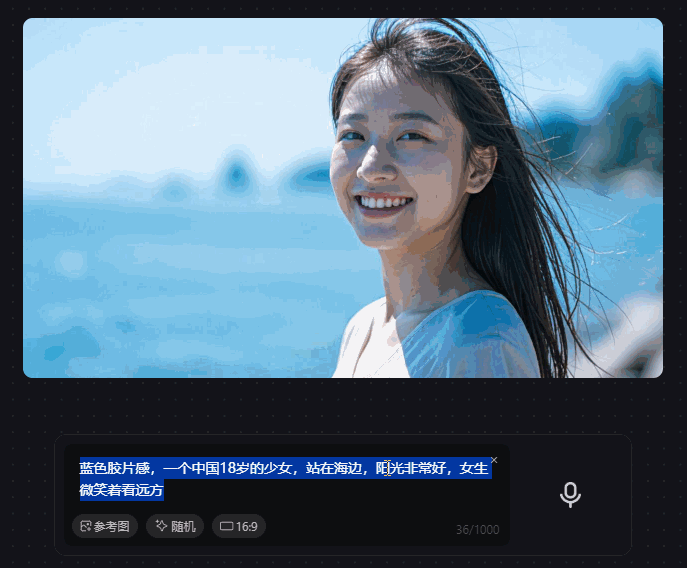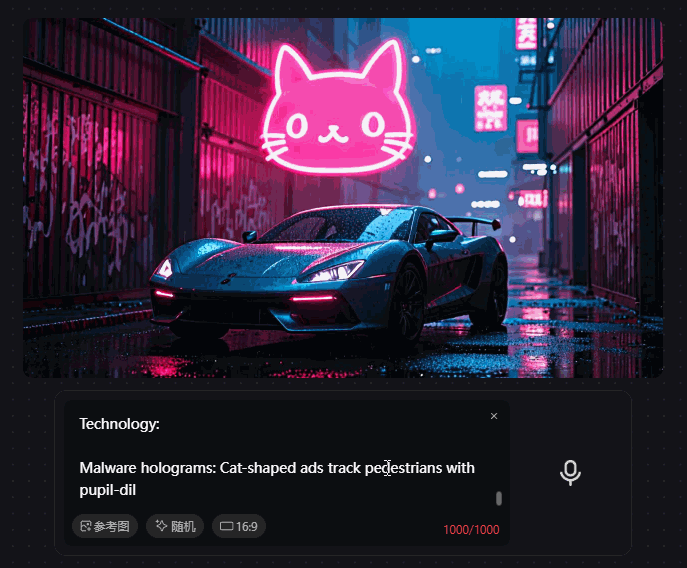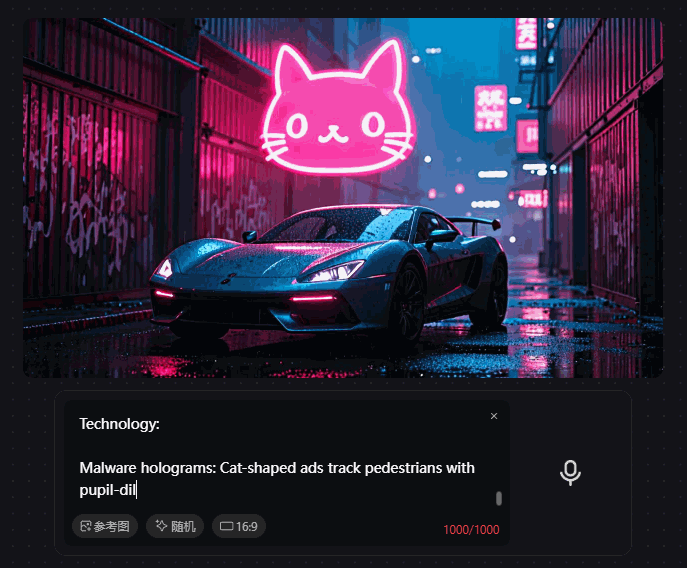
现在,我们正在见证一场改变:从“输入提示词-等待模型生成”的线性节奏,变成了输入与输出同步发生的实时对话。
Speed Is All You Need.
2、还保真
而且,在快的同时,还做到了“真”。
对于AI,真实一直是最宝贵的东西。不是AI开始走进我们的现实,而是AI一直带着滤镜(数据集不够导致的问题),就跟我们人一样,老喜欢臭美。所以,你看到很多由AI生成的人物图,一眼假。
但这个模型通过RL后训练和美学后训练,做到了高写实。主打真实感,没有AI味,在一些真实场景下的生图效果非常好,比如怀旧风、胶片感。
以下,是一些实测case。
一对亚洲情侣在楼顶,背后是城市的街景,80年代。

一对亚洲情侣在楼顶,背后是城市的街景,新世纪。

阳光,少女注视着前方,第一视角,双手捂着眼睛,directed by Wes Anderson

一个日本中学生,穿着校服,孤独地站在海边。

爱因斯坦在故宫自拍。

褪色的老照片,泛黄的色调,一位穿粗布旗袍的温婉女子站在民国茶馆门口,背景有黄包车和斑驳砖墙。

苏州园林的雕花窗前,着马面裙的女子低头绣花,鬓边珍珠流苏轻晃,桌上摆着珐琅彩瓷茶具,柔光透过窗纱形成丁达尔效应。

西部拓荒时代的小酒馆,戴牛仔帽的枪手在玩扑克,木墙上的煤油灯晃动着阴影。

全息演唱会上,二次元与真人混合形象的歌姬悬浮舞台中央,粉丝们的AR眼镜投射出彩色弹幕,激光束穿透干冰雾气。

3、是灵魂画师
都已经是毫秒级出图了,那定是所画即所见。
这次上新,腾讯混元还整了个实时绘画板的功能,左边画参考图,下方输提示词,右边实时预览和生成。
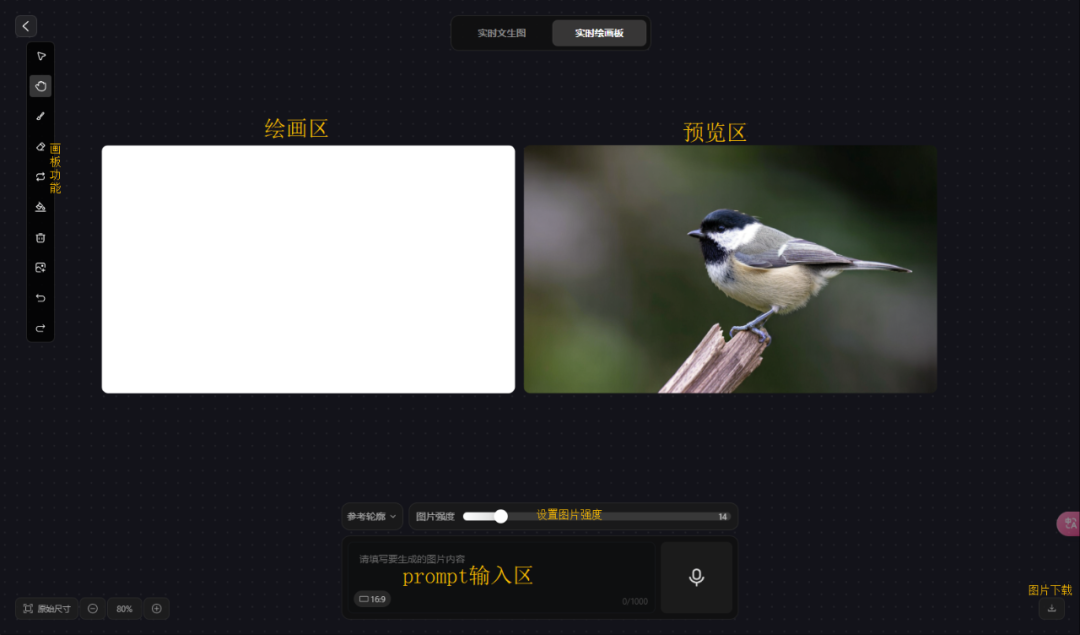
这个功能,非常好玩。我用鼠标随手画了几个,我太喜欢AI的随机之美了。
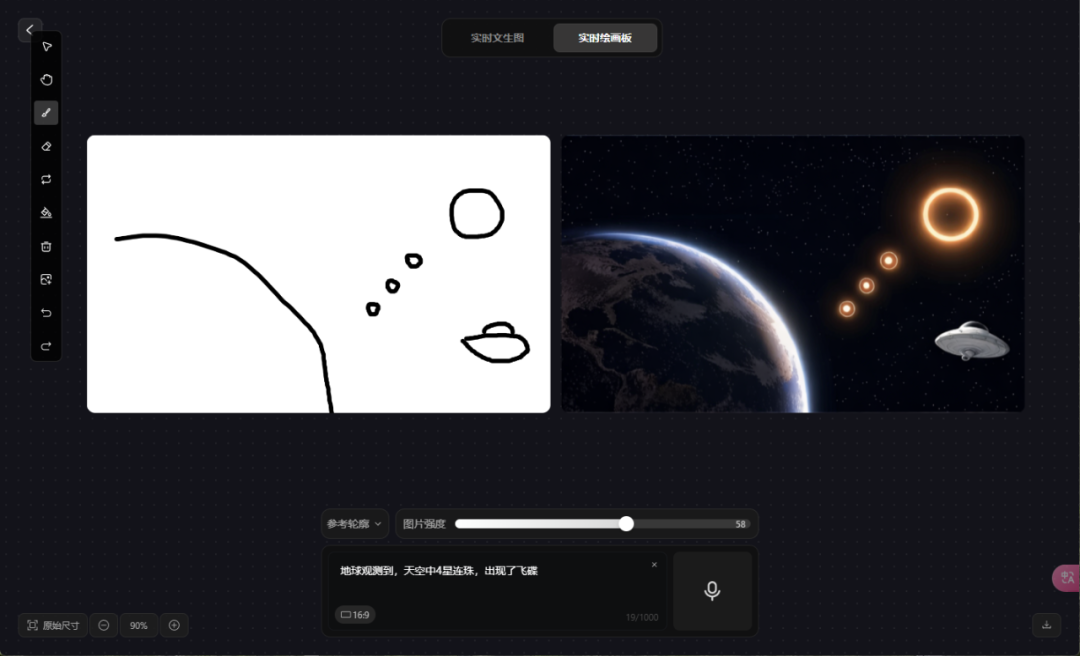
地球观测到,天空中4星连珠,出现了飞碟。参考轮廓,图片强度58。

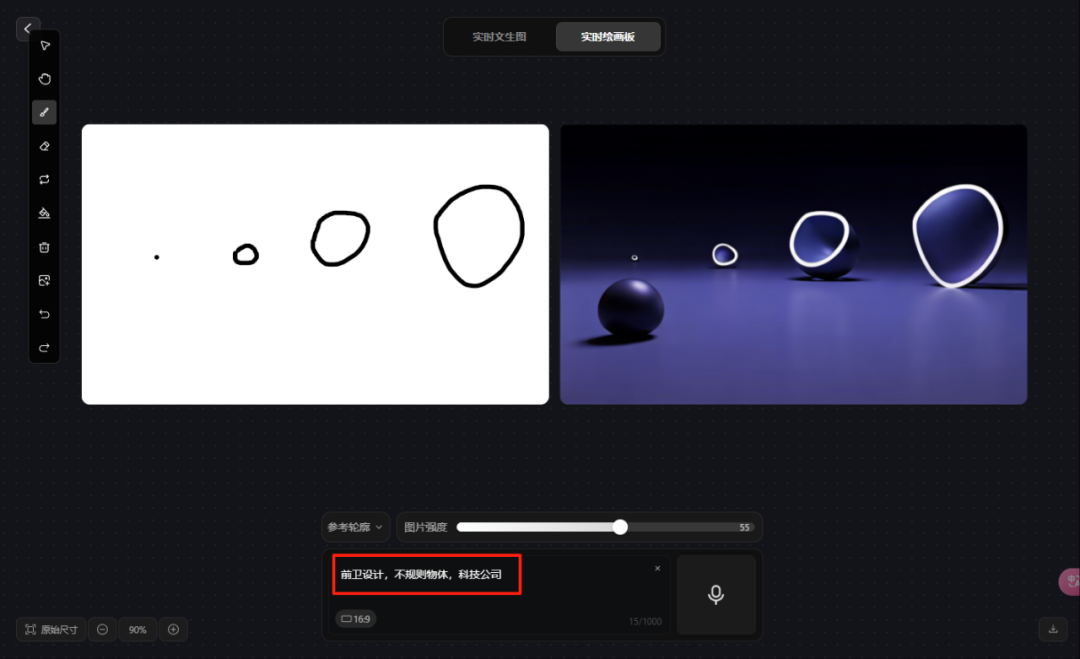
前卫设计,不规则物体,科技公司。参考轮廓,图片强度55。

海边,电影海报,夕阳。参考轮廓,图片强度82。


胶片摄影,草地,河边,白色塑料袋挂在电线杆上,两个电线杆。参考轮廓,图片强度72。
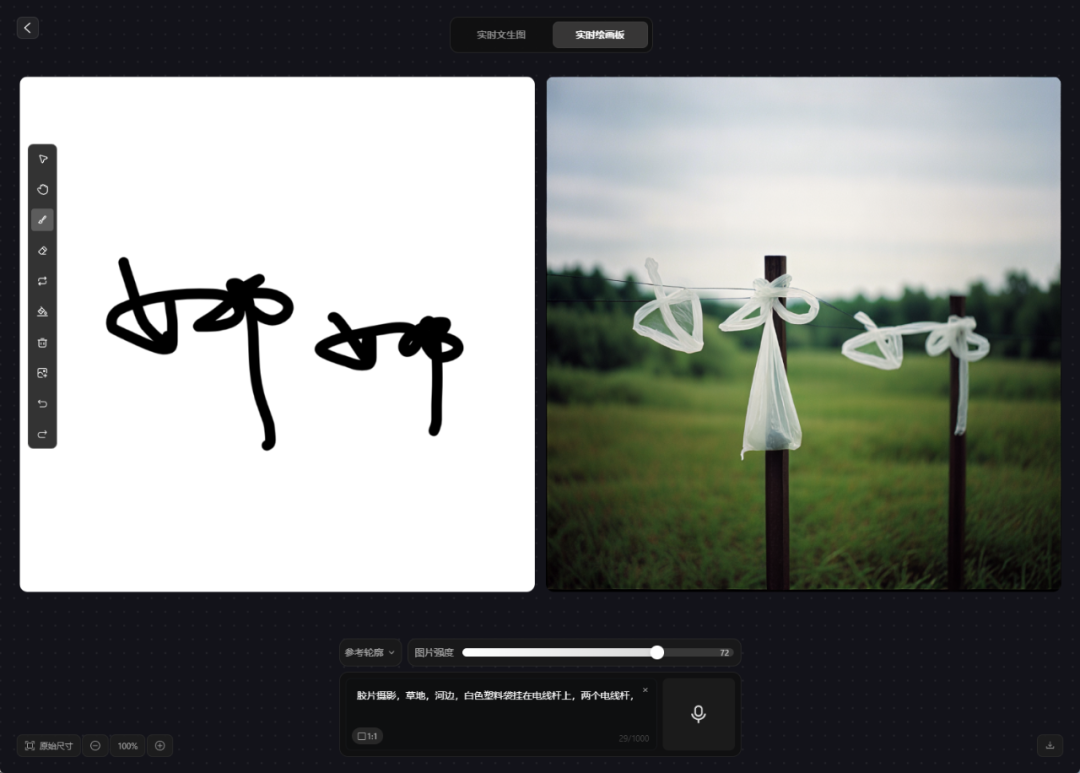

Case来源:一只小小娜
霓虹灯字体,五彩斑斓,背景是城市。图片强度81。
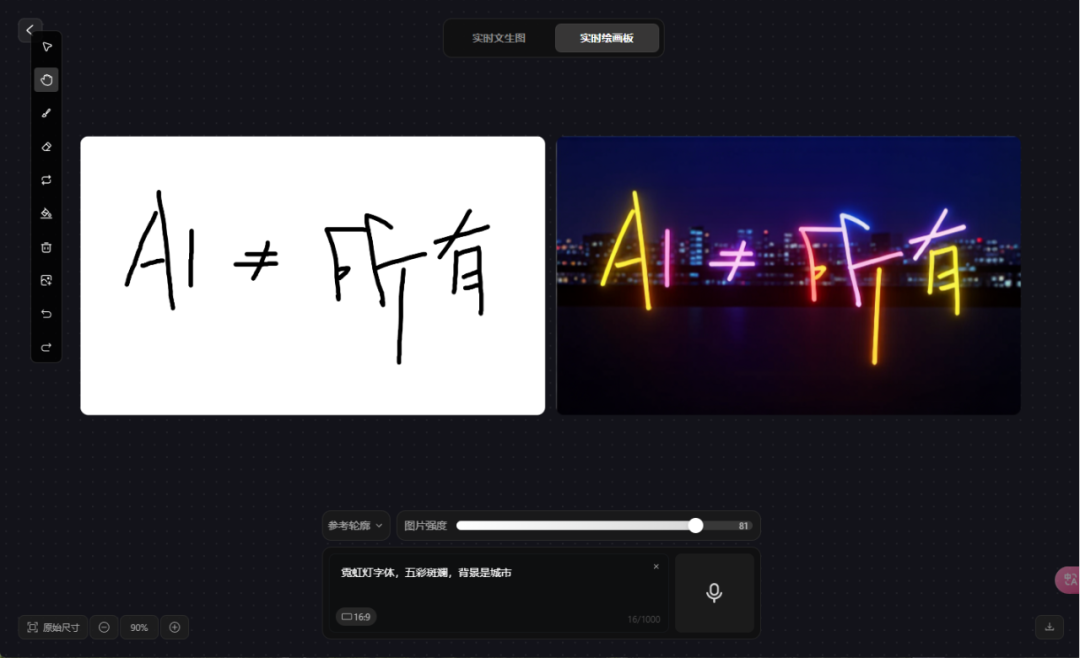

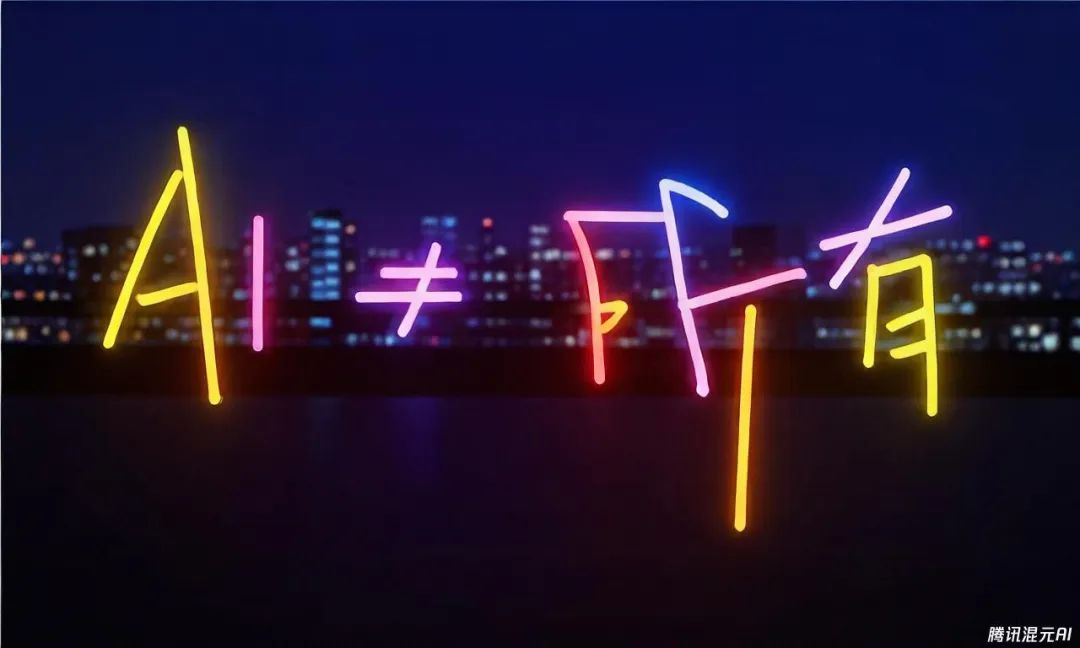
使用中,建议先画图,然后写prompt,再调整图片强度(0-100,建议在50-80之间),来看预览效果。
也可以上传参考图,然后给它画点啥。比如,给画面里增加一只蝴蝶。

憨态可掬的熊猫趴在人的手心里,蝴蝶。参考轮廓,图片强度82。


写在最后
深度体验了一圈,这个模型确实好玩。所以,在混元超创群里,大家一直玩到了凌晨2点过。
因为,完全没有时间成本啊。输入prompt,马上生成。修改prompt,也是立马生成。
很多时候,你prompt还没写好,它已经给你来了5-6张图。这已经不是所思即所见,而是未知先见,边思边见。
真的,当你体验了这种新的实时交互后,再回到过去那种“输入提示词-等待模型生成”的线性节奏,你会很难受。这种难受,就像你回到十六年前拿着黑莓手机用2.5G一样,一种干着急的难受。
欣喜看到,今天腾讯混元为人类Way to AGI干了一件极其重要的事情——实时生成,带来了人类首款实时生图模型。
这一刻,足以载入人类AI事业的史册。
而它,来自中国。
(文:沃垠AI)