
提升效果

“煽风点火”让大模型“卷”起来的提升性能的套路

近日,一名网友分享了一种通过巧妙利用不同AI模型之间的‘竞争’心理来提升AI输出效果的方法,具体步骤包括:选择任务→交给第一个AI(如ChatGPT)→将结果复制粘贴给第二个AI(如Claude),并要求其改进表现→再继续挑战第三个AI(如Grok)。这种方法已经得到了很多网友的验证和认可。
Qwen开源首个长文本新模型,百万Tokens处理性能超GPT-4o-mini

阿里云Qwen模型首次将上下文扩展至1M长度,实现了长文本任务的稳定超越GPT-4o-mini,并提升了推理速度7倍。该模型分为长上下文训练、长度外推和稀疏注意力机制三大步骤。
Promptimal:AI提示优化工具,通过遗传算法快速改进你的AI提示词
Promptimal:通过遗传算法改进AI提示词,无需数据集提升效果(参考文献:[1] http://github.com/shobrook/promptimal)
大模型微调样本构造的trick
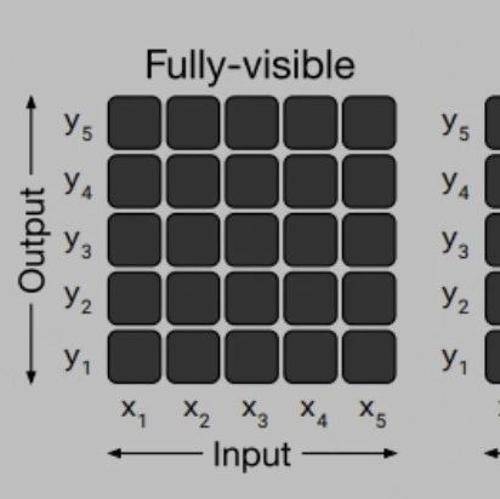
通过全参数微调实现ChatGLM2-6B模型的优化,重点在于多轮对话训练样本组织方式改进。采用session级别训练,避免了数据重复膨胀和低效问题,提高了训练效果,并实现了与原版相比有显著提升。