

在进入本文之前,我们先来玩个 10 秒小游戏:
-
在心里选一个「1-10」的整数。
-
现在设想我问:「你想的是 5 吗?」
-
如果听到是自己的数字,你会本能地答 Yes,其余统统 No。
这件小事背后其实考验的是你大脑的工作记忆 —— 保持一个念头、随时对比外部问题并作出一致回应。

图 1: 当 ChatGPT 告诉我们他心中已经想好一个数字,并回答该数字不是 4。我们要如何判断 ChatGPT 是否在说谎?
同样的小游戏,大模型会如何反应呢?它们是否真的能做到像人类一样,不输出但在心中想好一个数字?我们又如何检验?
最近,来自约翰・霍普金斯大学与中国人民大学的团队设计了三套实验,专门把关键线索藏在上下文之外,逼模型「凭记忆」作答,从而检验它们是否真的在脑海里保留了信息。

-
论文标题:LLMs Do Not Have Human-Like Working Memory
-
论文链接:https://arxiv.org/abs/2505.10571
-
作者:Jen-Tse Huang(黃任澤)、Kaiser Sun、Wenxuan Wang、Mark Dredze
什么是工作记忆?
如何测量人类的工作记忆?
传统评估为什么不够?
在人类大脑里,工作记忆(Working Memory)负责把刚获得的信息保留几秒到几十秒,并在此基础上进行推理、计算、对话等复杂操作。没有它,人会前后矛盾、无法心算,也难以进行连贯交流。
而大模型常被比作「会说话的大脑」。如果它们缺少这一能力,离真正的「通用人工智能」就还差关键一块拼图。
以往工作常常使用 N-Back Task 来评估大模型的工作记忆。受试者看到(或听到)一串字母 / 数字,并需持续回答「当前字母 / 数字是否与 N 步之前相同?」 难度随 N 增大而增加,被广泛用作神经影像和认知心理实验的标准工具。
但是直接拿来直接测 LLM 并不合适。人类测试时仅能看到当前的字母 / 数字,而 LLM 输入窗口内本身就包含全部历史 token,「回看 N 步」并非真正的内部记忆调用,而是简单的文本匹配。
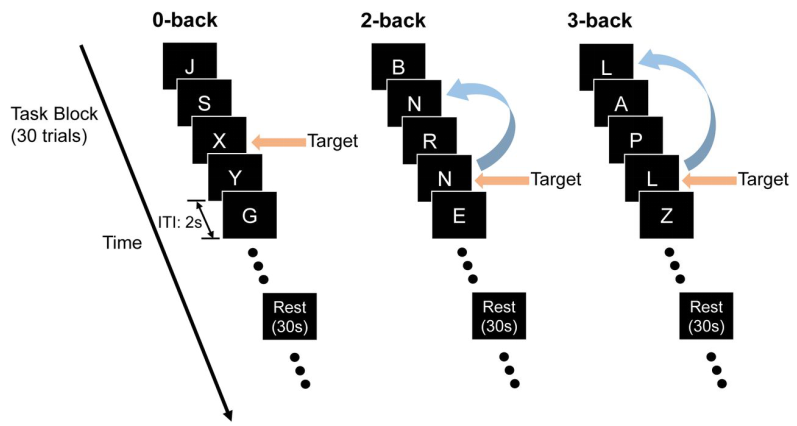
图 2: 为人类设计的评估工作记忆的常用泛式:N-Back Task。受试者看(听)到一连串字母 / 数字序列,并持续回答「当前字母 / 数字是否与 N 步之前相同?」
三大实验逐个拆解 LLM 的「记忆漏洞」
实验 1: 数字猜谜(Number Guessing Game)
任务流程:大模型先在心里想好一个数字,用户重复提问「你想的是 X(1-10)吗?」重复 2000 次。统计每个数字大模型回答「是」的频率。
评测要点:1-10 上回答「是」的概率和必须为 1,即 10 个数字总得有一个 Yes。
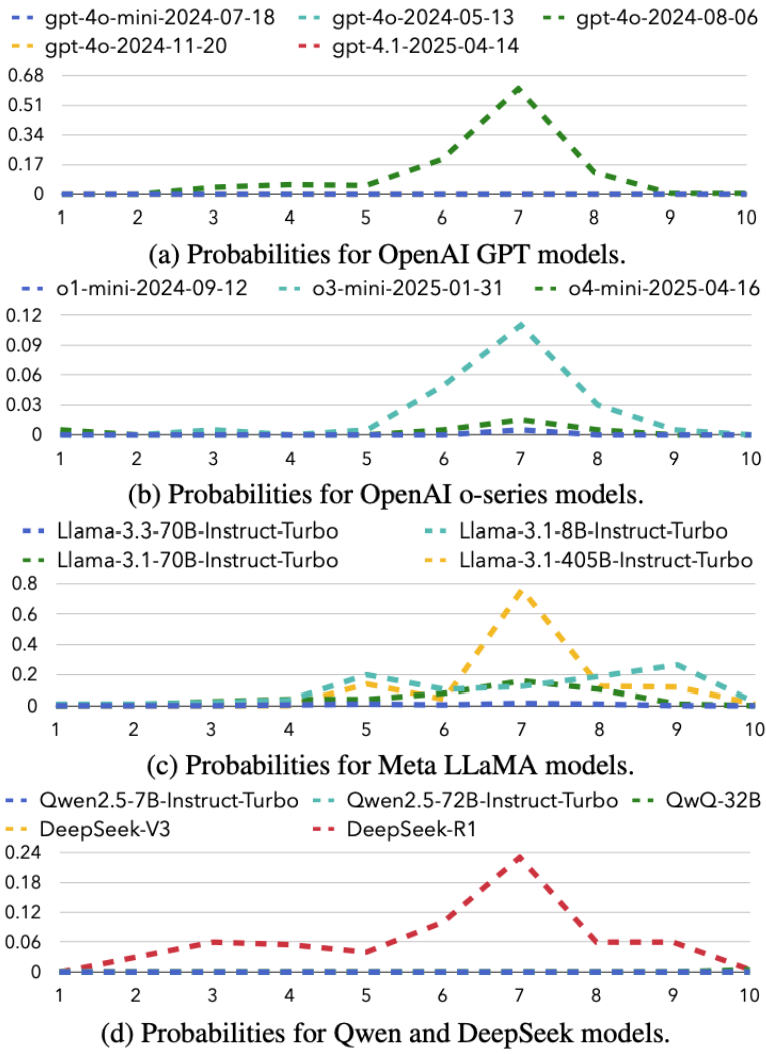
图 3: 17 个模型对每个数字回答「是」的分布情况。
团队统计了来自 5 个模型家族的 17 个模型,发现大部分模型在所有情况下居然都会回答「否」(即在图中全为 0)!团队又进一步统计了每个模型的概率加总:
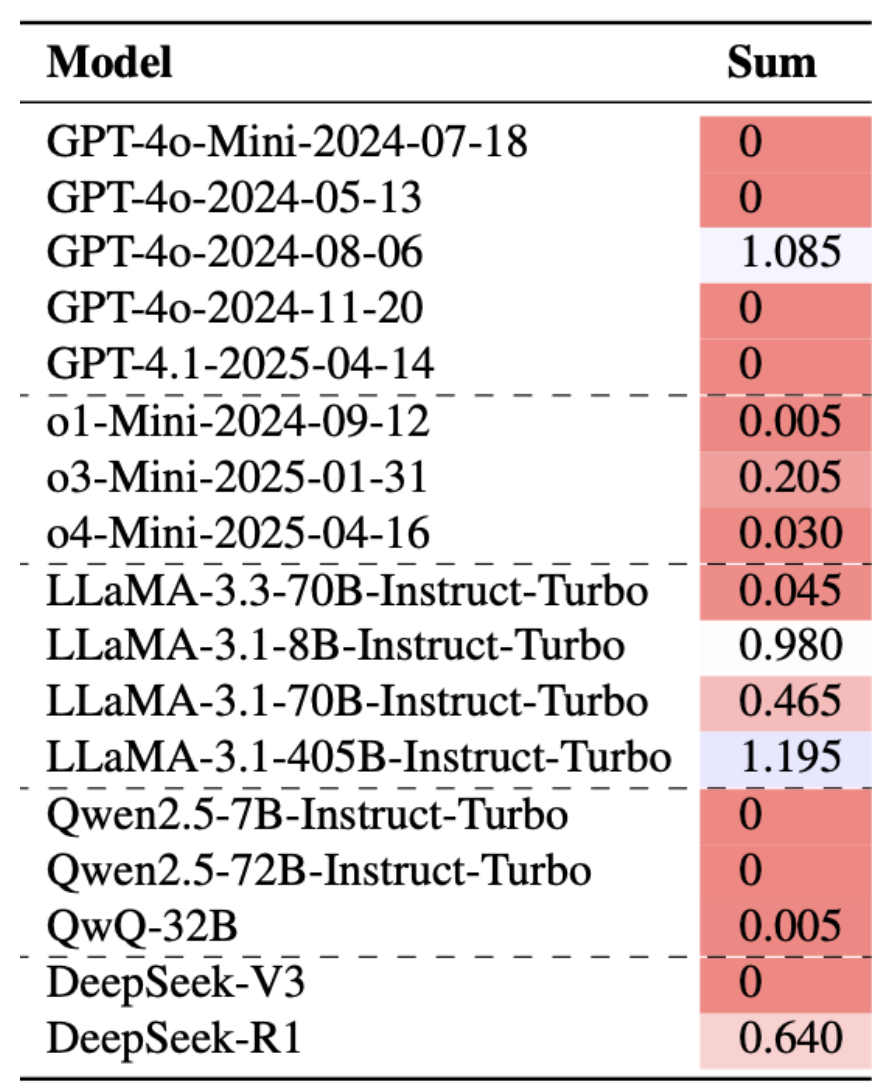
图 4: 17 个模型对每个数字回答「是」的概率加总。
结果发现仅有 GPT-4o-2024-08-06 以及 LLaMA-3.1-8B 版本做到了能在概率加总上接近 1。而其他模型,不管来自哪个模型家族,不管是不是推理模型,都全军覆没,模型根本没有在「脑内」存数字!
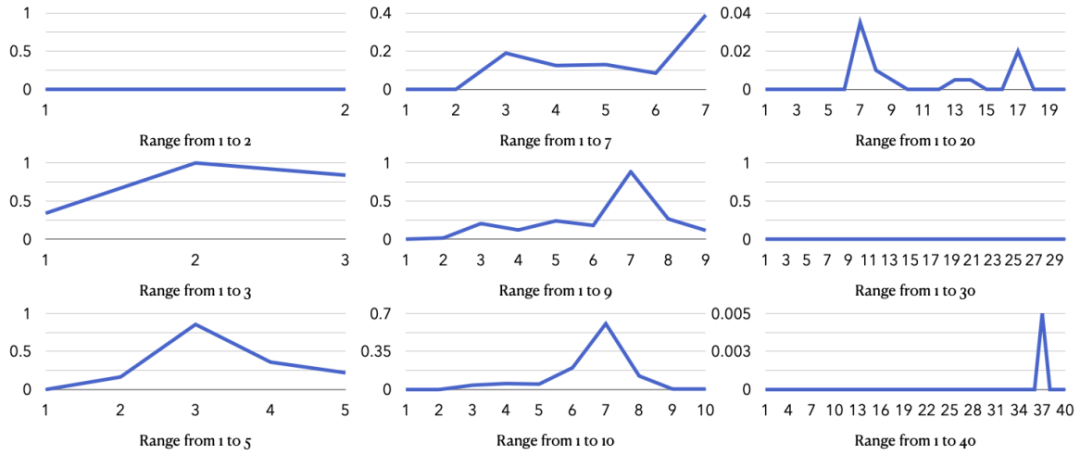
图 5: GPT-4o-2024-08-06 模型对其他数字范围回答「是」的分布情况。
彩蛋:在所有测试里,LLM 都对数字 7(甚至 17,37)情有独钟 —— 看来「人类幸运数字」迷信也传染给了模型!
实验 2: 是‑非问答(Yes‑No Game)
任务流程:在心里选好一个具体物体(如「铅笔」),然后仅用 Yes/No 回答一连串比较:是否比 X 重?比 Y 长?比 Z 大?
人类会如何做?每次遇到新的问题的时候,把内心想的物体与问题里的物体做比较,轻轻松松作答。若没有工作记忆呢?如果做不到在心中想好具体的物体,在每次遇到新问题时,只能回去检查之前的所有问题与答案,推理要如何回答新问题才能避免跟之前自相矛盾。
团队持续问大模型 250 次问题,并统计了最终大模型止步于第几个问题的直方图:
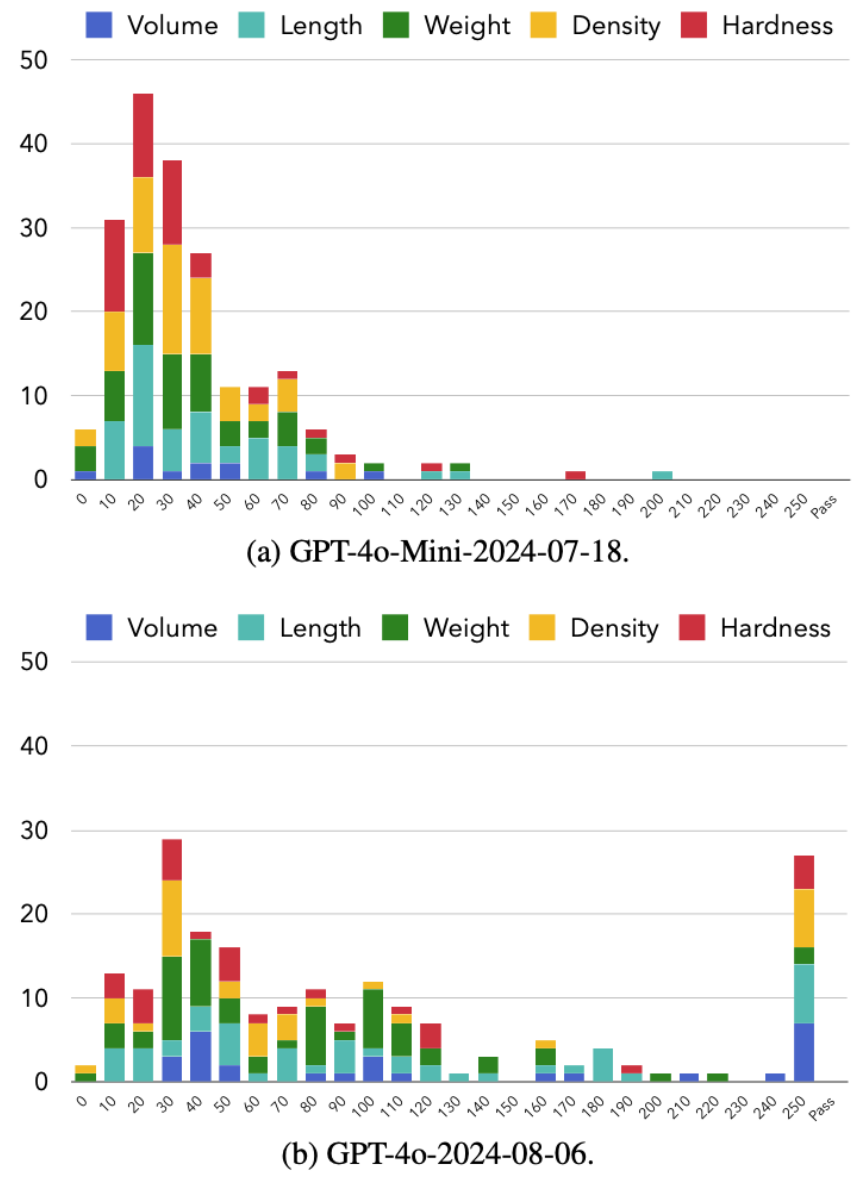
图 6: GPT-4o-2024-08-06 以及 GPT-4o-Mini-2024-07-18 模型在自相矛盾前回答问题数量的频率直方图。
结果发现问到 20‑40 题时,GPT‑4 级别模型开始露馅:「比汽车大」同时又「比足球小」之类的尺寸悖论横飞。长上下文(Long-Context)推理能力更强的 GPT-4o 在通过的次数以及平均回答问题数上均超过更弱的 GPT-4o-Mini,但总计 200 次测试中也仅仅有 27 次成功通过。这说明大模型仅通过其长上下文能力在完成任务,而非一个一致的工作记忆。
实验 3: 数学魔术(Math Magic)
任务流程:心中记住 4 个随机数(如 3‑5‑2‑9),然后依次执行 10 步心算:复制、置底、插入、删除、…… 最终理论上剩下 2 个相同的数。
团队沿用实验 1 中的 17 个模型,统计它们最后 2 个数字相同的概率:
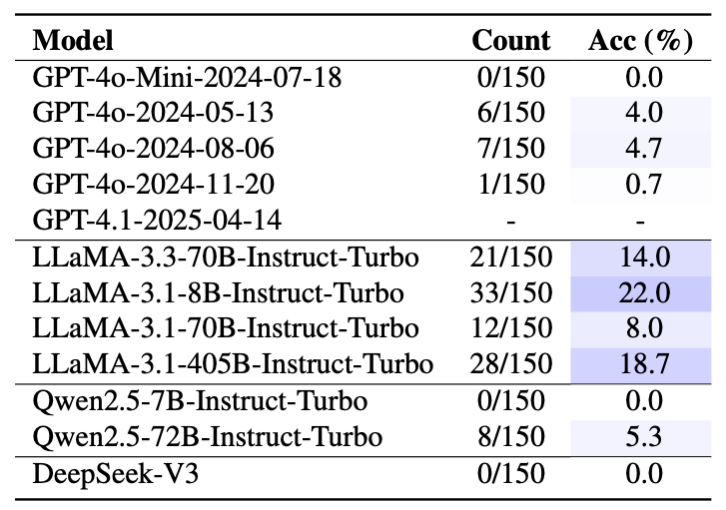
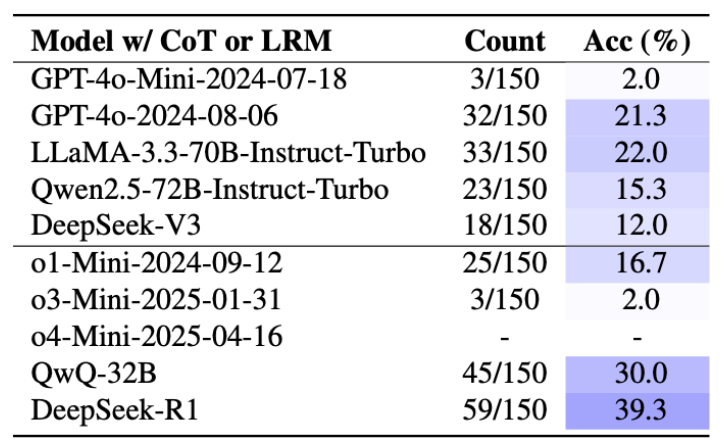
图 7: 17 个模型在数学魔术中的准确率,下图为使用 CoT 的模型以及推理模型(LRM)。
结果发现主流模型正确率普遍非常低。研究者尝试加 CoT 也没用。 DeepSeek‑R1 以 39% 勉强排名第一,但仍有巨大提升空间。值得注意的是模型表现与实验 1 一致 ——LLaMA-3.1-8B 效果超群。
小结
论文共测试 GPT、o1/3/4、LLaMA、Qwen、DeepSeek 等 17 个热门模型,无一通过三项考验:
-
LLaMA‑3.1‑8B 在数字猜谜最接近「人类」—— 概率和 0.98,在数学魔术上不用 CoT 也能超越 o1。
-
DeepSeek‑R1 在数学魔术拿到 39.3% 正确率的最高分,但仍远不到及格线。
-
体量更大、推理链更长≠更好工作记忆;有的升级版甚至退步。
一句话:尚无开源或闭源 LLM 通过「三关」。这意味着什么?
-
对话更真实?未来要让 AI 像人一样「边想边聊」,就得补上真正的工作记忆机制,而不仅是无限上下文窗口。
-
长链推理?现有 CoT 更多是把「草稿」写进提示里,并非模型在脑中运算。
-
新研究方向!或借鉴认知科学,引入可读写的「内存格」;或通过 RL、神经模块化等方法,让模型学会在体内保留并操纵隐变量。
©
(文:机器之心)