
机器之心编辑部
在通往通用人工智能(AGI)的进程中,混合专家(MoE)模型凭借动态稀疏计算优势,成为大模型推理提效的关键路径。华为团队重磅推出昇腾平台原生设计的 Pangu Pro MoE 72B模型,大幅降低计算开销,并在SuperCLUE千亿内模型并列国内第一。
通过系统级软硬协同优化、高性能算子融合优化、模型原生投机算法优化,Pangu Pro MoE 推理性能提升 6~8 倍,在昇腾 300I Duo 上单卡吞吐可达 321 tokens/s,实现极致性价比;在昇腾 800I A2 上更可飙升至 1528 tokens/s,全面释放硬件潜力,打造极致的推理体验。

技术报告地址:https://gitcode.com/ascend-tribe/ascend-inference-system/blob/main/%E6%98%87%E8%85%BE%E5%B9%B3%E5%8F%B0Pangu%20Pro%20MoE%E5%85%A8%E9%93%BE%E8%B7%AF%E9%AB%98%E6%80%A7%E8%83%BD%E6%8E%A8%E7%90%86%E7%B3%BB%E7%BB%9F%E4%BC%98%E5%8C%96%E5%AE%9E%E8%B7%B5.pdf
推理效率拉满:全链路推理系统优化,释放昇腾澎湃算力
在大模型的分布式推理中,每个计算节点都像一个团队成员,信息流通、协调协作不可避免。就像一场跨部门的大项目,若每一步都开「全员大会」,沟通成本高、效率低,项目推进自然慢半拍。聪明的做法,是开对会、分好组,精准沟通、各司其职。这正是华为团队在 Pangu Pro MoE 大模型推理优化中的灵感来源!
分层混合并行(H2P):不再「全员大会」,「专人专会」推理才高效!
还在用「一刀切」的并行方式处理大模型?就像公司里什么事都开全员大会,不管你是财务还是研发,全都坐在会议室浪费时间 —— 看似热闹,实则低效。
华为团队另辟蹊径,灵感来自「专人专会」策略,提出创新性的 H2P 分层混合并行(Hierarchical & Hybrid Parallelism)。与其让所有模块频繁地「开大会」,不如根据任务特性「分工开小会」,让每个部分在各自的通信域内中高效执行!
该策略精准匹配模型结构和硬件互联拓扑特性:Attention 模块采用 DP2+TP4 并行方案,轻量参数聚焦单 CPU 内高效通信;Expert 模块针对路由专家的分组与动态负载,采用 TP2+EP4 策略,实现计算均衡与效率提升;共享专家则以 TP8 全芯并行,加速稠密计算,全方位激发昇腾平台算力潜能。
H2P 策略进一步在 Attention 模块引入 Reduce-Scatter 替代 AllReduce,避免数据聚合操作导致后续通信传输数据量膨胀,并通过优化 AllGather 插入位置,降低冗余向量计算;同时基于分组专家设计,Expert 模块利用全局 AllGather 高效完成 token 与专家的动态匹配,结合全局 Reduce-Scatter 实现路由专家与共享专家的归一通信。
通过这种「哪类事开哪类会」的智慧分工方式,H2P 策略让每个模块都在最适合的并行方式下发挥最大潜能,摆脱了传统「大锅饭式」并行的性能瓶颈,让推理效率飞升一大截,Decode 吞吐性能相比纯 TP 方案提升 33.1%。
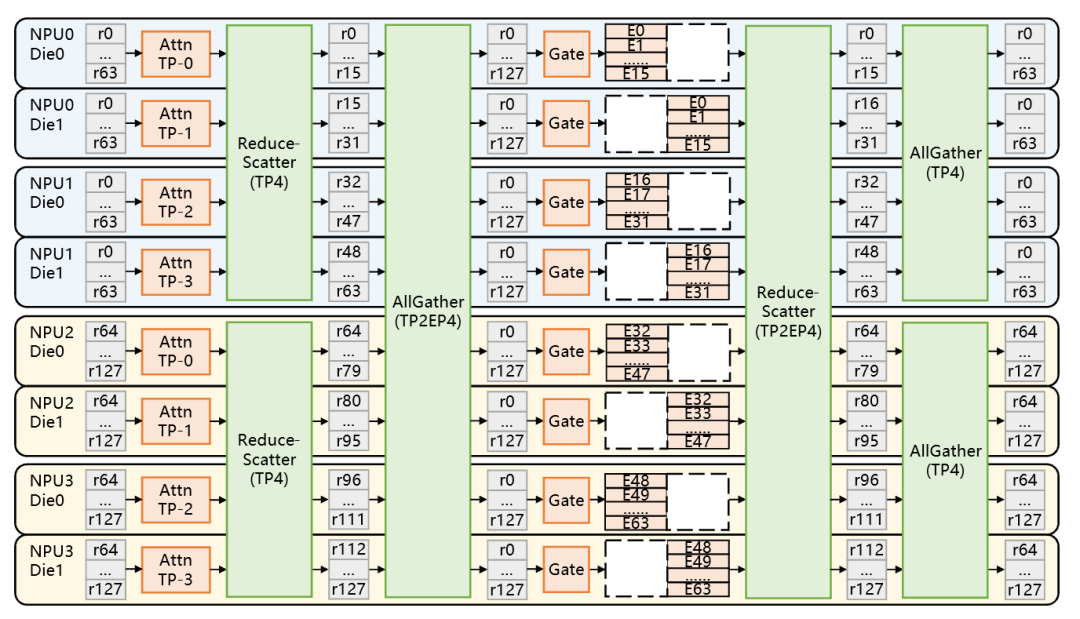
图 1 H2P 优化方案示意图
攻克通信瓶颈(TopoComm):拒绝「冗余发言」,「言简意赅」推理才畅通!
在大模型推理中,通信就像一场大型数据会议:「会前准备」是静态开销,「会中发言」则对应数据传输。华为团队以「提高开会效率」为目标,设计 TopoComm 优化方案,从会前准备到会中交流环节全方位深度优化集合通信,让数据传得快、讲得清、效率高。
针对静态开销,提出 SlimRing 算法,利用 Ring 链路通信对象固定特性,合并相邻通信步的后同步与前同步操作,同步次数降低 35%。针对传输耗时,提出 NHD 算法,通过拓扑亲和的分级通信等效提高链路有效带宽 21%;进一步引入 INT8 AllGather + FP16 Reduce-Scatter 的混合量化通信策略,结合跨芯校准与量化因子复用,实现通信数据压缩 25%,AllGather 通信耗时降低 39%。
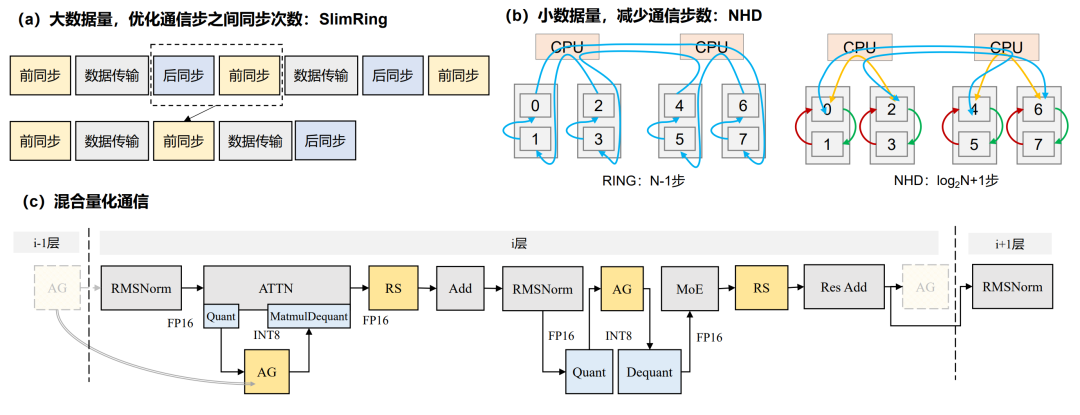
图 2 TopoComm 优化方案示意图
计算 & 通信融合(DuoStream):告别「干等闲耗」,推理「开会干活」两不误!
大模型分布式并行推理就像一个协作型项目,需要多卡在通信(开会)与计算(干活)之间不断交替执行。高效的团队往往能在会议中一边讨论、一边分工执行,真正做到边「开会」边「干活」,从而大大提高整体效率。华为团队正是借助这一理念,深入挖掘昇腾平台多流架构的潜力,提出 DuoStream 算子级多流融合通算优化方案,实现计算与通信的细粒度并发调度,大幅提升推理计算效率。
针对 Pangu Pro MoE 模型中 Expert 模块通信占比高的问题,构建 GMMRS(GroupedMatmul+Reduce-Scatter)与 AGMM(AllGather+Matmul)两大融合策略,有效克服通信与数据搬运和计算之间的瓶颈,实现关键通信路径的流水掩盖,进一步释放模型在昇腾平台上的推理性能。通过这套 “边讨论边干活” 的融合式优化机制,通信与数据搬运和计算协同推进,显著提升了模型在昇腾平台上的推理效率,最大化释放硬件资源潜能。
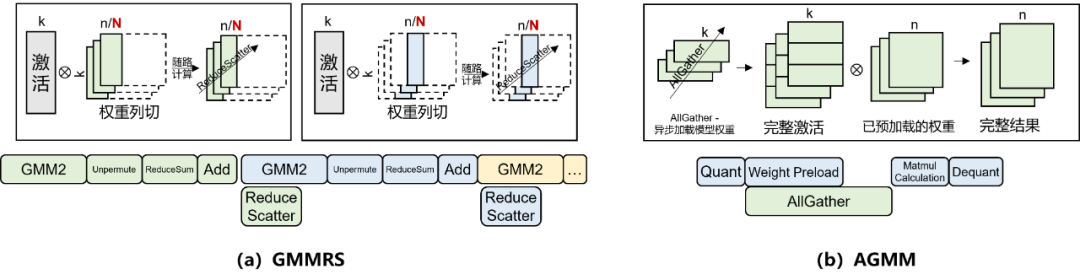
图 3 DuoStream 优化方案示意图
打造六边形算子战队:单兵作战到特种部队,融合算子释放昇腾潜能
在大模型推理的算力战场上,传统算子如同各自为战的「单兵」,每个算子独立执行、协作脱节。数据搬运兵(内存访问) 与计算突击手(矩阵乘)各自为战,每次任务需反复传递数据(全局内存读写),大量兵力浪费在资源协调上(Kernel 启动开销),导致资源调度低效、内存搬运频繁,造成大模型推理的「单兵算子困局」。为终结算力内耗以释放硬件潜力,华为团队重构算子执行范式,打造两支精锐「融合算子特种部队」——MulAttention 和 SwiftGMM,实现了从资源访问、计算调度到数据搬运的全链路优化,显著提升推理性能表现。
MulAttention:注意力计算尖刀连,打下推理 KV 搬运桥头堡
随着并发数和序列长度持续增长,Attention 计算时延在整网占比达 30% 至 50%,其中 KV 缓存搬运占据了约 70% 的算子执行耗时。为此,华为团队基于昇腾架构打造原生高性能融合算子 ——MulAttention。
该算子围绕增量推理阶段 KV 数据搬运与计算的高效流水编排开展优化,通过构建 KV 大包连续搬运优化策略,极大提高了访存带宽利用率。同时设计 KV 预取流水机制,有效降低计算的暴露时延。进一步构建了 KV 双循环结构,解耦矩阵与向量计算间数据依赖,缓解指令队列堵塞同时提高向量计算并行度。最终实现 Attention 计算加速 4.5 倍,达成 89% 以上的数据搬运流水占用率以及 87% 的访存带宽利用率。
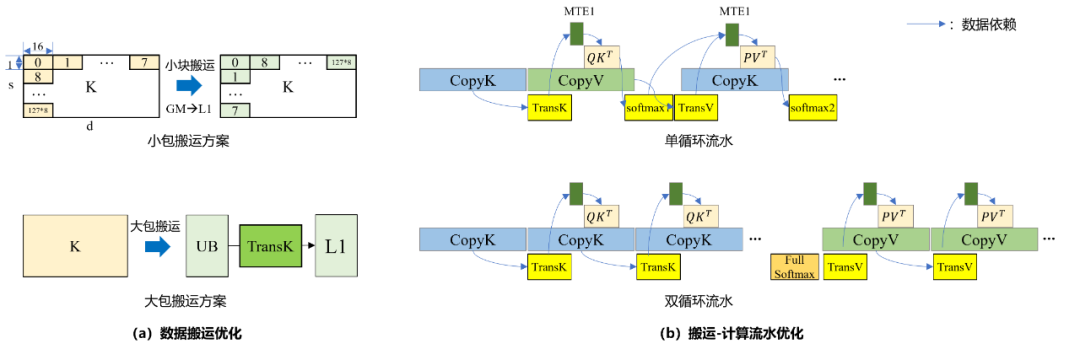
图 4 MulAttention 融合算子优化设计示意图
SwiftGMM:专家计算突击队,闪电速度抵达推理算力战场
路由专家权重搬运已成为 MoE 模型端到端时延的核心瓶颈,且其稀疏激活特性导致的负载动态波动进一步放大了性能优化的挑战。对此,华为团队面向昇腾平台推出高性能矩阵计算引擎 ——SwiftGMM。
SwiftGMM 引入基于历史数据的智能分块缓存策略,通过动态预测并调整最优分块参数,规避重排开销;同时根据计算负载强度,动态切换 GEMV 与 GEMM 执行模式,实现轻重计算任务的灵活调度,保障算子始终运行在高效区间。此外,该算子结合左矩阵单次加载与常驻方案以及双缓存机制,进一步实现数据搬运与计算的高效流水。通过上述系列「闪电突袭」,实现 GMM 计算加速 2.1 倍,解码阶段整网推理时延降低 48.7%。
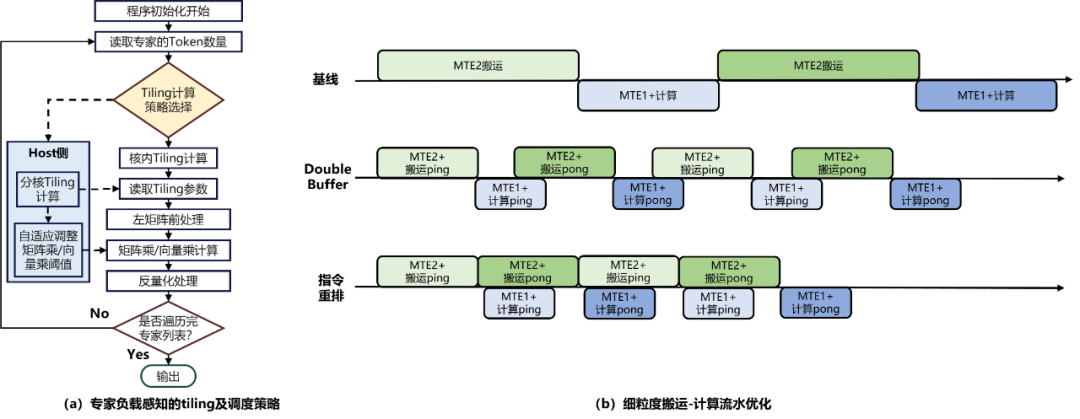
图 5 SwiftGMM 融合算子优化设计示意图
推理算法加速:降本增效,实现推理性能与资源效率的双重跃升
推理系统端到端竞争力不仅涉及单一模型推理,还涉及输入输出序列长度优化,多个模型组合推理。华为团队提出专家动态剪枝算法 PreMoE。针对慢思考输出序列长度过长,提出反思压缩 TrimR 算法。针对多个模型协同,设计实现了反思投机 SpecReason 算法。
PreMoE:给 MoE 模型动态「瘦身」
MoE 模型在处理不同任务时,只有特定的专家会被显著激活。和去医院就诊一样,每次挂号去一个科室。MoE 模型的专家动态剪枝 PreMoE 算法,由两个创新性技术组件组成:PEP 用来度量专家重要性,选出给定任务最相关的专家;TAER 查询相似性动态加载与任务相关的专家。保持模型准确率的同时,实现推理吞吐提升 10%+。
组合拳出击:多个模型协同优化
在复杂逻辑问题上,慢思考生成冗长的中间「思考」。但是一旦模型找到正确答案,更进一步的思考收益甚微(「过度思考」);在非常困难的问题上,模型在不同的解决方案之间频繁切换(「欠思考」)。华为团队提出 TrimR 反思压缩算法,用一个小的 7B 模型去动态监测大模型是否出现过度思考和欠思考,如果思考过程异常,通过修改 Prompt 及时让大模型终止并给出最终答案,推理步数降低 14%。
大模型通常能力较强,小模型相对能力偏弱,但是小模型能够解答子问题。SpecReason 反思投机算法使用小模型首先生成 token 序列(如短分析段或假设),而不是单 token 预测,然后大模型执行正确性验证:如果有效,将内容合成为浓缩摘要,并为下一个分析步骤提供方向性指导(如指定下一步探索哪个方面);如果无效,调整小模型的推理方向,使其重新考虑假设或转向替代假设。SpecReason 充分发挥了小模型的优势,推理吞吐提升 30%。
性能全面突破:昇腾亲和软硬协同优化,推理解码性能暴涨 6~8 倍
昇腾 800I A2:大模型的高性能推理平台
在解码阶段采用 4 卡部署策略,Pangu Pro MoE 模型实现了卓越的推理性能:小并发场景下(BS=1,Seq=2k)权重搬运量仅 16B,具备低时延响应能力;大并发场景下(BS=456,Seq=2k),单卡吞吐达 1148 tokens/s,较 72B 和 32B 稠密模型分别提升 97% 和 18%。结合 MTP 投机推理技术,在 token 接受率达 0.9 时,单卡 BS 可提升至 146,平均时延降至 95.56 ms,最高吞吐突破 1528 tokens/s,显著提升高并发任务的推理效率。
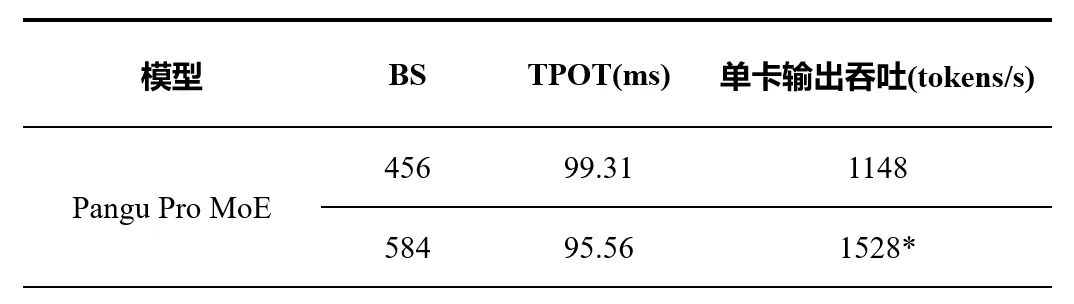
表 1 昇腾 800I A2 服务器 4 卡配置下解码阶段推理性能测试结果(输入长度 2k)。* 表示在 MTP 投机推理接受率达到 0.9 条件下可达到的最高输出吞吐。
昇腾 300I Duo:极致性价比的推理平台
依托 Pangu Pro MoE 模型与昇腾平台的深度协同,昇腾 300I Duo 在百亿级 MoE 模型推理中展现出卓越性能与极高性价比。在预填充阶段,2 卡 2 路并发下实现 2k 序列输入仅 1.94s 延迟,单卡吞吐达 1055 tokens/s。在解码阶段,4 卡部署灵活适配不同并发需求:小并发场景下延迟低至 50ms,大并发场景(BS=80)下单卡吞吐达 201 tokens/s,兼顾低延迟与高吞吐。结合高接受率的 MTP 技术,单卡 Batch Size 可提升至 32,平均时延降至 99.7ms,吞吐最高达 321 tokens/s,充分释放 MoE 模型在昇腾平台的推理潜能。与 800I A2 推理相比,300I DUO 能够提供更加经济的 MoE 推理解决方案,为各行各业的推理应用部署提供极具性价比的选择。
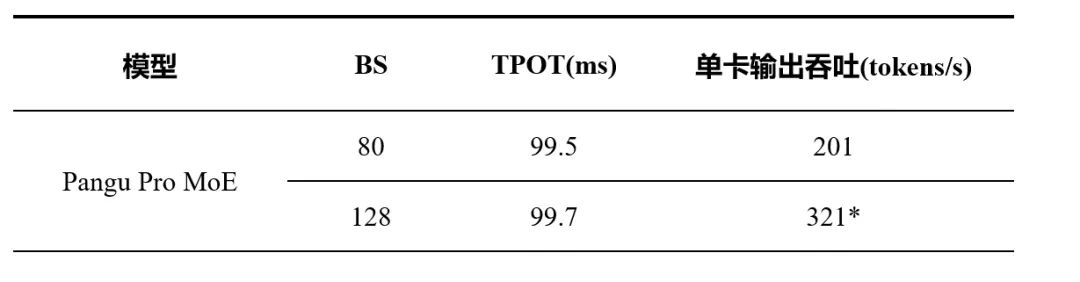
表 2 昇腾 300I Duo 服务器 4 卡配置下解码阶段推理性能测试结果(输入长度 2k)。* 表示在 MTP 投机推理接受率达到 0.9 条件下可达到的最高输出吞吐。
至此,昇腾盘古推理系统的全流程优化已全面揭晓。从系统级优化到高性能算子,软硬协同、层层突破、步步精进,构建起高性能、大规模、低成本的推理能力底座。华为团队持续深耕模型 – 系统的软硬协同创新,为通用大模型的规模部署和高效落地提供了坚实支撑。
©
(文:机器之心)