

知识蒸馏(KD)是一种将大模型(教师)的知识迁移到小模型(学生)的技术,学生通过模仿教师预测分布,充分利用软标签信息,通常优于传统监督微调,已在图像分类、文本生成等任务及最新工作(如 DeepSeek-R1、Qwen-3)中得到验证。其核心在于分布匹配方式的选择,主流方法多用前向 KL 散度(FKLD)或反向 KL 散度(RKLD),但 FKLD 易导致输出过度平滑,难以聚焦关键类别,RKLD 则使学生过度自信、降低多样性。实验证明,两者在多任务中表现有限,且目前缺乏系统方法揭示其深层问题,阻碍了更通用高效 KD 框架的发展。因此,一个自然的问题产生了:
究竟是什么潜在因素导致了 FKLD 和 RKLD 的次优表现?
为了解答这个问题,我们通过追踪对数质量比(LogR),分析不同散度在训练中如何影响学生分布的概率分配。进一步分析表明在温和假设下, 与损失函数对 logits 的梯度成正比,这使我们将问题转化为分析:不同散度算法如何影响 下降。

-
标题:ABKD: Pursuing a Proper Allocation of the Probability Mass in Knowledge Distillation via α-β-Divergence
-
论文:https://arxiv.org/abs/2505.04560
-
代码:https://github.com/ghwang-s/abkd
在此框架下,我们识别出两种关键的「模式集中效应」:难度集中与置信集中。
-
「难度集中」指的是更关注于在教师分布 与学生分布 之间误差较大的模式。 -
「置信集中」指的是更关注于学生分布 本身高度自信的模式。
进一步研究发现,FKLD 和 RKLD 的局限性正源于对这两种集中效应的极端利用。

-
FKLD 集中效应较弱,对所有类别误差一视同仁,导致学生难以聚焦目标类别,易出现错误预测(见图 1d)。
-
RKLD 集中效应过强,兼顾高误差和高置信度类别,易陷入「平凡解」,即学生只关注目标类别,忽略教师分布的其他知识(见图 1e)。
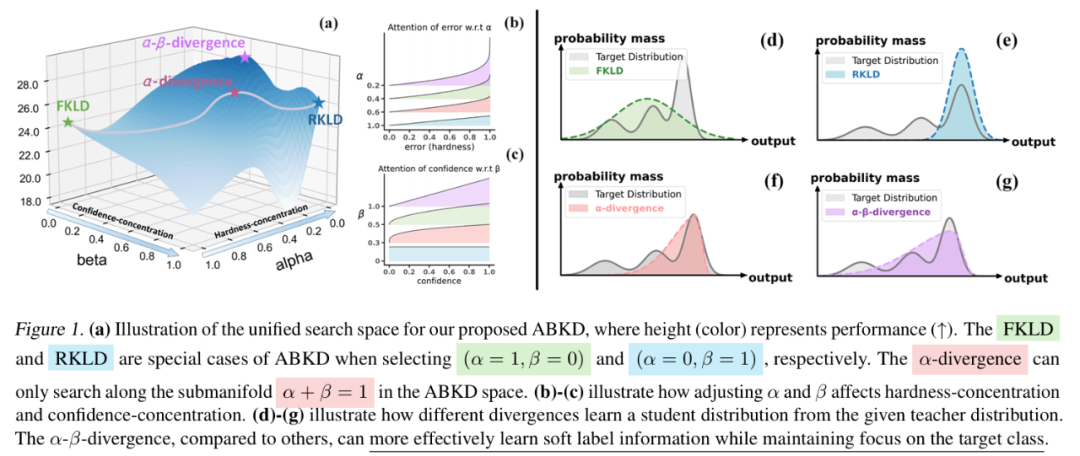
揭示这些局限性后,我们提出一个关键问题:我们能否找到一种通用且理论上有依据的方法,来平衡「难度集中」与「置信集中」效应?
方法
为此,我们引入了 α-β 散度。
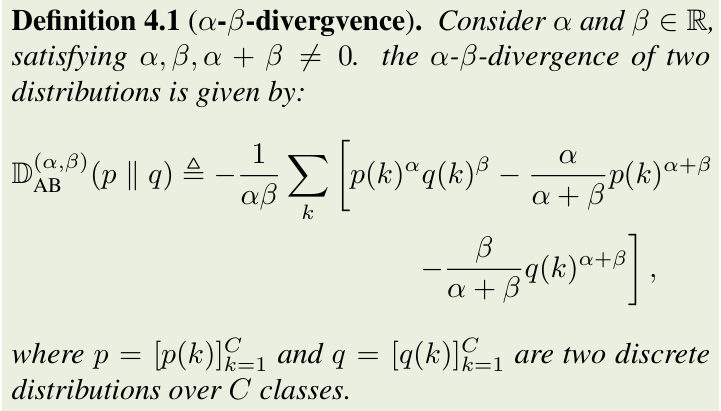
其广义统一了 FKLD、RKLD 及 Hellinger 距离等多种散度。

正如下一节理论表明,α-β 散度可通过调节 α 和 β 在 FKLD 与 RKLD 间平滑插值,实现对难度集中和置信集中效应的灵活权衡。这一机制带来更合理的概率分配,据此我们提出了通用蒸馏框架 ABKD,形式为最小化:
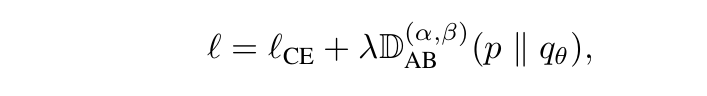
基于 α-β 散度平衡难度集中和置信集中
ABKD 提供了一个统一空间权衡难度集中与置信集中。为解释这一点,回到对数质量比(LogR)。下列命题解释了超参数 α 和 β 如何影响 的减小。

在 (a) 和 (a1) 中,α-β 散度通过幂次形式 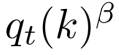 体现置信集中效应:
体现置信集中效应:
-
当 时,退化为 RKLD 的效应。 -
当 时,退化为 FKLD 的效应。
较大的 β 值会增强置信集中效应,使匹配性能更加专注于模型最有信心的类别(见图 1c)。
在 (b) 和 (b1) 中,使用以下方式衡量难度集中效应:
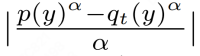
-
当 时,退化为 FKLD 的效应。 -
当 时,退化为 RKLD 的效应。
较小的 α 会放大难度集中效应,在困难类别上进行更强的误差惩罚,从而实现更激进的匹配(见图 1b)。
通过调节 α 和 β,ABKD 实现对两种效应的精细平衡,避免了传统方法(FKLD/RKLD)的极端情况(见图 1g)。
与 α-散度的比较
α-散度是 ABKD 框架的一个特例(当 时成立)。
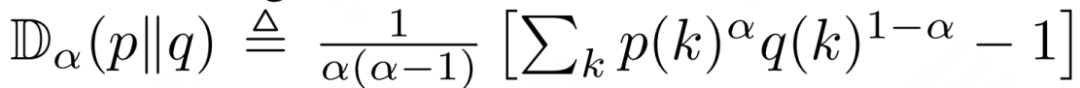
虽然它也能实现 FKLD()和 RKLD()之间的转换,但根据命题 4.2,为了减小 α,必须相应地增大 β,以满足 的限制条件。这种不必要的限制阻碍了其性能的进一步提升,具体如图 1(a) 和图 1(f) 所示。
与 WSD 的比较
另一种方案是对 FKLD 和 RKLD 取加权和(WSD):
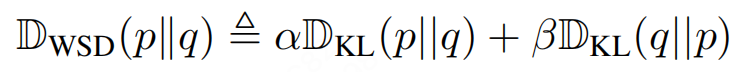
不幸的是,这种组合度量会过度强调 和 中概率较小的模式。当 或 时,有:
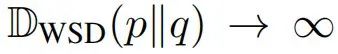
因此,算法必须关注极端情况以最小化目标函数,导致概率分配不合理。此外这种情况下梯度范数也会过度增长,导致参数更新中可能含有噪声,破坏优化稳定性。
最后一种方法是使用 Jensen-Shannon 散度:
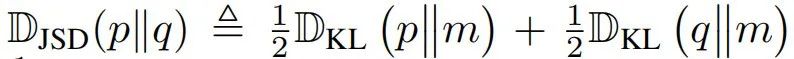
其中 。它的缺点是当分布 和 相距较远时(这是训练初期的常见情况),会出现梯度消失,阻碍模型收敛。
实验
自然语言任务
我们在五个指令跟随基准上评估方法,使用 ROUGE-L 指标,对比了 SFT、FKLD、GKD 和 DISTILLM 等方法。
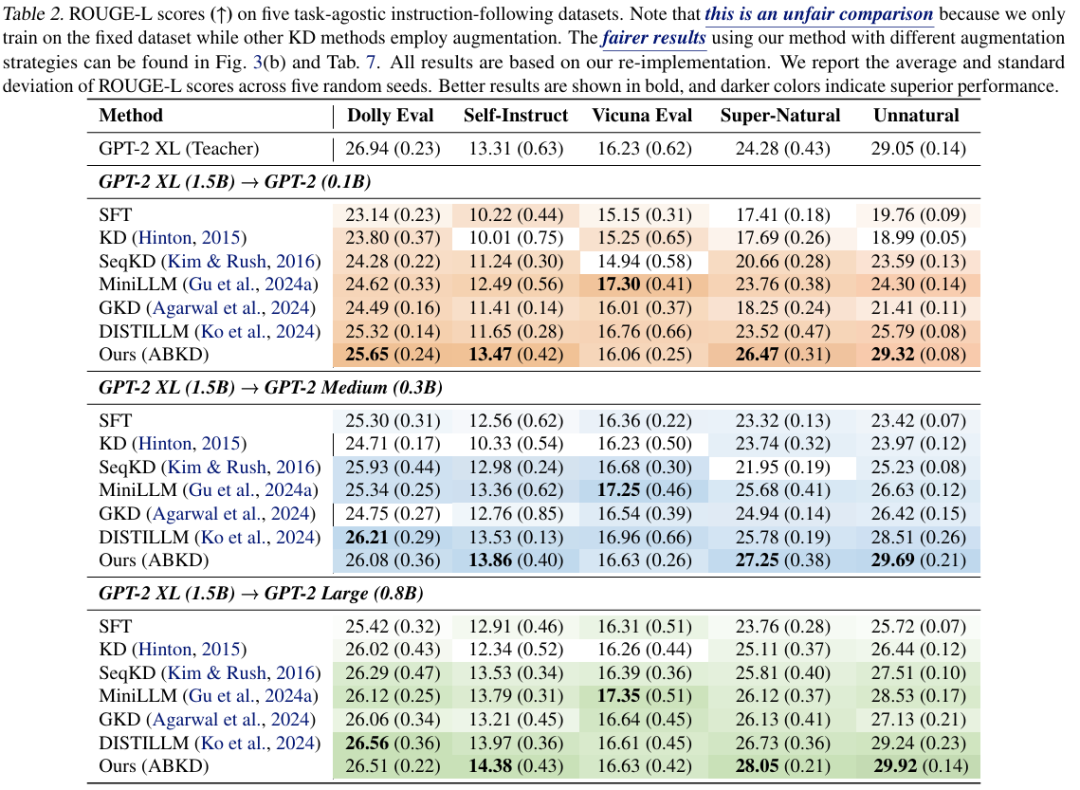
实验结果表明仅修改蒸馏目标,ABKD 在不同数据集上均优于或匹配 FKLD、SFT。对比基于 SGO 的方法(如 GKD、DISTILLM)效果提升明显,ABKD 在不公平对比下依然表现优越。
-
损失函数影响
α-β 散度优于 α 或 β 散度及 WSD。在五个数据集上相较基线有稳定提升。训练过程中的优势也体现在图 2。
视觉任务
在 12 个常用图像识别数据集上进行实验,对比方法比较了多种先进蒸馏方法:KD、DKD、LSD 和 TTM 等。
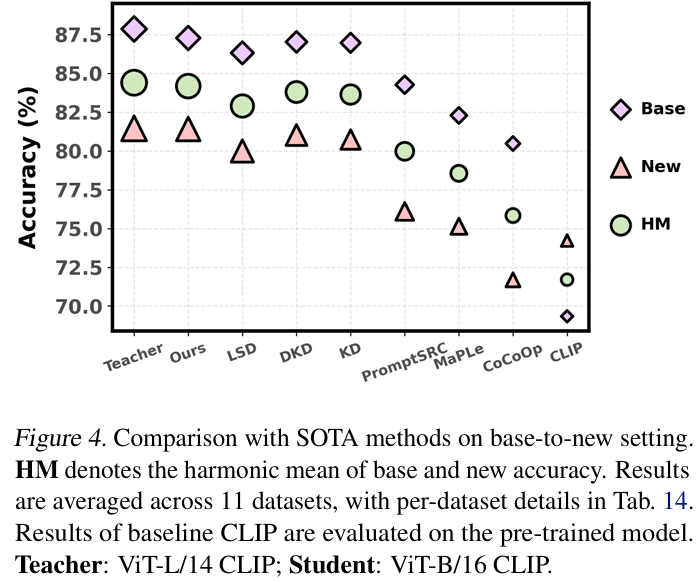
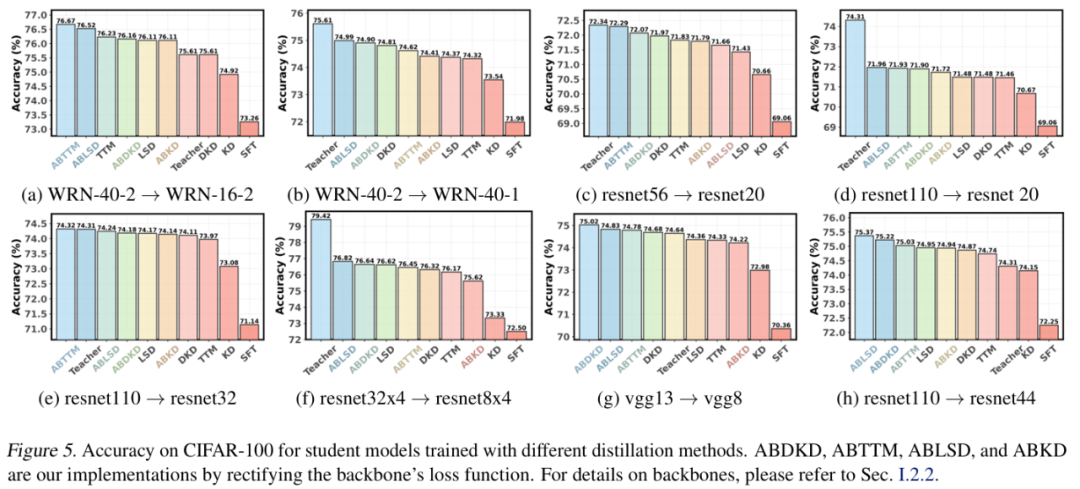
结果表明 ABKD 能根据不同教师-学生组合自动选择合适的蒸馏目标。此外 ABKD 可作为简单的插件工具,优化现有方法的损失函数,带来额外性能提升。
敏感性分析
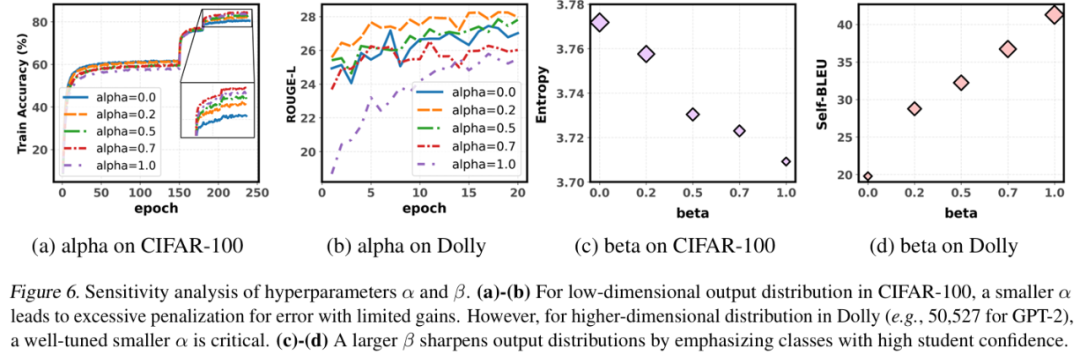
α 对难度集中的影响:图 6(a)(b) 展示了不同 α 下的训练表现。在 CIFAR-100 中,较小 α 提升有限;在 Dolly 等大输出空间任务中,适当减小 α 有助于避免陷入局部最优。
β 对置信集中的影响:图 6(c)(d) 显示了 β 对输出分布的 Shannon 熵和 Self-BLEU 的影响。较小 β 使模型更关注低置信度类别,提升输出分布的平滑性和多样性(熵更高,Self-BLEU 更低)。
结语
本文指出,知识蒸馏的核心在于平衡「难度集中」和「置信集中」两种效应,而传统 FKLD 和 RKLD 只覆盖两个极端,导致概率分配不合理。为此,我们提出基于 α-β 散度的 ABKD 框架,统一并推广了现有方法,实现两种效应的灵活权衡。理论与大量实验均验证了 ABKD 的有效性。

©
(文:机器之心)