

极市导读
通过结合 GPT-4、SAM 和 CLIP,DynAlign实现了跨域语义分割中前所未有的无监督动态类别对齐能力。无需目标域标注,DynAlign 即可自适应全新标签空间,突破了传统方法的瓶颈,在智能驾驶、城市管理等场景中展现出极强的落地潜力。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/abs/2501.16410
在计算机视觉领域,跨域语义分割始终面临图像级域差异与标签级分类差异的双重挑战。无论是自动驾驶中的复杂路况识别,还是医疗影像的精准分析,现有方法在无监督场景下都难以突破新标签空间适应的瓶颈。瑞士洛桑联邦理工学院(EPFL)推出的 DynAlign 框架凭借突破性的无监督动态分类对齐技术,为该领域带来全新解决方案。其代码已开:https://github.com/hansunhayden/DynAlign。
一、DynAlign 核心创新:多维度技术突破
(一)图像级适应:夯实领域特定知识基础
基于 HRDA 模型,DynAlign 采用多尺度特征对齐机制,在无需目标域标注的情况下,实现模型适应性的优化训练。
(二)标签级对齐:构建开放世界语义桥梁
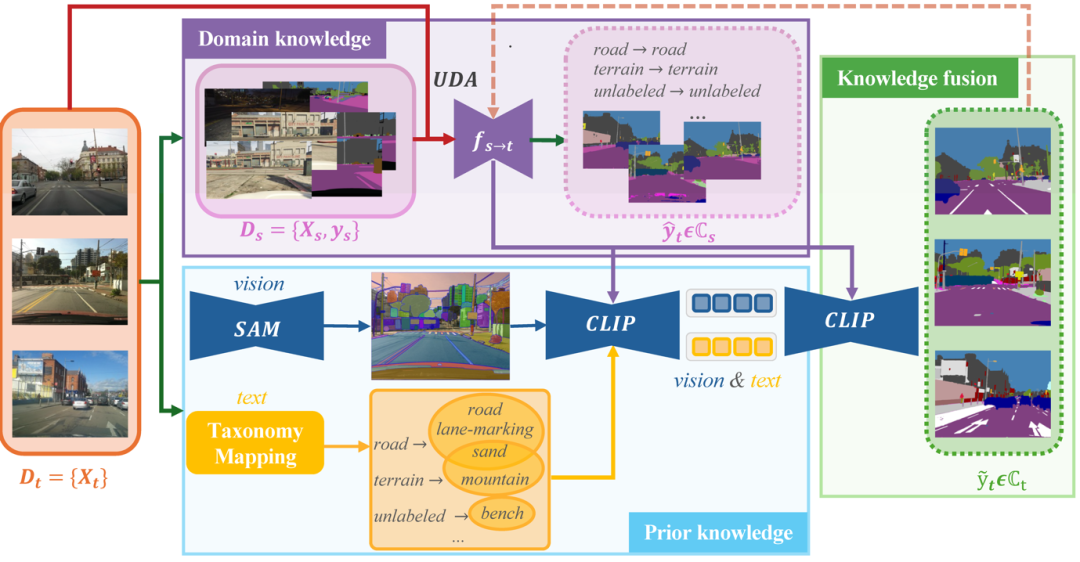
LLM 动态分类映射:借助 GPT-4 强大的自然语言处理能力,DynAlign 构建源标签与目标标签间的动态映射关系。不仅支持类别粒度的扩展,如将 “road” 细化为 “road+sidewalk+lane marking”,还能引入全新类别,例如适配目标域特有的 “catch basin”,实现标签体系的灵活拓展。
SAM 细粒度视觉分割:Segment Anything 模型在 DynAlign 中发挥关键作用,生成高精度掩码提案,能够精准定位目标区域边界。以 “road” 为例,可进一步分割出 “lane marking” 等子区域,极大提升分割结果的细节准确性。
CLIP 跨模态知识融合:依托 CLIP 的图文匹配优势,DynAlign 将视觉特征与 LLM 生成的上下文文本特征进行深度对齐。通过将视觉信息与诸如 “traffic lane marking” 等文本语义关联,实现标签的重新分配,有效解决标签级分类差异问题。
(三)动态知识融合机制
对于 SAM 生成的掩码区域,DynAlign 首先基于多数投票法获取初始源标签,再通过分类映射检索候选目标标签。最后,利用 CLIP 计算跨模态相似性,动态更新为最合适的目标标签。整个过程无需目标域标注,仅通过模型推理即可实现对新标签空间的自适应,灵活性远超传统方法。
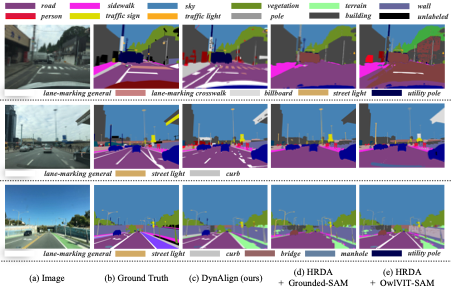
二、实验验证:创新驱动显著性能提升
(一)核心性能对比
研究以合成数据集 GTA 为源域,Mapillary Vistas 和 IDD 为目标域展开实验。在 Mapillary Vistas 数据集上,DynAlign 的 mIoU 达到 36.7%,大幅领先 Grounded-SAM(28.6%)、OWL-ViT(19.5%),较两者分别高出 8.1%、17.2%;在 mAcc 指标上,DynAlign 同样表现优异,达到 75.3%,而 Grounded-SAM 和 OWL-ViT 仅为 68.2% 和 61.5%。
在 IDD 数据集的未知类别分割任务中,DynAlign 的 mIoU 达 18.1%,较 HRDA+Grounded-SAM 组合提升 4%;在已知类别分割中,mIoU 达到 52.4%,相比 OWL-ViT 提升了 12.3%,充分证明其在跨域场景下对不同类别都具备强大的识别与分割能力。
(二)消融实验验证
通过逐步移除 DynAlign 的关键组件进行消融实验发现,多尺度视觉特征和上下文文本特征对模型性能提升至关重要。单独去除多尺度视觉特征,mIoU 下降 6.6%,mAcc 降低 5.2%;缺少上下文文本特征,mIoU 降低 0.4%,mAcc 减少 0.8%。当同时移除这两个关键部分时,模型在 Mapillary Vistas 数据集上的 mIoU 骤降至 29.3%,与完整模型相比差距高达 7.4%,这进一步验证了 DynAlign 创新架构各组件的协同有效性和不可或缺性。
(三)伪标签训练与推理效率
利用 DynAlign 生成的伪标签训练 Mask2Former,mIoU 进一步提升至 38.9%,相比未使用伪标签训练时提升了 2.2%。在推理效率方面,DynAlign 推理时间缩短至 0.3 秒 / 图像,在保证高精度的同时,实现了高效推理,满足了实际应用场景对速度的需求 。
三、多元应用场景:创新技术的实践延伸
在智能驾驶领域,面对不同国家道路标签体系差异,DynAlign 通过 LLM 构建动态标签映射,结合 SAM 细粒度分割能力,精准识别复杂路况,如在 GTA→IDD 实验中,对印度特色 “autorickshaw” 类别的分割 mIoU 达 36.5%。在智能城市管理中,其利用 GPT-4 增强标签语义清晰度,通过 CLIP 实现多源数据城市部件的统一分类,为城市管理自动化提供有力支持。
四、开源价值与未来展望
DynAlign 首次实现完全无监督的跨域分类自适应,零目标域标注、动态标签空间适应等特性,使其在医疗、遥感等标注困难领域极具应用潜力。此次开源为学术界和工业界提供了可落地的解决方案,随着基础模型与域适应技术的深度融合,DynAlign 有望在更多复杂场景中持续创新,引领动态场景下视觉理解技术的发展。
参考文献:Sun, H., Gong, R., Nejjar, I., & Fink, O. (2025). DynAlign: Unsupervised Dynamic Taxonomy Alignment for Cross-Domain Segmentation. Proceedings of the International Conference on Learning Representations (ICLR 2025).
(文:极市干货)