
-
Github 链接:https://github.com/openbmb/minicpm -
技术报告链接:https://github.com/OpenBMB/MiniCPM/blob/main/report/MiniCPM_4_Technical_Report.pdf https://arxiv.org/pdf/2506.07900
-
Huggingface链接:https://huggingface.co/collections/openbmb/minicpm-4-6841ab29d180257e940baa9b
-
Model Scope链接:https://www.modelscope.cn/collections/MiniCPM-4-ec015560e8c84d


超 3000 人的「AI 产品及应用交流」社群,不错过 AI 产品风云!诚邀所有 AI 产品及应用从业者、产品经理、开发者和创业者,扫码加群:
进群后,您将有机会得到:

· 最新、最值得关注的 AI 产品资讯及大咖洞见
· 独家视频及文章解读 AGI 时代的产品方法论及实战经验
· 不定期赠送热门 AI 产品邀请码

-
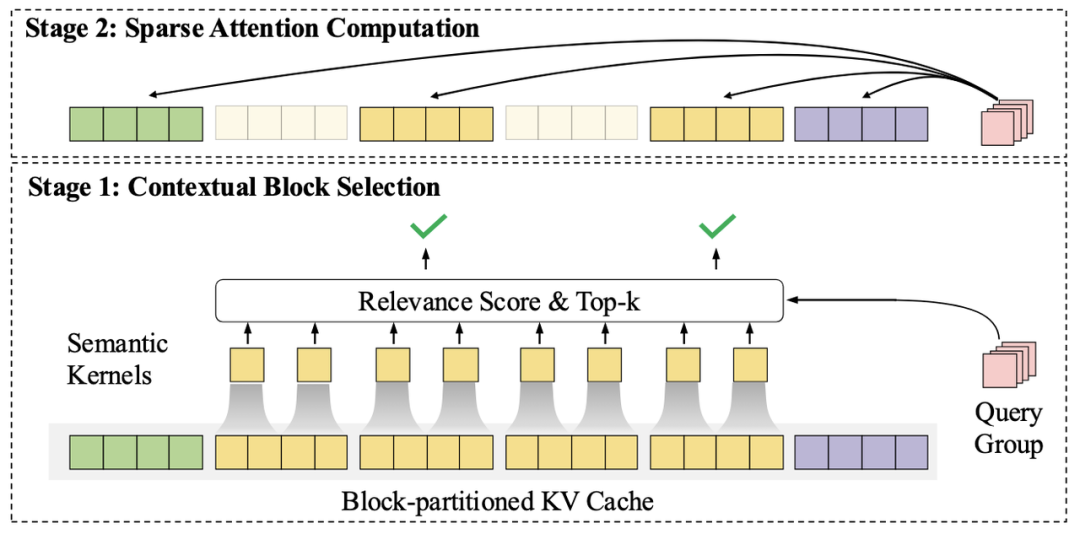
更精准的上下文块选择算法:在InfLLM中,每个上下文块由少量代表元构成单一的语义表示。InfLLM v2引入了细粒度语义核的概念,每个上下文块由多个细粒度语义核构成。查询词元与上下文块的相关性分数为查询词元与该上下文块中包含的所有语义核相关性分数最大值。该方法使得模型能够更精准地选择上下文块。 -
更细粒度的查询词元分组:InfLLM在预填充阶段将多个查询词元分成一组,使该组内所有查询词元选择相同的上下文块进行注意力计算。该方法会造成模型训练与推理的不统一。InfLLM v2中采用了更细粒度的查询词元分组 —— 要求Grouped Query Attention中每组查询头共享相同的上下文块。该划分在保证了底层算子高效实现的同时,提升了模型上下文选择的准确性。 -
更高效的算子实现:为了InfLLM v2能够在训练与推理过程中充分发挥其理论加速优势,MiniCPM4开发并开源了InfLLM v2的高效训练与推理算子。同时,为了能够快速地选取TopK上下文块,MiniCPM4中提出了一种高效的LogSumExp估计算法。相比于DeepSeek NSA算法,MiniCPM4中采用的TopK上下文选择方法,能够节省60%的计算开销。


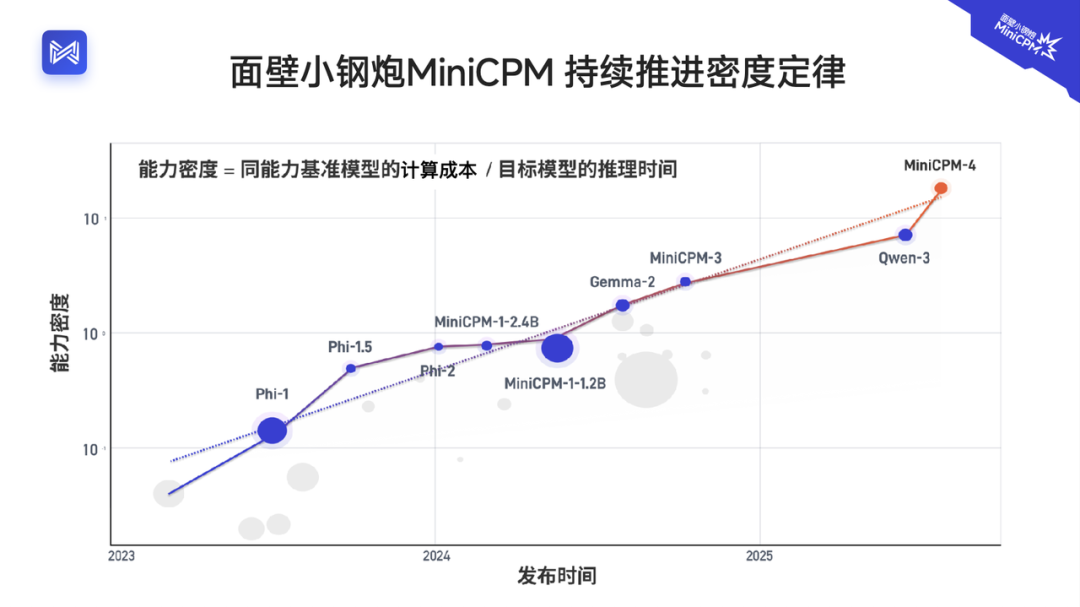
(文:AI科技大本营)