


论文标题:
From Rankings to Insights: Evaluation Should Shift Focus from Leaderboard to Feedback
论文地址:
https://arxiv.org/abs/2505.06698
项目主页:
https://liudan193.github.io/Feedbacker/
代码地址:
https://github.com/liudan193/Feedbacker

研究背景
随着大模型能力的快速演进,现有评估范式正面临深刻挑战:
在 LLM 评估的第一阶段,基于人类评判的排行榜(如 Chatbot Arena)依赖大量人工标注实现模型排序,尽管直观但成本高昂,且难以及时反馈。
进入第二阶段,自动评估基准(如 MT-Bench、Arena-Hard)虽提升了评估效率,但却陷入了「模拟人类排名」的误区,仅提供总分排名,无法揭示模型的具体优势与缺陷。
第二阶段的这种「黑箱式评估」带来了两大核心问题:
-
评估片面性:过度关注主流任务,以拟合人类排名为导向,忽视了真实应用场景的复杂性。
-
反馈缺失:仅提供粗粒度的总分,掩盖了模型在具体任务场景中的差异化表现,无法为模型优化提供明确的改进方向,沦为纯粹的“数字游戏”。

动机 / 切入点
本文首次提出评估范式的范式转移:
评估目标应从「排名竞争」转向「诊断反馈」
基于这一洞见,团队开发了 Feedbacker 框架,并引入三大创新组件:
1. 树状能力图谱:突破传统 embedding 聚类的分类方法,充分利用先进的推理模型(reasoning model),实现更加合理的自动分类构建。最终形成覆盖写作、角色扮演等六大领域的可扩展分类体系。
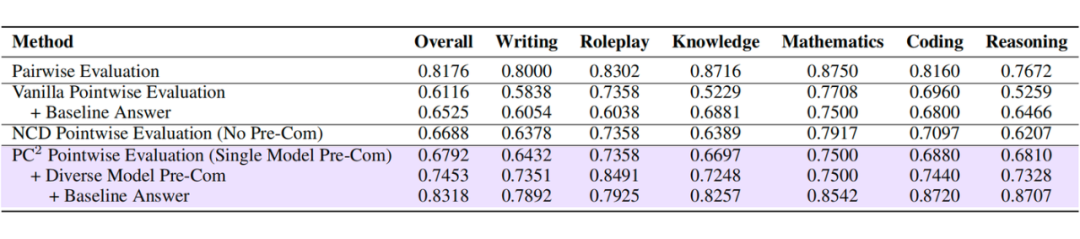
2. 动态评估标准:通过 PC² 点评估法(Pre-Comparison Criteria)生成场景化评判准则,确保评估标准动态调整,令 pointwise evaluation 的准确性媲美 pairwise evaluation。
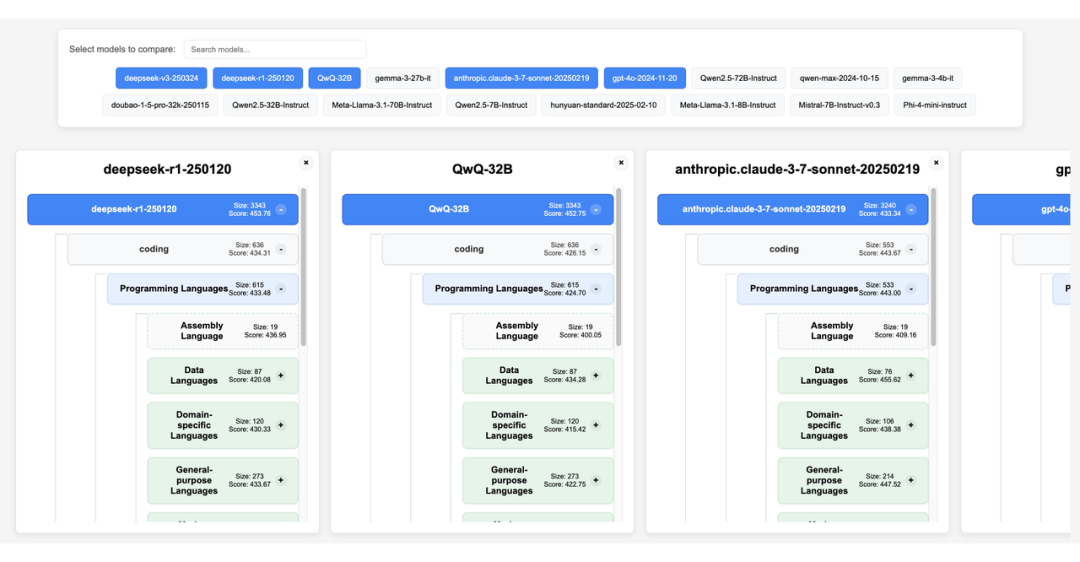
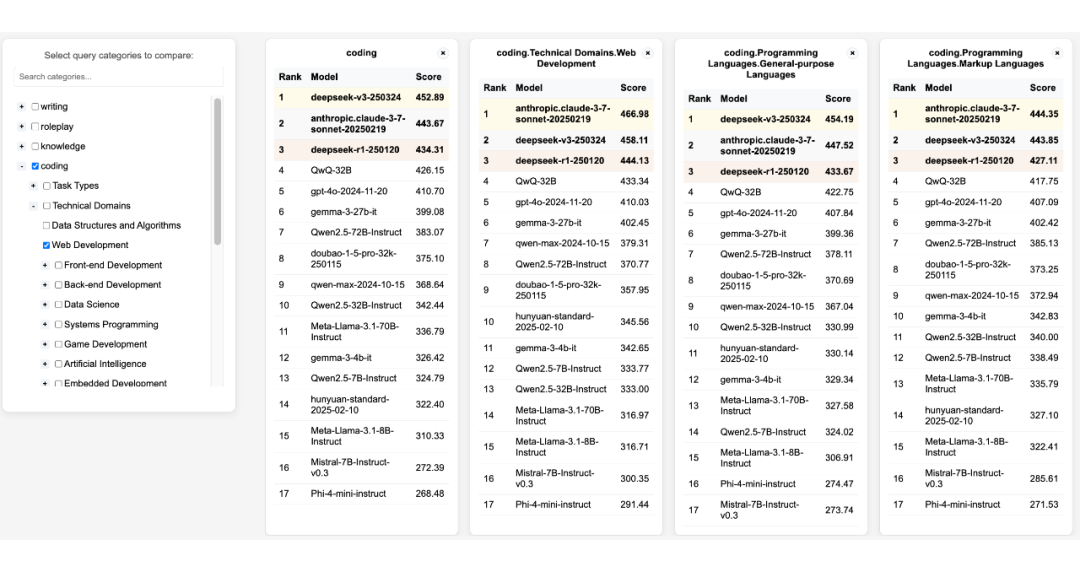
3. 可视化分析:提供多样化的可视化工具和自动分析器,帮助快速识别模型的薄弱环节,支持针对性优化。
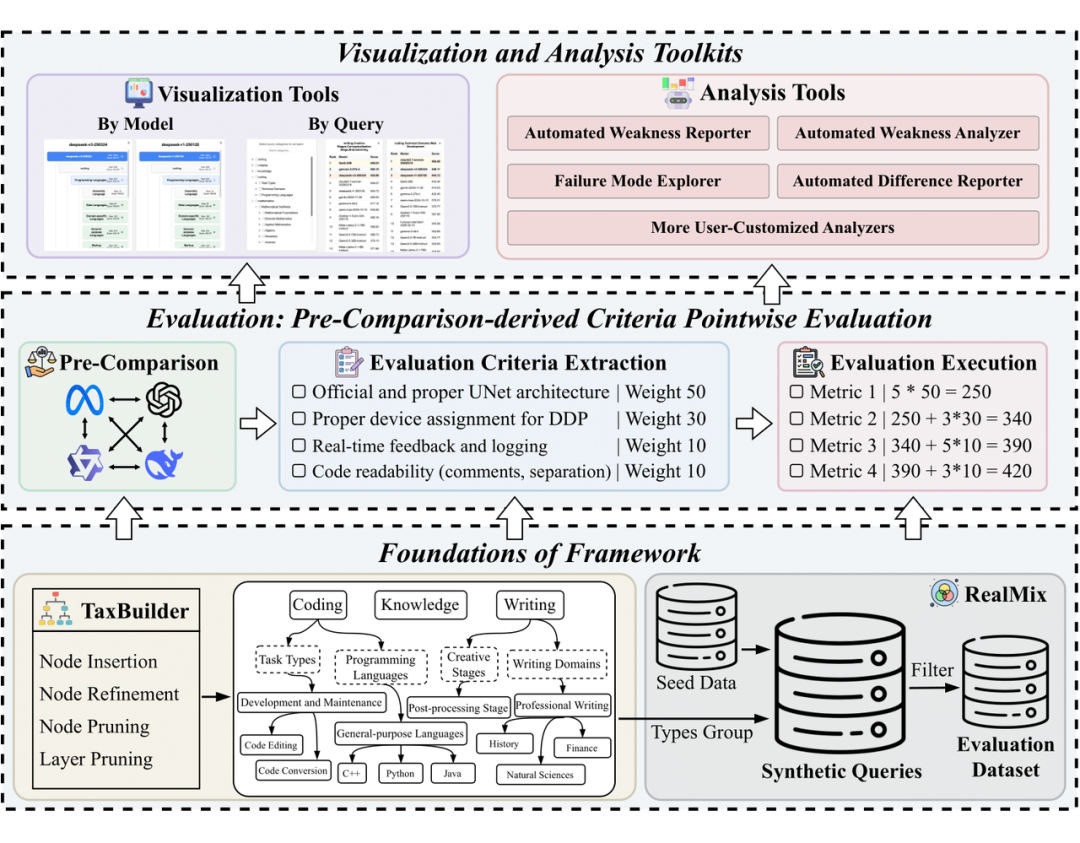

方法
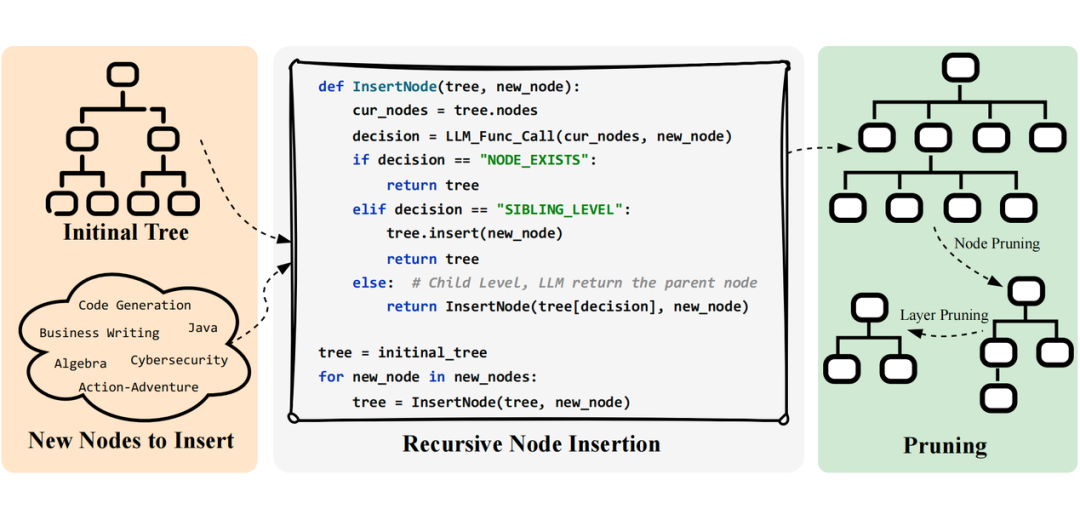
3.1 用户查询图谱构建(TaxBuilder)
-
递归插入机制:模拟树结构构建过程,通过层级决策和 reasoning model,实现动态扩展分类节点,灵活应对复杂任务类别。
-
自动优化策略:集成节点剪枝和层级压缩技术,在保持分类体系覆盖度的同时有效控制复杂度,确保结构简明而精准。
3.2 评估范式革新(PC²点评估法)
-
标准预提取:通过预比较多种模型响应,自动生成带权重的评估指标,确保评估标准动态适配任务场景。
-
动态权重分配:自动聚焦关键指标,在保证 pointwise evaluation 线性时间复杂度的前提下,实现与 pairwise evaluation 相媲美的评估精度。
3.3 诊断工具链
-
可视化交互工具:提供人性化界面,便于用户直观探索和理解模型表现。
-
自动分析工具:支持快速定位并分析模型的优势与薄弱环节,为模型的理解和优化提供快速查阅。

意义与展望
1. 评估范式转变:Feedbacker 率先实现从「分数驱动」到「反馈驱动」的评估范式转变,为模型优化提供精准导航。研究团队已开源评估框架与数据集,推动构建更科学的 LLM 评估生态。
2. 评估方法升级:借助预对比策略,PC²-pointwise evaluation 在保持线性时间复杂度的同时,达到了与 pairwise evaluation 相媲美的精度。这一方法对自我进化(self-evolve)和偏好数据构造等方向具有深远影响。
3. 数据合成规范化:TaxBuilder 充分发挥 reasoning model 的能力,实现自动分类法构建,不仅提升分类体系的合理性,还为数据合成提供了结构化指导。
(文:PaperWeekly)