
编辑:杜伟
AI 开始从理解文字,全面进化到建模世界、操控实体、模拟大脑、解构分子。
一晃 2025 年已经快要过半了!AI 领域依然「热闹非凡」,令人目不暇接。
年初爆火的 DeepSeek R1 以及后续的 OpenAI o3,强化学习技术让推理模型能力强势增长;同时,智能体、世界模型、多模态大模型、具身智能与人形机器人、AI4S 等领域也不断产出引爆社区的成果,比如最初一码难求的智能体 Manus、CES 大会上英伟达的 Cosmos 世界基础模型。
前沿 AI 技术的进步让整个 AI 圈充满了活力,并推动各个 AI 方向在当前行业最有前景的道路上狂奔。
6 月 6 日,一年一度的国内「AI 内行顶级盛会」—— 第七届智源大会拉开了序幕!会上,Yoshua Bengio、Richard Sutton 等四位图灵奖得主、三十余位大模型企业创始人及 CEO、一百多位青年科学家及学者集思广益,从学界和产业界的多样化视角出发,围绕上面这些 AI 课题进行了头脑风暴,并针对下一代 AI 路径等行业前景问题贡献出了很多真知灼见。

作为主办方的智源研究院(简称智源),重磅亮相了全新一代「悟界」系列大模型。从命名来看,「悟界」代表了智源对于虚实边界的突破,通过深化对物理世界的赋能向着物理 AGI 方向迈进。这预示着这家人工智能领域的前沿科研机构对大模型的探索进入到了一个全新阶段。
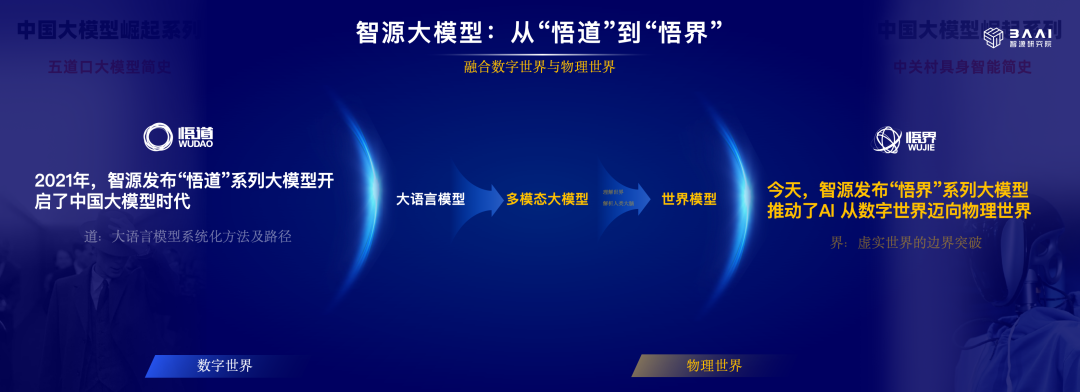
具体来讲,「悟界」系列包含了多项重要成果,它们分别是原生多模态世界模型 Emu3、脑科学多模态通用基础模型见微 Brainμ、跨本体具身大小脑协作框架 RoboOS 2.0 与具身大脑 RoboBrain 2.0以及全原子微观生命模型 OpenComplex2。其中原生多模态世界模型实现了真正的可扩展性,从一开始便在底层结构中融合进文本、图像、视频、声音甚至脑信号在内的各种模态,告别了简单的模态拼接。
不难发现,从 2021 年的悟道 1.0、2.0 到 2023 年的 3.0,智源引领并与行业主流发展趋势保持一致。此后,随着 Scaling Law 放缓等因素影响,拼参数的预训练语言大模型和视觉大模型不再是关注的唯一重心,两种显著的趋势开始开头:一是大模型架构朝着统一建模、底层融合的方向进化;二是 AI 研究加速与科学建模(如物理与生物规律、神经机制等)深度融合并演化成一种新范式。
智源全新「悟界」系列的出现,正当其时,反映了其对大模型发展现状和未来走向的合理研判与前瞻洞见。
这代表着:大模型开始从文图视频主导的数字世界进入到更加真实的物理世界,并且对物理世界的理解从宏观跨越到了微观尺度。

智源研究院院长王仲远。
原生多模态
让世界模型真正实现「一对多」
提到世界模型,它的提出与发展源自人工智能、认知科学领域对「理解世界」的基本追问。
2018 年,David Ha 和 Jürgen Schmidhuber 的里程碑式工作《World Models》发表,此后世界模型开始成为一个更具类脑启发性和统一框架意义的 AI 研究方向,尤其是与强化学习、多模态建模、机器人控制等领域的深度融合。
如今,世界模型已经成为 AI 领域的一个「必争之地」。从李飞飞世界模型首秀到英伟达、谷歌纷纷押注于此,再到国内的自研世界模型,这一 AI 方向的重要性愈加凸显,并成为实现通用智能、具身智能的关键基石。
从对行业的观察中发现,现有的世界模型多关注如何创建物理逼真、可交互并具备全局一致性的 3D 世界,落在了图像视频领域。「悟界」系列中的世界模型在关注图像视频之外,凭借其强大的底层架构将自身能力拓展到了与物理世界息息相关的应用场景。
此次,「悟界」系列中的 Emu3 是全球首个原生多模态世界模型,它以下一个 token 预测作为核心范式,打通了多模态学习的路径,摆脱了扩散模型或组合式架构的复杂性。

在执行过程中,Emu3 通过引入新型视觉 tokenizer,将图像与视频编码为与文本同构的离散符号序列,构建出了一个无需考虑模态的统一表征空间,最终让文本、图像、视频任意模态组合的理解与生成变为现实。此外,Emu3 还支持多模态输入与输出的端到端映射,验证了自回归框架在多模态领域的通用性与先进性,为更自然、更强大的跨模态交互提供了坚实的技术基础。
随着当前以及未来多模态数据在现实世界中日益丰富,Emu3 展示出的统一建模能力有望推动 AI 系统从「理解与生成单一模态」向「无缝协同多模态」的跃迁,进而加速在创意生成、智能搜索等应用场景中的落地。王仲远院长表示,Emu3 下个版本正在研发中,届时将会更加强大。
Emu3 的强大不止于文图视频创作领域,此次更是推动了脑科学领域的科研范式变革,带来全球首个脑科学多模态通用基础模型「见微 Brainμ」。
该模型基于 Emu3 的底层架构构建,首次实现了对 MRI(功能性磁共振成像)、EEG(脑电图)、双光子成像等多种神经信号的统一 token 化,并借助预训练模型的多模态对齐能力,建立起脑信号与文本、图像等模态之间的多向映射。在数据层面,该模型的高质量神经科学数据来自多个大型公开数据集和多个合作实验室,累计处理超过 100 万单位的神经信号数据。
因此,见微 Brainμ 模型支持跨任务、跨模态、跨个体的统一建模框架,能够以单一模型完成包括信号解码、感觉重建、脑疾病诊断在内的多类型神经科学下游任务,展出了强大的通用性与扩展性。而在基础脑科学研究、临床神经应用、脑机接口等多个方向的广泛适应能力,让该模型有望成为「神经科学领域的 AlphaFold」。
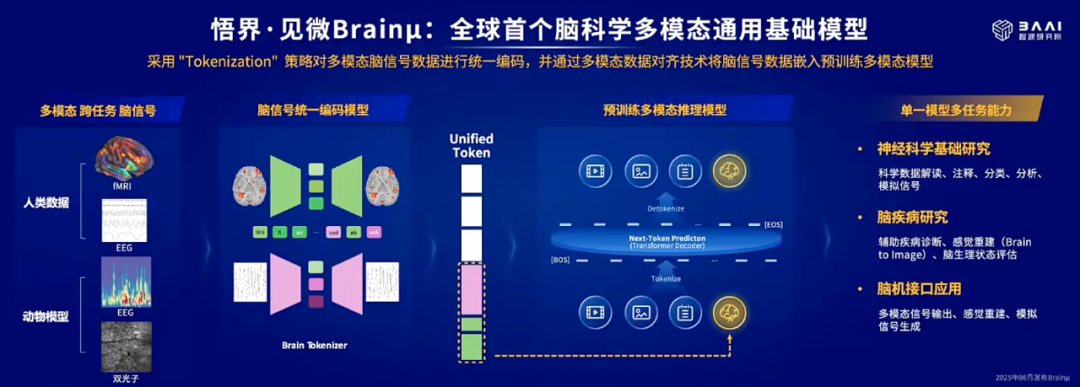
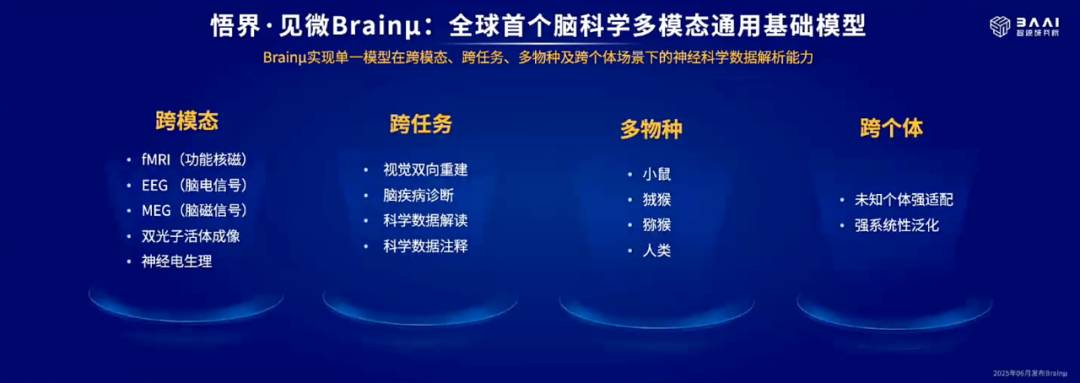
在跨模态、跨场景之外,见微 Brainμ 还具备了跨物种能力,从而加速脑疾病机制的跨物种验证,进一步推动认知科学与比较神经科学的协同发展。
该模型能够同步处理多类编解码任务,兼容了包括人类以及小鼠、狨猴、猕猴等多物种神经数据,支持科学数据自动注释、交互式科学结论解读、大脑感觉信号重建和模拟刺激信号生成等复杂任务。其中,在自动化睡眠分型、感觉信号重建与多种脑疾病诊断等任务中,见微 Brainμ 作为单一模型的性能显著超越了现有的专用模型,并刷新 SOTA 表现。
此外,作为统一的大模型平台,见微 Brainμ 为脑机接口提供了强大技术支撑,与脑机接口企业强脑科技 BrainCO 的合作首次实现在便携式消费级脑电系统上重建感觉信号,推动脑机接口技术走向实用化。
可以说,见微 Brainμ 展示了原生多模态世界模型在脑科学领域的跨越式赋能潜力,有望成为类脑智能时代理解与模拟大脑活动的关键基础设施,并进一步激发脑科学、认知科学与 AI 之间的深度融合。
具身领域的「Linux+GPT」式组合
加速大模型实体化落地
近年来,具身智能已经演化成了最具战略意义的 AI 技术突破口之一。现阶段,机器学习、强化学习以及多模态技术与控制系统的深度融合,让具身大模型百花齐放,尤其以人形机器人、四足机器人为代表的物理实体,不断引爆 AI 社区甚至火出圈。
不过,不通用、不好用、不易用构成了具身智能的三大瓶颈,多数模型依赖特定硬件本体,感知、认知、决策能力不强并在大小脑与本体的适配层面存在较大难度。
面对这些挑战,今年 3 月,智源提出并开源全球首个跨本体具身大小脑协作框架 RoboOS 1.0 和首个跨本体具身大脑 RoboBrain 1.0,打破「专机专模」限制,构建真正的通用具身智能基础模型,在实现极强迁移性的同时,极大降低了微调与适配成本。
今天,「悟界」系列迎来了跨本体具身大小脑协作框架 RoboOS 2.0 与具身大脑 RoboBrain 2.0,相较于 1.0 双双实现了性能的跨越式提升。
其中,RoboOS 2.0 创下了两项全球第一:全球首个基于具身智能 SaaS 平台、支持无服务器一站式轻量化机器人本体部署的开源框架以及全球首个兼容 MCP(模型上下文协议)的跨本体具身大小脑协作框架,通过将「应用商店」模式引入具身领域,既可以促进协作共享与生态繁荣,也将降低「重复造轮子」的成本。
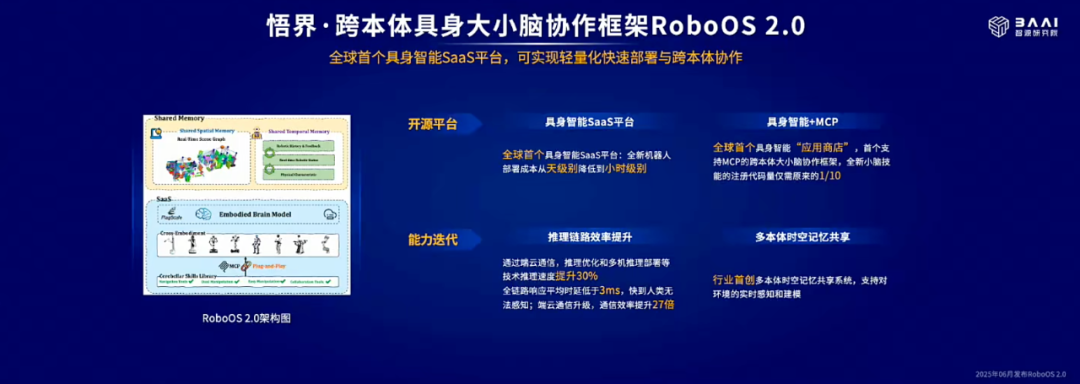
开源的 RoboOS 2.0 框架对开发者非常友好,他们可以一键下载并部署全球开发者创建的同型号机器人本体的小脑技能,进而完成大小脑间的即插即用、无缝协同。该框架还实现了小脑技能的免适配注册机制,将开发门槛打了下来,典型场景下所需代码量仅为传统手动注册方式的 1/10。
此外,「高效、可靠、智能协同」成为此次 RoboOS 2.0 的代名词。得益于端到端推理链路的系统级优化,该框架的整体性能提升达 30%,全链路平均响应时延压缩至 3 毫秒以下,端云通信效率提升高达 27 倍。同时,新增多本体时空记忆场景图共享机制,支持动态环境下的实时感知与建模;引入多粒度任务监控与闭环反馈模块,显著提升任务执行的稳定性与成功率。
种种技术加持下,RoboOS 2.0 的工程可用性与商业落地能力也大大增强。
与 RoboOS 2.0 配套的具身大脑 RoboBrain 2.0 成为目前全球性能最强的开源具身智能大模型,在任务规划、空间推理等多项关键指标上全面超越主流模型,进一步巩固智源在具身智能生态中的领先地位。

对于任务规划,RoboBrain 2.0 在 1.0 基础上「脱胎换骨」,由原来依赖 Prompt 的多机任务规划机制和初级空间理解能力,进化为基于多本体 – 环境动态建模的多机协同规划系统。如此一来,该模型能够实时生成包含本体定位的场景图并自动完成跨本体的任务规划与调度。效果也非常显著,任务规划准确率相较于 1.0 实现了 74% 的大幅提升,展现出了多机协同执行的智能性与稳定性。
在空间智能方面,RoboBrain 2.0 在原有可操作区域(Affordance)感知与操作轨迹(Trajectory)生成能力的基础上,实现了 17% 的性能提升。同时,RoboBrain 2.0 增加了空间推理能力(Spatial Referring),既包含机器人对相对空间位置(如前后、左右、远近)及绝对距离的基础感知与理解能力,也实现了对复杂空间的多步推理能力。
可以预见,机器人在复杂 3D 空间中更能「收放自如」,定位、避障、操作性不可同日而语。
另外,RoboBrain 2.0 像语言模型一样,新增了深度思考能力以及闭环反馈能力,前者让机器人可以对复杂任务进行推理分解以提升整体执行准确率与任务完成准确率,后者让机器人可以根据当前环境感知任务状态,实时调整任务规划与操作策略以应对突发变化与扰动。


配备 RoboOS 2.0 与 RoboBrain 2.0 的机器人遵照指令制作面包三明治。

为人取放饮料。
随着 RoboOS 2.0 与 RoboBrain 2.0 组合的到来,一个强大的「Linux+GPT」式平台正在具身智能领域冉冉升起,为新一代 AI 原生机器人系统提供通用的技术底座与基础架构。
目前,智源已经全面开源了这两大成果,与社区共享框架代码、模型权重、数据集和评测基准,并与全球 20 多家具身智能企业建立战略合作关系,在该领域继续贯彻科技普惠与开放协同理念。
全原子级建模进化
大模型开始理解微观生命的「静动态」
随着大模型深化在语言、图像、视频等宏观世界建模层面的能力,AI 也逐渐从对人类可感知世界的理解拓展到对微观世界的深层建构。
在这一趋势下,智源在「悟界」系列中推出了全原子微观生命模型 OpenComplex2, 标志着多模态大模型在科学领域突破了又一生命尺度。

从功能上来看,OpenComplex2 既可以预测蛋白质、DNA、RNA 小分子结构的静态结构,也能够进行动态构象分布建模。这意味着,该模型在预测「生物分子某一瞬间形态」的同时,对它们在不同时间尺度下的动态变化规律也开始有了理解,更贴近真实生命系统的行为机制。
具体来讲,现在该模型能够描述生物分子系统的连续演化能量景观,并在结合扩散生成式建模机制与真实生物实验数据的基础上,从原子分辨率层面精确捕捉分子间相互作用及平衡构象分布。这一能力进一步拓展了大模型在生命科学中的跨尺度建模能力。
究其原因,OpenComplex2 对生物分子研究范式的突破构建在两大关键创新之上,一是基于 FloydNetwork 的图扩散框架,二是多尺度原子级精度表示,二者结合可以更加真实地还原生物分子的构象多样性和动态特性。
此外,OpenComplex2 还能捕捉原子级、残基级和基序级的相关性,兼顾建模过程中的局部结构细节与全局构象演化,为理解分子功能机制提供了更加系统、完整的结构基础。

OpenComplex2 的效果已经得到了验证,在 2024 年第 16 届蛋白质结构预测关键评估竞赛 CASP16 中,OpenComplex2 成功预测了蛋白质 T1200/T1300 的空间构象分布(定性上与实验数据一致),成为 23 支参赛队伍中唯一取得该突破的团队。
对于 AI for Science 而言,OpenComplex2 为原子级结构生物学开辟全新的建模路径,通过在统一框架下精准解析生物分子系统的动态作用机制,为生命科学研究与应用带来变革性进展。
随着该模型的出现,从基础分子机制探索到新药发现、靶点验证等各个下游环节都有望实现加速,从而大幅缩短生物医药研发周期、降低研发成本并提升成果转化率。
未来,AI for Science 将逐步进入深水区,更早构建跨模态、跨学科、跨任务、跨物种、跨尺度的科学建模基础设施,势必会在竞争中获得先发优势。
结语
今年 1 月,智源发布 2025 十大 AI 技术趋势,其中就囊括了「悟界」系列大模型中的这些内容。从行业趋势预测到今天全新系列模型的问世,智源称得上行动迅速,向整个 AI 社区宣告了自身范式的战略性升级。
智源「悟界」系列不再只强调语言建模,转而回到了 AI 的更本源问题 —— 如何建模这个世界。这一目标的牵引,会为原生多模态、世界模型、具身智能、AI for Science 等多个赛道注入新的活力。同时,这四大方向的协同布局,是现阶段智源从认知智能走向具身智能与科学智能的关键一步。
当然,受益的不单单是智源自身,整个 AI 社区也会从「悟界」系列中得到一些启发。在主流语言建模范式之外,一组面向科学认知、具身行为、神经与生命模拟的基础模型群铺展开来。以物理世界为探索目标的 AI,为行业其他玩家提供了一种可借鉴的发展路径。
未来,真正的大模型时代不会止步于提示框,而将深入到每一个理解世界、改变世界的系统中。
©
(文:机器之心)