

近年来,大型语言模型(LLM)在多模态任务中展现出强大潜力,但现有模型在架构统一性与后训练(Post-Training)方法上仍面临显著挑战。
传统多模态大模型多基于自回归(Autoregressive)架构,其文本与图像生成过程的分离导致跨模态协同效率低下,且在后训练阶段难以有效优化复杂推理任务。
DeepMind 近期推出的 Gemini Diffusion 首次将扩散模型(Diffusion Model)作为文本建模基座,在通用推理与生成任务中取得突破性表现,验证了扩散模型在文本建模领域的潜力。
在此背景下,普林斯顿大学与字节 Seed、北大、清华等研究团队合作提出了 MMaDA(Multimodal Large Diffusion Language Models),作为首个系统性探索扩散架构的多模态基础模型,MMaDA 通过三项核心技术突破,成功实现了文本推理、多模态理解与图像生成的统一建模。

-
论文标题:MMaDA: Multimodal Large Diffusion Language Models
-
论文链接:https://arxiv.org/abs/2505.15809
-
代码仓库:https://github.com/Gen-Verse/MMaDA
-
模型地址:https://huggingface.co/Gen-Verse/MMaDA-8B-Base
-
Demo 地址:https://huggingface.co/spaces/Gen-Verse/MMaDA
团队已经开源训练、推理、MMaDA-8B-Base 权重和线上 Demo,后续还将开源 MMaDA-8B-MixCoT 和 MMaDA-8B-Max 权重。
性能表现与跨任务协同
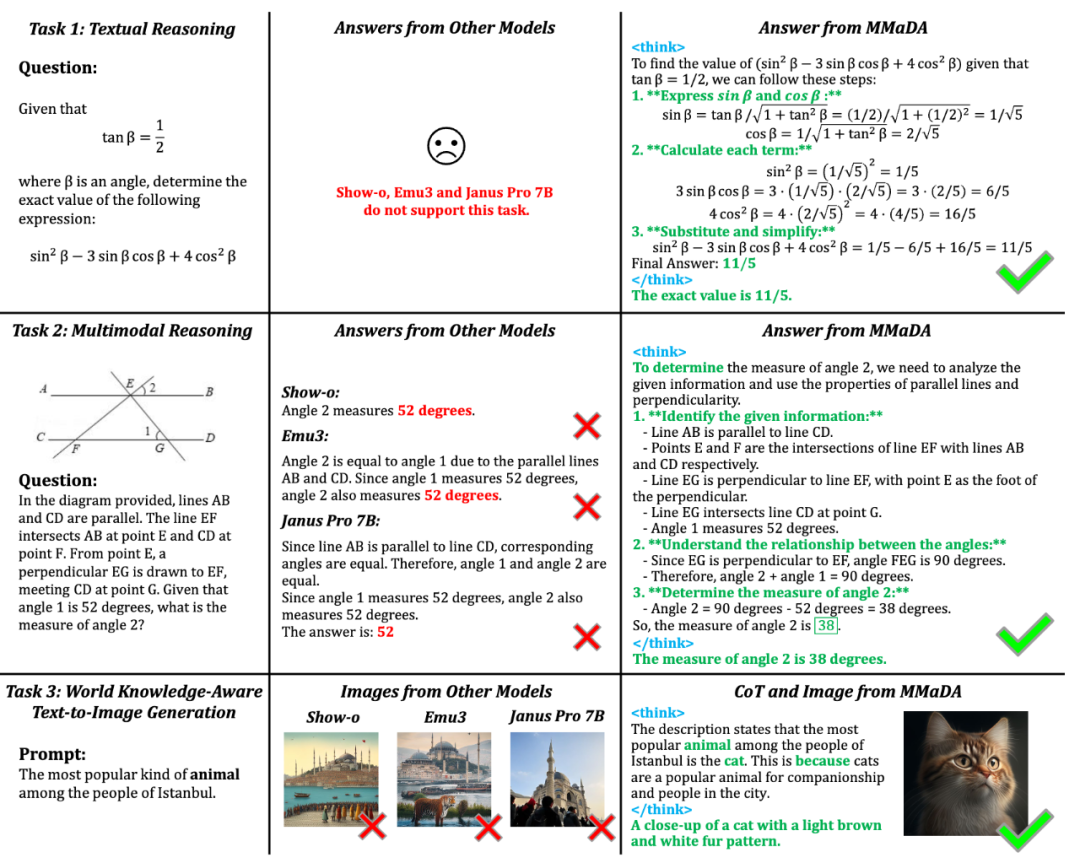
MMaDA 在三大任务中实现 SOTA 性能:
-
文本推理:MMLU 准确率 68.4%,超越 LLaMA-3-8B、Qwen2-7B、LLaDA-8B;目前所有的统一理解与生成模型都不支持文本的强推理,MMaDA 首次在多模态任务中保持了文本的建模能力,实现真正意义上的统一基座模型。
-
多模态理解:在 POPE(86.1 vs 85.9)、VQAv2(76.7 vs 78.5)等基准上与 LLaVA、Qwen-VL 等专用模型持平;
-
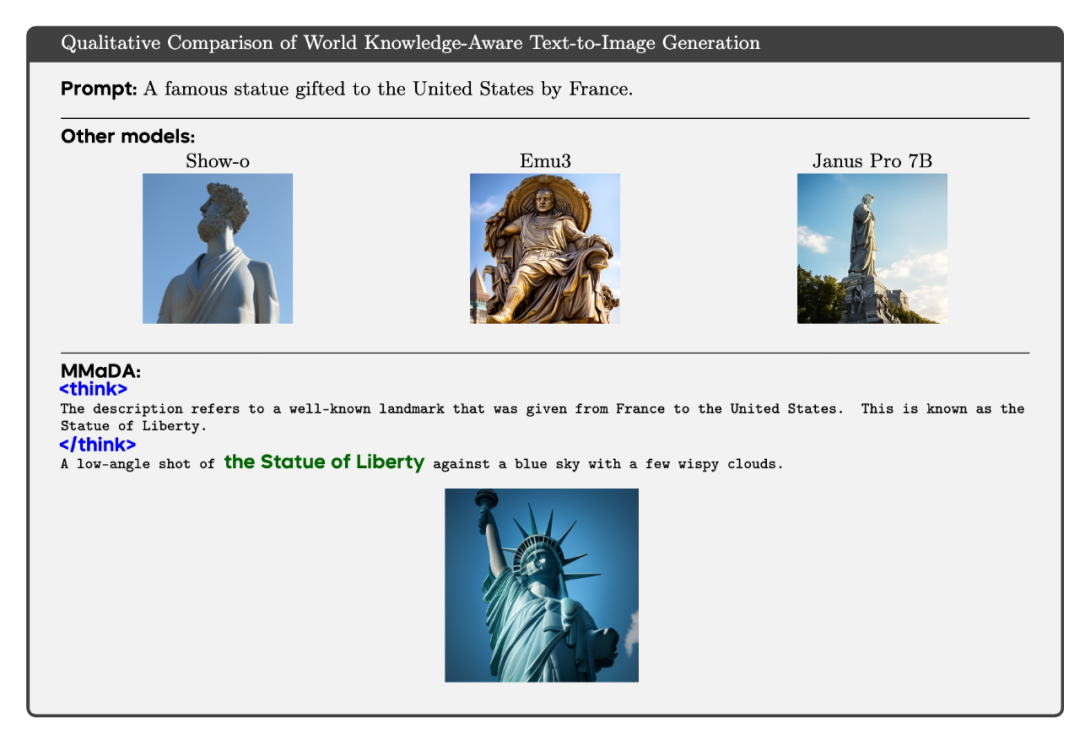
图像生成:CLIP Score 达 32.46,较 SDXL、Janus 等模型提升显著,在文化知识生成任务(WISE)中准确率提升 56%。图像生成任务里,首次对比了统一多模态大模型在含有世界知识(World Knowledge)的文生图任务上的表现,如下图所示:
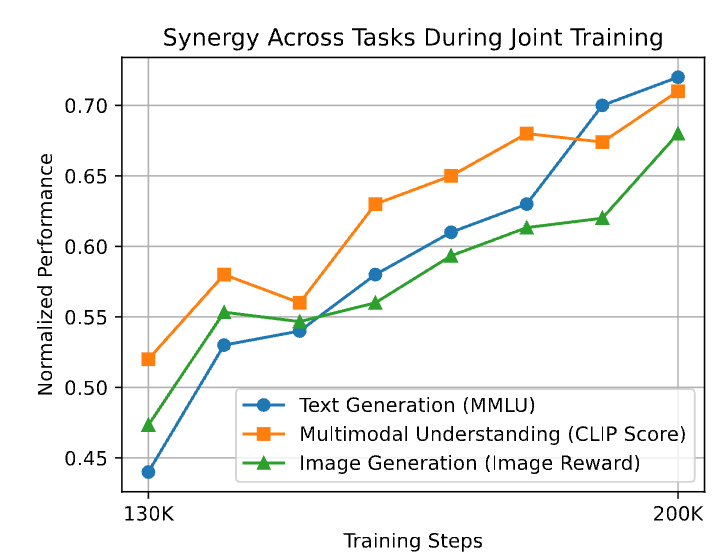
跨任务协同效应
如下图所示,在混合训练阶段(130K-200K 步),文本推理与图像生成指标同步上升。例如,模型在解决复杂几何问题和生成图像的语义准确性上显著提高,证明了以扩散模型作为统一架构的多任务协同效应。
任务泛化
扩散模型的一个显著优势在于其无需额外微调即可泛化到补全(Inpainting)与外推(Extrapolation)任务上。MMaDA 支持三类跨模态的补全任务:
-
文本补全:预测文本序列中的缺失片段。 -
视觉问答补全:基于不完整图文输入生成完整答案。
-
图像补全:根据局部视觉提示重建完整图像。

关键技术解析
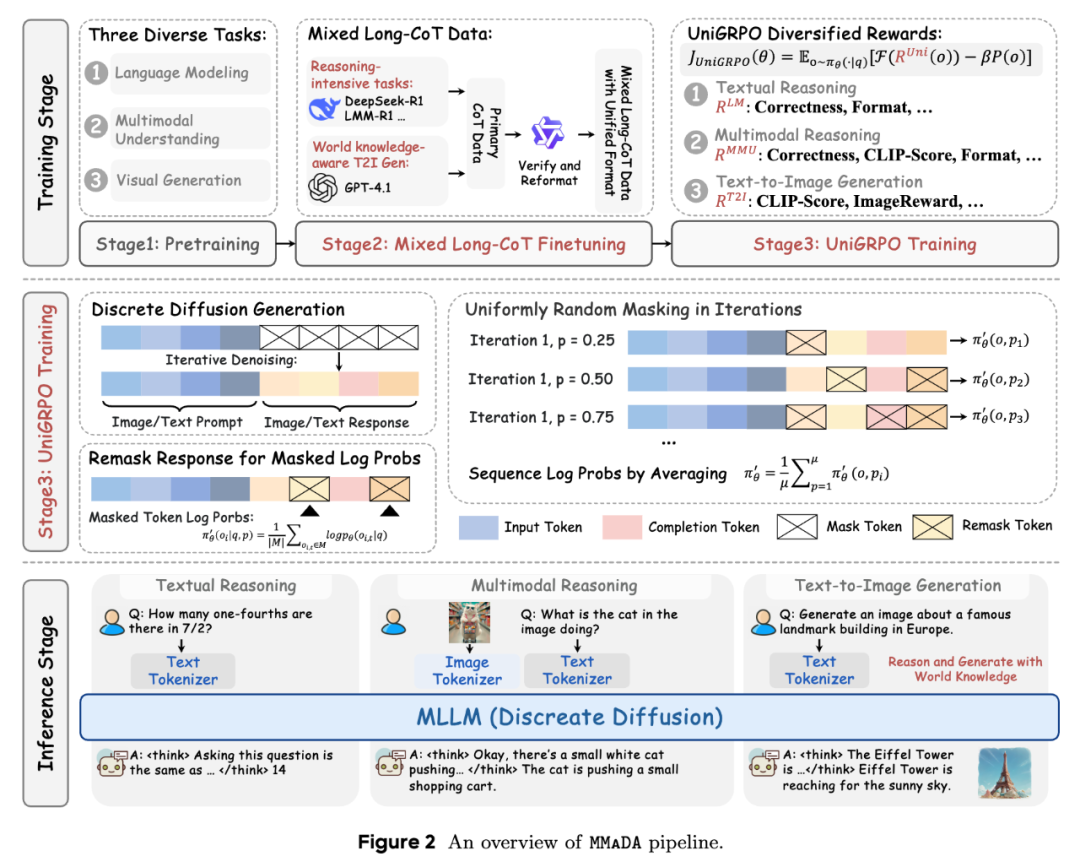
训练与测试框架如下:
-
统一扩散架构(Unified Diffusion Architecture)
-
数据表征:文本使用 LLaMA 的 Tokenizer,图像采用 MAGVIT-v2 的 Tokenizer,将 512×512 图像转化为 1024 个离散 Token; -
扩散目标:定义统一掩码预测损失函数,通过随机掩码同步优化文本与图像的语义恢复能力。例如,在预训练阶段,模型需根据部分掩码的 Token 序列预测缺失内容,无论输入是文本段落还是图像块。
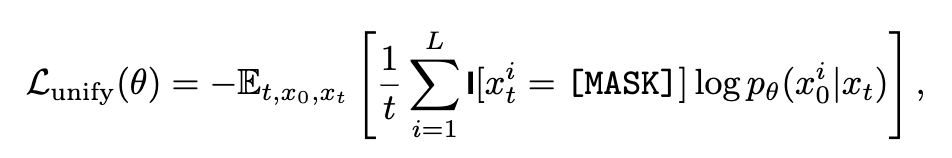
这种设计消除了传统混合架构(如 AR+Diffusion)的复杂性,使模型在底层实现跨模态信息交互。
-
混合长链思维微调(Mixed Long-CoT Finetuning)
-
统一推理格式:定义特殊标记结构 <think>推理过程</think>,强制模型在生成答案前输出跨模态推理步骤。例如,在处理几何问题时,模型需先解析图形关系,再进行数值计算; -
数据增强:利用 LLM/VLM 生成高质量推理轨迹,并通过验证器筛选逻辑严谨的样本。文本数学推理能力的提升可直接改善图像生成的事实一致性(如正确生成「北极最大陆生食肉动物——北极熊」)。
-
统一策略梯度优化(UniGRPO 算法)
-
结构化噪声策略:对答案部分随机采样掩码比例(如 30%-70%),保留问题部分完整。这种设计模拟多步去噪过程,避免之前方法(如 d1)的全掩码导致的单步预测偏差;
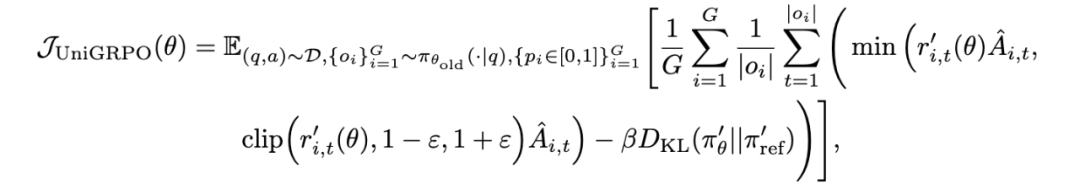
-
多样化奖励建模:针对不同任务设计复合奖励函数。例如在图像生成中,CLIP Reward 衡量图文对齐度,Image Reward 反映人类审美偏好,二者以 0.1 系数加权融合。

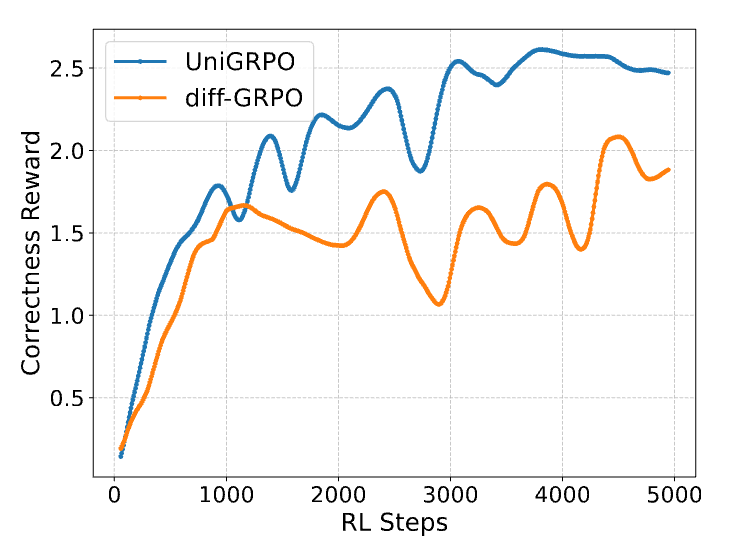
如下图所示,UniGRPO 在 GSM8K 训练中使奖励值稳定上升,相较基线方法收敛速度提升 40%。这得益于 UniGRPO 对扩散模型多步生成特性的充分适配。
主要作者介绍

©
(文:机器之心)