

今天是2025年5月23日,星期五,北京,阴。
先来看看文档智能相关进展,在及技术路线上,也有一些新的玩法。比如,Dolphin检测+解析双阶段多模态文档解析思路,效果实测并不理想,尤其是带图片的文档,公式解析和复杂表格解析一般、OCR幻觉比较严重。工作是方案上的借鉴意义,并没有从性能上更改当前试图通过小尺寸模型实现真正可用的ocr-free局面,还有很长的路要走。
这一类(Nougat、Kosmos-2.5、Vary、Fox、GOT、olmOCR、SmolDocling、Mistral-OCR)的一波接着一波,一茬又一茬,口号很响,但效果对应不上,真正落地,还是走集成方案(ppstructure这类) 好些,例如ppocr更新了5.0版本,传统方案更踏实。
顺着说第二件事,就是说下ppocr更新的5.0版本发生的变化,以及通过一个OCR-Reason的评测来看看多模态处理文档OCR任务的能力。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、Dolphin检测+解析双阶段多模态文档解析思路
最近的一个工作《Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting》,http://115.190.42.15:8888/dolphin/,https://arxiv.org/pdf/2505.14059,https://huggingface.co/ByteDance/Dolphin,https://github.com/bytedance/Dolphin,可以看看,通过两阶段方法来做文档解析问题。
1、两阶段解析流程
核心就是底下这个图:
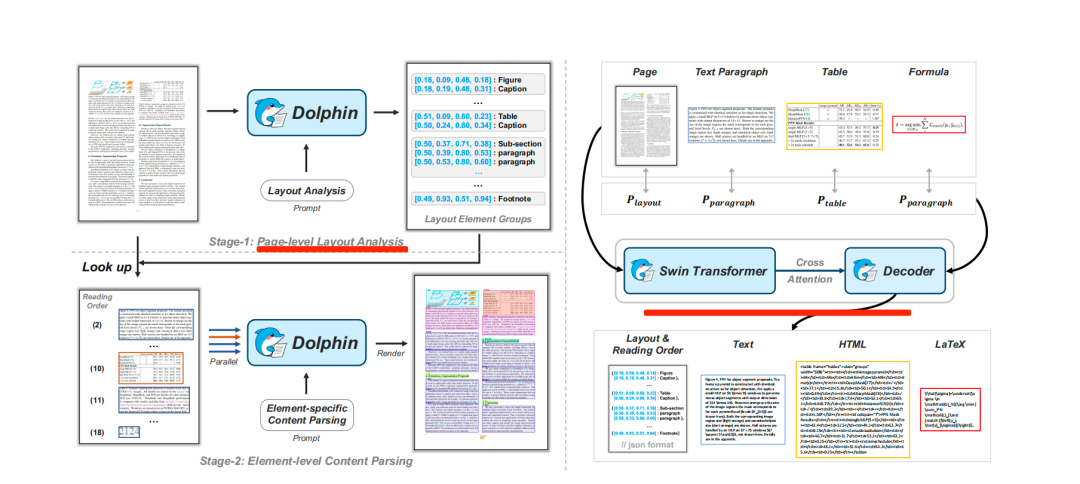
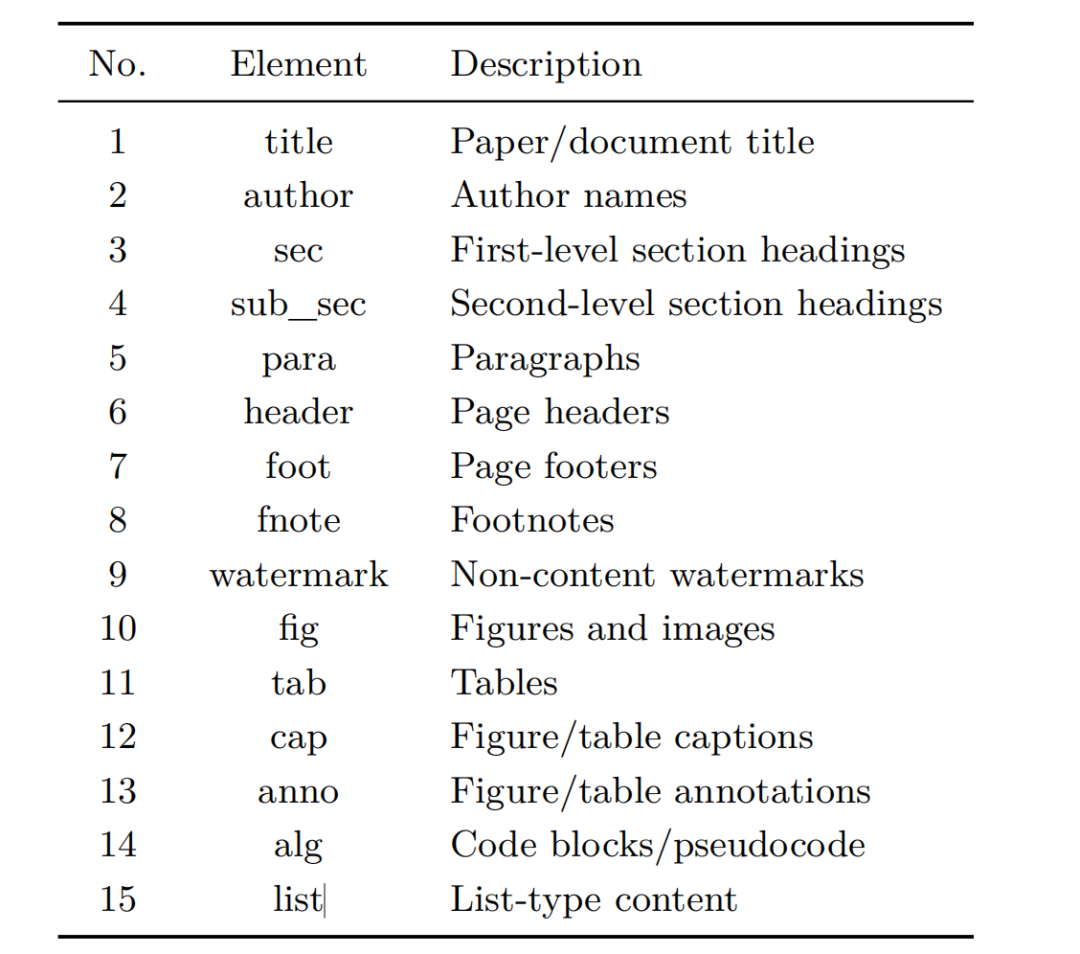
第一阶段通过生成阅读顺序的元素序列进行页面级布局分析,涉及15个标签,做的是目标检测和阅读顺序预测。
第二阶段使用异构锚点和特定于任务的提示对文档元素进行并行解析。这里所谓异构,就是复杂版式,各种类型的元素。所谓的锚点,就是每个区块的label和boudingbox,加载不同的prompt提示去解析。
2、任务提示
一共包括Page-level Layout Analysis、Text Paragraph/Formula Parsing、Table Parsing、Text Spotting、Text Box Query共5个任务,每个任务都对应一个prompt。
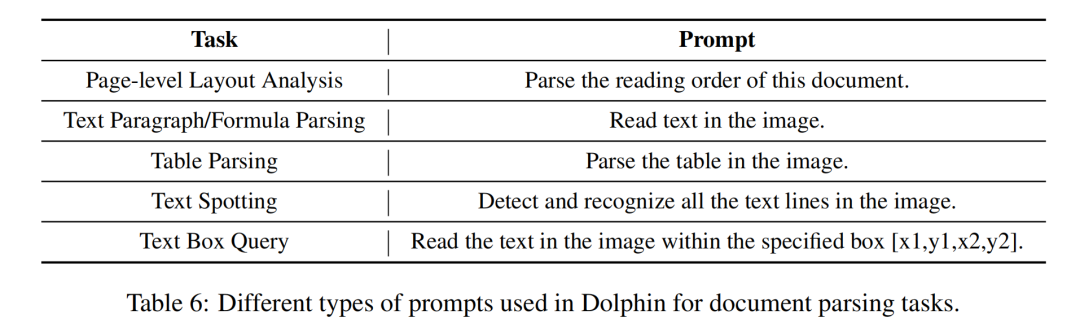
给的借鉴意义就是:提示还是要跟着具体的元素类型走,有的图片虽然是表格,但长得跟普通图片很类似,会混淆,加一下区分能力会好一些。
3、合成数据思路
核心的核心还是数据,主要还是靠数据合成,以及传统ocr方案去洗数据,尤其是第一个用来做layout任务的12W数据。可以借鉴的,就是怎么来搞数据,收集开源,html、github的转换以及基于传统ocr去蒸馏等思路。
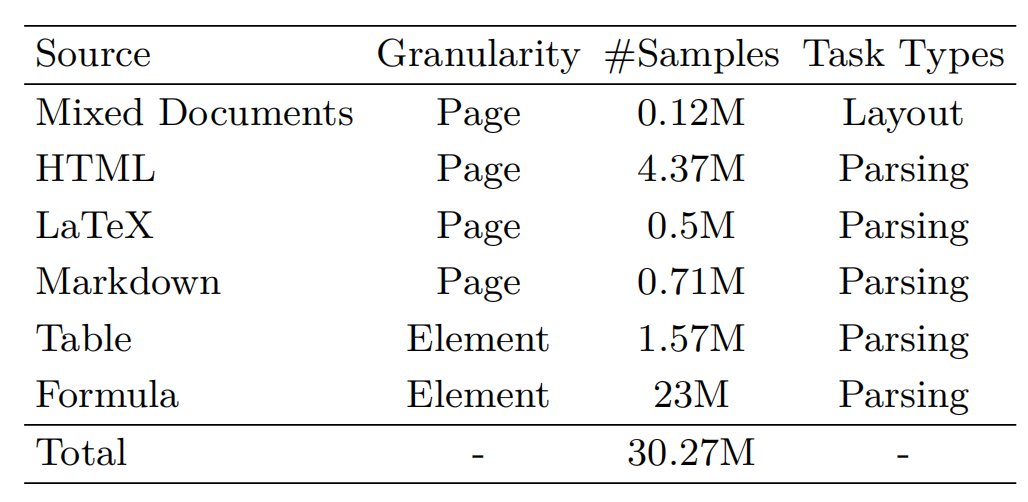
1)混合文档:收集了0.12M的文档,括教育材料(试卷和教科书)、出版物(杂志和报纸)以及商务文档(演示文稿和行业报告)。所有文档均标注了元素级边界及其阅读顺序,从而支持布局分析和顺序预测的训练
2)HTML:利用中文和英文维基百科文章的转储生成合成训练数据,通过网页渲染生成4.37M的页面级样本,处理HTML内容时,为字符级标注添加span标签,并应用随机字体选择以增强视觉多样性。
3)LaTeX:从arXiv数据库收集了0.5M的文档,使用LaTeX Rainbow框架进行渲染(可以保留文档层次结构的),用不同的颜色渲染不同的元素(例如,公式、图表)。然后,自动解析渲染后的文档,以提取元素类型、层次关系以及在块、行和字级别的空间位置。
4)Markdown:从GitHub页面收集了0.71M的Markdown文档,通过Pandoc进行PDF渲染,通过基于PyMuPDF的解析,以及与源Markdown的内容对齐,获得段落、行和单词级别的层次化文本标注,以及一些特定元素类型如表格。此外,以不同颜色渲染公式,并基于像素匹配找到所有公式块。
5)表格:使用PubTabNet和PubTab1M两个大规模表格数据集,分别包含568K和1M的表格;PubTabNet包含带有HTML标注的表格,PubTab1M提供了带有更细粒度结构标注的表格。
6)公式:从arXiv源收集了23M的LaTeX格式公式表达式,使用XeTeX工具渲染成公式图像,并且然后在渲染过程中,采用多种背景和字体进行增强
4、模型大小及结构
在模型架构见:https://huggingface.co/ByteDance/Dolphin/blob/main/config.json,https://huggingface.co/naver-clova-ix/donut-base/blob/main/config.json,整体模型参数大小为322MB,两个阶段参数共享。
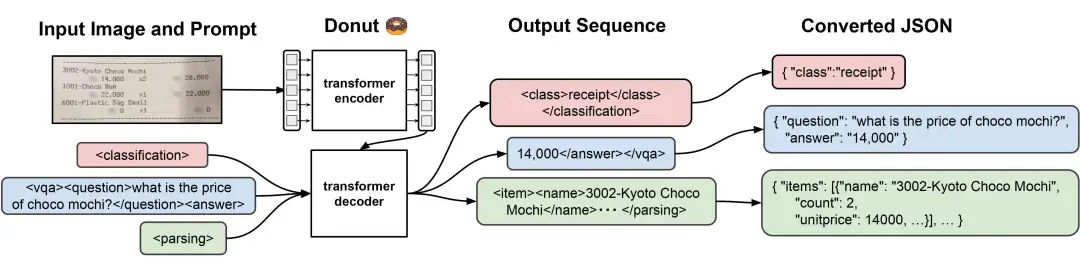
模型基于Donut的预训练权重初始化后再微调,encoder(swintransformer/vit)+decoder(mbart),词表大小是73921。
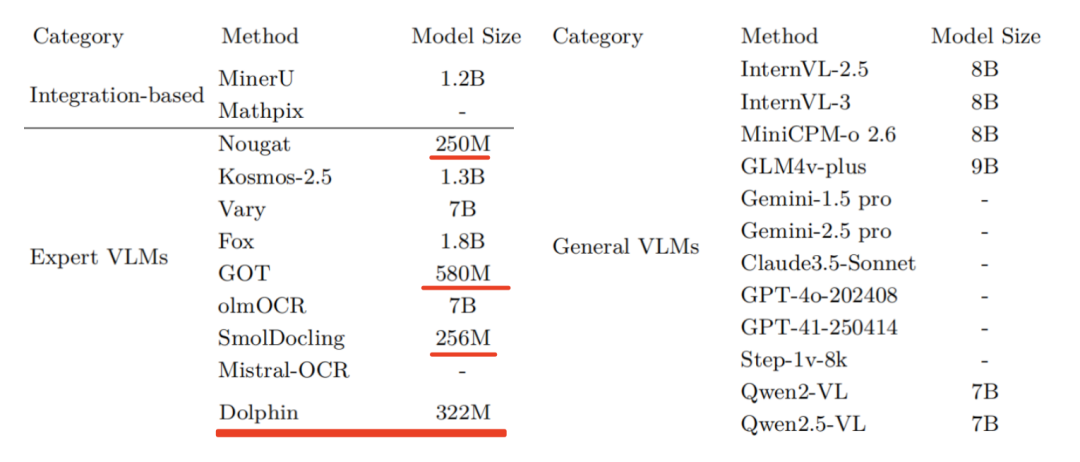
其中,swintransformer有多个版本,包括Swin-T (Tiny) 29M;Swin-S (Small)50M,Swin-B (Base)88M,Swin-L (Large)197M,把这块做小是有很多选择空间的,关键还是要看最终效果,盲目做小不是方法。

这里再回顾下多模态大模型,走的是自回归文档解析方案。
一般都是两类,一类是通用,一类是垂直领域。
通用的包括:InternVL-2.5、InternVL-3、MiniCPM-o 2.6、 GLM4v-plus、Gemini-1.5 pro、Gemini-2.5 pro、Claude3.5-Sonnet、GPT-4o-202408、GPT-41-250414、 Step-1v-8k、Qwen2-VL、Qwen2.5-VL,这些模型得益于大规模多样视觉数据的预训练,依赖的是zero-shot能力;
垂直的包括:Nougat、Kosmos-2.5、Vary、Fox、GOT、olmOCR、SmolDocling、Mistral-OCR,依赖的还是训练数据的设计以及一些处理策略。
这类方案的优化目标,大多为通过预测token分布与真实值分布之间的交叉熵损失进行优化。
5、实际测试效果
最后,实际测试了下,说下效果,公式解析和复杂表格解析一般、OCR幻觉比较严重。工作是方案上的意义,并没有从性能上更改局面。
正如论文中的表述,Dolphin主要支持标准水平文本布局的文档,在解析如古籍等垂直文本时能力有限。
归其根本,一个是受限及模型的大小,对文档图像的建模能力并不够,无论是swin-transformer还是mbart,两者的建模能力都有限,把参数量做小,是需要付出性能代价的。
一个是训练数据方面的问题,具体的:
虽然数据很多,但多为合成,如其中的表格数据,多为论文英文表格,对其他中文表现受限;
解析合成数据多为html、markdown数据,对于垂直、完全等场景文本处理效果并不好。
此外,文档类大模型的幻觉问题依旧还是没有解决。这种两阶段的工作,存在级联误差传播。第一阶段的版式检测不准确的话,会直接导致后续结果出错,尤其是带图片的文档图片进行解析,直接出不来东西。
所以,其意义在于,提出了两阶段来解决文档解析问题,但考虑的并不全面,以及传统集成式方案与多模态方案进行融合的趋势,就如SmolDocling,地址在https://huggingface.co/ds4sd/SmolDocling-256M-preview一样,
此外,具体的解读,也可以参考使用deepwiki创建Dolphin的wiki,https://deepwiki.com/bytedance/Dolphin,也暴漏出一个问题,deepwiki有明显的幻觉问题。
二、多模态文档OCR推理测试及PP-OCRv5更新
1、文档OCR接入推理的一个评估例子
文档OCR处理有个方向,就是结合推理做工作,例如《Reasoning-OCR: Can Large Multimodal Models Solve Complex Logical Reasoning Problems from OCR Cues?》(https://github.com/SCUT-DLVCLab/OCR-Reasoning,https://arxiv.org/pdf/2505.12766),标注了一个包含1069个人工注释示例,工作量体现在人工标注上。
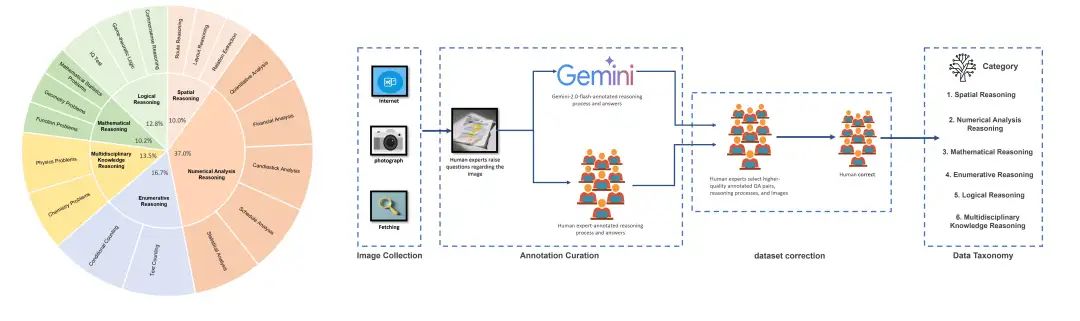
涵盖六个推理任务,空间推理、数值分析推理、数学推理、枚举推理、逻辑推理和多学科知识推理。

核心结论有两点。图像中的视觉信息对于OCR推理任务很重要。用 OCR结果替换图像并将其输入到LLM中时,准确率相对较低,仅靠文本不足以解决富含文本的图像推理任务。
此外,现有模型在OCR 推理任务中仍有改进空间,还没有一个模型在这个OCR推理任务中达到超过50%的准确率。
2、PP-OCRv5更新
PP-OCRv5更新(https://paddlepaddle.github.io/PaddleOCR/main/version3.x/algorithm/PP-OCRv5/PP-OCRv5.html)。根据所述,在场景方面,PP-OCRv5升级了中英复杂手写体、竖排文本、生僻字等多种挑战性场景的识别能力。
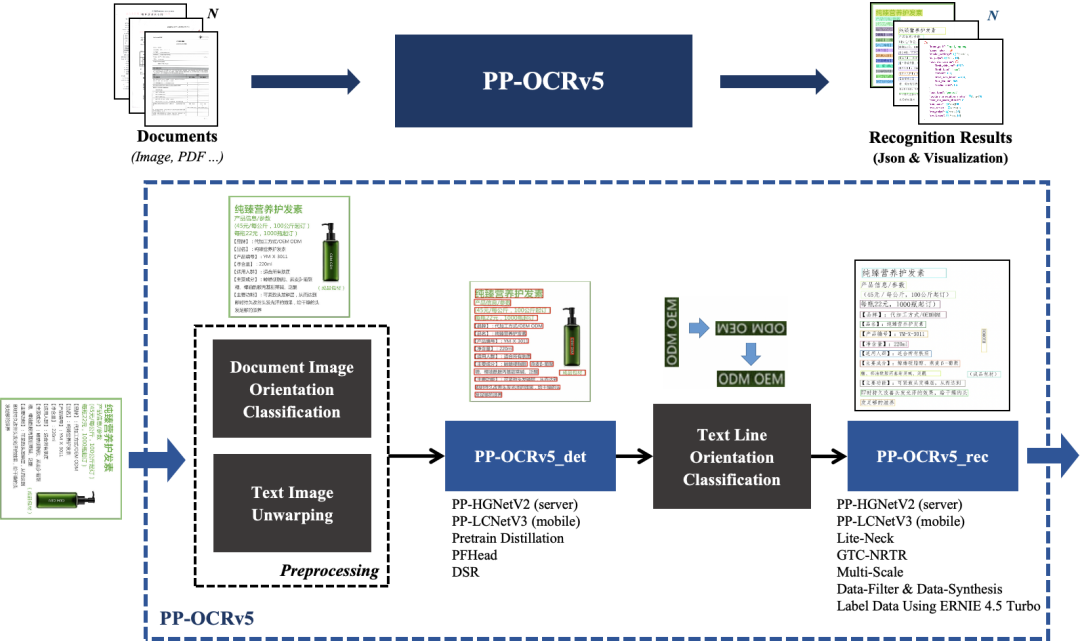
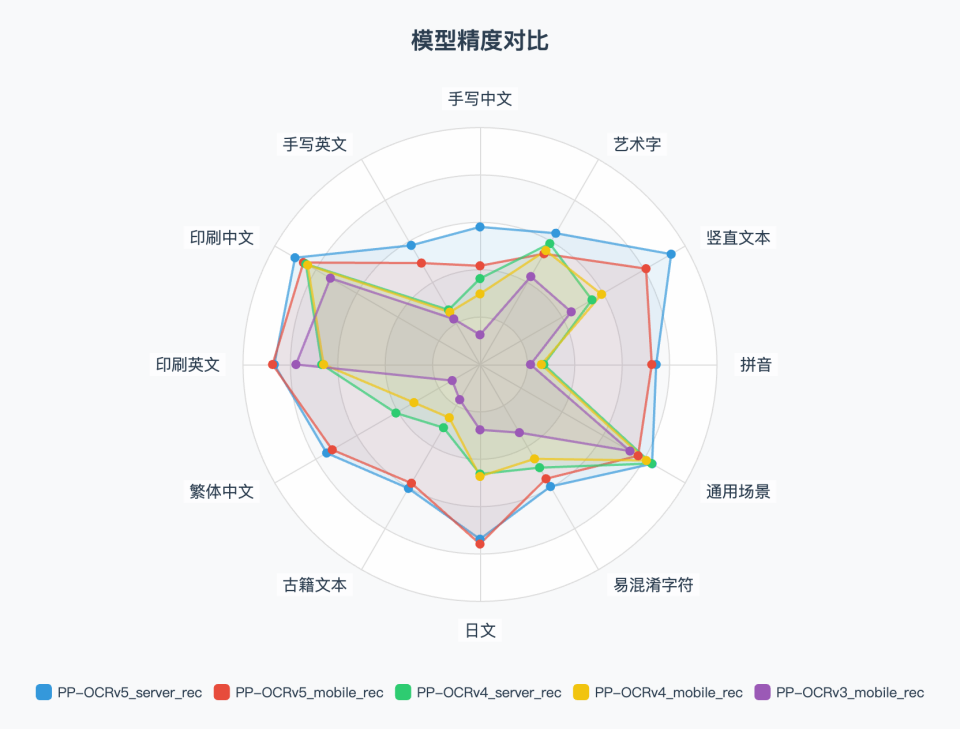
在内部多场景复杂评估集上,PP-OCRv5较PP-OCRv4端到端提升13个百分点。但是,实际表现还得用户自己测试,可以试试看。
参考文献
1、https://github.com/microsoft/magentic-ui
2、https://paddlepaddle.github.io/PaddleOCR/main/version3.x/algorithm/PP-OCRv5/PP-OCRv5.html
3、https://github.com/SCUT-DLVCLab/OCR-Reasoning
(文:老刘说NLP)