


今天凌晨,阿里巴巴开源了创新自主搜索AI Agent——WebAgent。
无论是学术研究、商业决策还是日常生活,搜索信息是我们从海量的网络中获取准确、有用的知识最佳途径之一。但传统的信息检索系统通常只能提供浅层次的搜索结果,难以满足复杂的用户需求。
而WebAgent具备端到端的自主信息检索与多步推理能力,就像人类一样在网络环境中主动感知、决策和行动,例如,当用户想了解某个特定领域的最新研究成果时,WebAgent能够主动搜索多个学术数据库,筛选出最相关的文献,并根据用户的需求进行深入分析和总结。
此外,WebAgent不仅能识别文献中的关键信息,还能通过多步推理将不同文献中的观点进行整合,最终为用户提供一份全面且精准的研究报告。

开源地址:https://github.com/Alibaba-NLP/WebAgent
WebDancer的框架一共由4大块组成,从数据构建到训练优化,逐步打造出能够自主完成复杂信息检索任务的智能体。
浏览数据构建是整个框架的起点。在现实世界中,高质量的训练数据是智能体能够有效学习和泛化的关键。WebDancer通过两种创新的数据合成方法来解决传统数据集的局限性。
第一种方法是CRAWLQA,它通过爬取网页信息来构建复杂的QA对。这一过程模拟了人类浏览网页的行为,从知名网站的根页面开始,递归地访问子页面,收集丰富的信息。
随后,利用强大模型对这些信息进行处理,生成具有深度和多样性的QA对。这些QA对不仅涵盖了多种问题类型,还通过多跳推理和复杂的目标分解,增加了任务的复杂性。
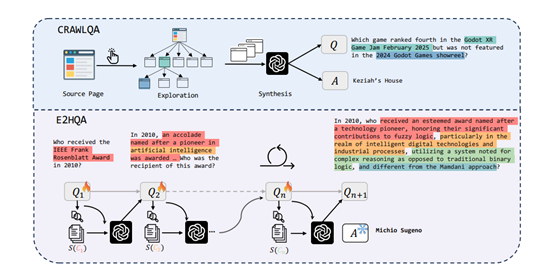
第二种方法是E2HQA,通过迭代增强的方式,将简单的QA对逐步转化为复杂的多步问题。这一过程从简单的事实性问题出发,通过逐步引入新的信息和子问题,最终构建出需要多步推理才能解决的复杂问题。这两种数据构建方法为WebDancer提供了丰富的训练素材,使其能够在多样化的任务中进行学习和优化。
接下来是轨迹采样阶段。在这个阶段,WebDancer基于ReAct框架,通过拒绝采样技术生成高质量的轨迹。ReAct框架的核心在于将推理与执行紧密结合,形成一个循环的交互过程。在这一过程中,智能体通过生成自由形式的思考内容和结构化的行动指令,与外部环境进行交互并接收反馈。
为了确保生成的轨迹既有效又连贯,WebDancer采用了短推理和长推理两种方法。短推理利用大模型直接生成简洁的推理路径,而长推理则通过推理模型逐步构建复杂的推理过程。
这两种策略生成的轨迹经过严格的过滤,以确保其质量和相关性。过滤过程包括有效性检查、正确性验证和质量评估三个阶段,确保最终保留的轨迹能够为智能体的学习提供高质量的指导。
在数据准备完成后,WebDancer进入监督微调(SFT)阶段。这一阶段的目标是通过高质量的轨迹数据对智能体进行初始化训练,使其能够适应信息检索任务的格式和环境要求。
在SFT过程中,WebDancer将轨迹中的思考、行动和观察内容分别标记,并计算损失函数,以优化模型的参数。为了提高模型的鲁棒性,WebDancer在计算损失时排除了外部反馈的影响,确保模型能够专注于自主决策过程。这一阶段的训练为智能体提供了强大的初始能力,使其能够在后续的强化学习阶段更好地适应复杂的任务环境。
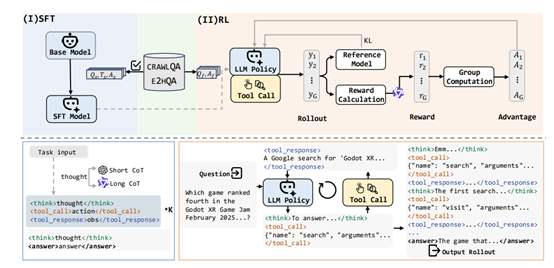
强化学习(RL)阶段是WebDancer框架的关键环节。在这一阶段,智能体通过与环境的交互,学习如何在复杂的任务中做出最优决策。WebDancer采用了DAPO算法,这是一种专门针对智能体训练设计的强化学习算法。
DAPO算法通过动态采样机制,有效利用未充分利用的QA对,提高数据效率和策略的鲁棒性。在RL过程中,智能体通过多次尝试和反馈,逐步优化其决策策略,最终实现高效的多步推理和信息检索能力。
(文:AIGC开放社区)