


自 OpenAI 发布 Sora 以来,视频生成领域迎来爆发式增长,AI 赋能内容创作的时代已然来临。
去年 4 月,生数科技联合清华大学基于团队提出的首个扩散 Transformer 融合架构 U-ViT,发布了首个国产全自研视频大模型 Vidu,打破国外技术垄断,支持一键生成 16 秒高清视频。
近期,腾讯混元、阿里通义万相等开源视频生成模型相继亮相,可生成 5-6 秒视频,进一步降低了视频创作门槛。
然而,尽管技术进步显著,海内外社区仍有不少用户抱怨现有开源模型受限于生成 5-6 秒的短视频,时长不够用。
▲ 图1

RIFLEx:一行代码,解锁长视频生成的无限可能
今天,清华朱军团队带来了一个简洁优雅的解决方案——RIFLEx。新方案仅需一行代码、无需额外训练即可突破视频生成模型现有长度限制,打破“短视频魔咒”。

▲ 图2
RIFLEx 适用于基于 RoPE 的各类Video Diffusion Trasnsformer,例如 CogvideoX、混元以及最新发布的通义万相。
下列为开源模型无需任何训练直接时长外推两倍至 10s 效果:
⦁ 大幅度运动
▲ 图3-1. prompt:一只棕白相间的动画豪猪好奇地审视着缎带装饰的绿色盒子,灵动的眼神与细腻的 3D 动画风格营造出温馨而精致的视觉体验
⦁ 多人物复杂场景
▲ 图3-2. prompt:荒凉空地上的简易营地散布着无人机与物资,军人与平民共处,一名男子绝望抱头,女子忧虑注视,沉重氛围暗示刚经历重大事件,镜头稳定细腻,突出紧张与不安感。
⦁ 自然动态流畅
▲ 图3-3. sora 的经典长毛猛犸象 prompt
在短视频微调几千步可进一步提升性能。
⦁ 多转场时序一致性保持
▲ 图4-1. prompt:蓬乱头发、穿棕色夹克系红色领巾的男子在马车内严肃端详硬币,与女子交谈,广角与中近景结合展现历史剧风格与戏剧氛围。
⦁ 3D 动画风格
▲ 图4-2. prompt:动画中的兔子和老鼠,身穿探险装备正处于险境之中。它们急速坠入一个黑暗而未知的空间,紧接着便漂浮并游动在宁静的水下世界里。紧张而坚定的表情通过中景与特写展现,高质量 3D 动画风格增强电影感与沉浸感。
⦁ 真实人物特写
▲ 图4-3. prompt:留着胡须、穿格子衬衫的男子坐着弹奏原声吉他,沉浸于激情演唱。他所在的室内环境简洁,背景是一面纯灰色墙壁,左侧放置着一个吉他音箱和麦克风架,右侧摆放着一叠书籍。
除此之外,RIFLEX 不仅支持视频的时间维度外推,还可扩展至空间维度外推,以及可同时进行的时空外推。
⦁ 图像宽度外推两倍:

▲ 图5-1. 左图为训练尺寸,右图为外推结果
⦁ 图像高度外推两倍:

▲ 图5-2. 左图为训练尺寸,右图为外推结果
⦁ 图像高宽同时外推两倍:

▲ 图5-3. 左图为训练尺寸,右图为外推结果
⦁ 视频时空同时外推两倍:
▲ 图5-4. 训练尺寸:480*720*49
▲ 图5-5. 外推结果:960*1440*97
该研究成果一经发布,便获得广泛关注。推特知名 AI 博主 Ak 第一时间转发,海外科技公司和博主称赞其为“视频扩散模型领域的突破性创新”。
▲ 图6
Diffusers 核心贡献者 sayakpaul 和 a-r-r-o-w 也迅速收藏代码并留言表示赞叹。
▲ 图7
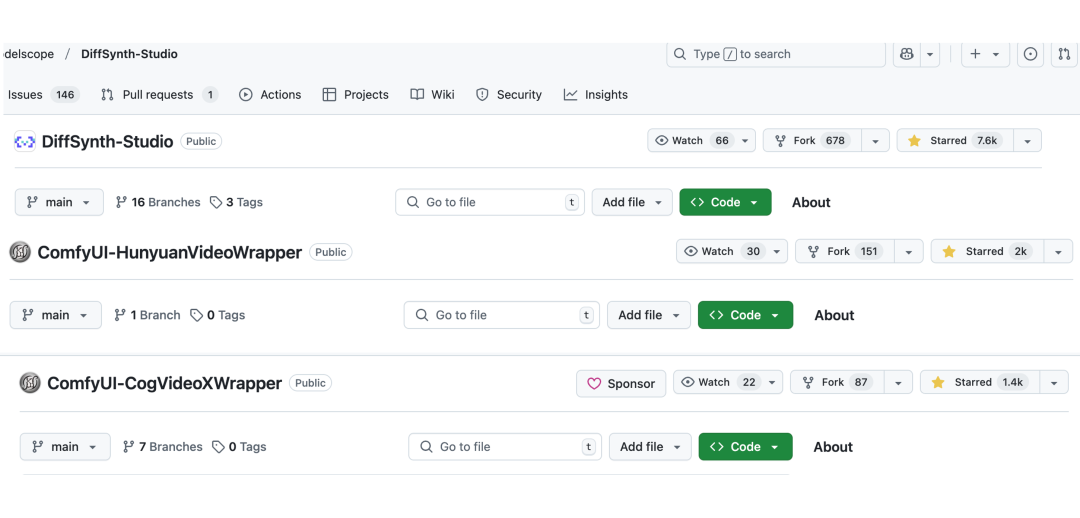
目前 RIFLEx 已被社区用户集成到各类知名视频生成仓库:
▲ 图8

揭秘 RIFLEx:化繁为简,直击本质
长度外推问题在大型语言模型中早有研究,但这些方法在视频生成中却屡屡碰壁,导致时序内容重复或慢动作效果。
▲ 图9-1. 直接外推导致视频内容重复,红色框表示开始和视频开头重复
▲ 图9-2. Position Interpolation 导致慢动作效果
为破解这一难题,团队深入挖掘 RoPE 的频率成分,揭示了其每个频率成分在视频生成的作用:
1. 时间依赖距离:不同频率成分只能捕捉特定周期长度的帧间依赖关系。当帧数超过周期长度时,周期的性质导致位置编码重复,从而使视频内容也会出现重复。
2. 运动速度:不同频率成分捕捉不同的运动速度,由该频率的位置编码变化率决定。高频成分捕捉快速运动,低频成分捕捉慢速运动。

▲ 图10
当所有频率成分结合时,存在一个“内在频率”,即周期距离首次观测重复帧最近的成分,它决定了视频外推时的重复模式。
基于此,团队提出 RIFLEX:通过降低内在频率,确保外推后的视频长度在一个周期内,从而避免内容重复。该方法仅需在经典 RoPE 编码中加入一行代码即可实现。
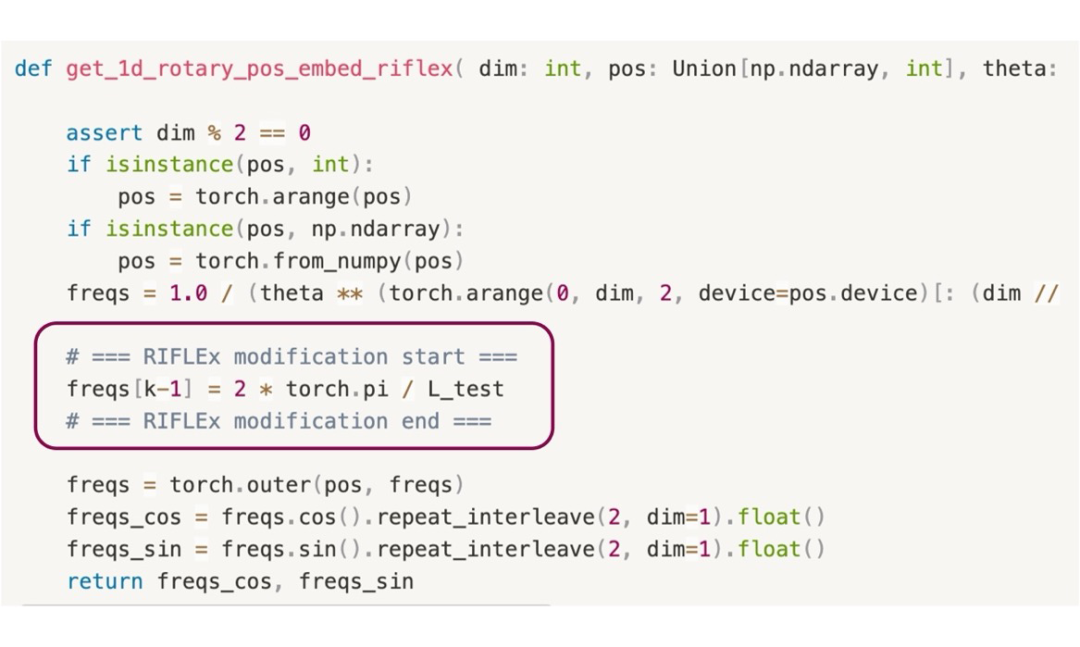
▲ 图11
这一方案为视频生成领域提供了新的思路,有望推动长视频生成技术的进一步发展。
Project page:
https://riflex-video.github.io/
Code:
https://github.com/thu-ml/RIFLEx

(文:PaperWeekly)