

本文第一作者为中国科学院大学的博士生陈若愚,主要研究可解释 AI 以及在训练推理中的落地应用。第二作者为新加坡国立大学的梁思源,主要研究可信 AI。主要合作者来自华为技术有限公司的刘势明和李茂森。通讯作者为中山大学的操晓春教授和中科院的张华研究员。
AI 决策的可靠性与安全性是其实际部署的核心挑战。当前智能体广泛依赖复杂的机器学习模型进行决策,但由于模型缺乏透明性,其决策过程往往难以被理解与验证,尤其在关键场景中,错误决策可能带来严重后果。因此,提升模型的可解释性成为迫切需求。
目前已有的解释方法,如 Shapley Value、Integrated Gradients、Attention、Gradient(如 Grad-CAM)以及 Perturbation 等,虽然在小规模模型中取得了较好的解释效果,但在面对多模态任务或大规模模型时,均存在不同程度的局限性,难以直接扩展或适用。因此,发展一种在大模型与小模型中均具有良好适应性的高效可解释归因方法具有重要意义。
近期,中国科学院、新加坡国立大学、华为技术有限公司与中山大学的联合研究在多模态物体级基础模型的可解释归因技术方面取得了重要突破,不仅能提高人类对模型的可理解性,也能高效解释什么输入因素导致了模型预测错误,以及如何对输入进行屏蔽从而修复模型决策。该成果获得了 CVPR 2025 三位审稿人的一致认可,并获得满分评分,最终被评为 Highlight Paper (387/13008, 2.98%)。

-
论文标题:Interpreting Object-level Foundation Models via Visual Precision Search
-
arXiv 地址:https://arxiv.org/pdf/2411.16198
-
GitHub 主页:https://github.com/RuoyuChen10/VPS
背景挑战
理解图像中的物体信息,如目标检测,是计算机视觉领域中的一个关键且持续的挑战,具有广泛的应用意义,包括自动驾驶等多个领域。
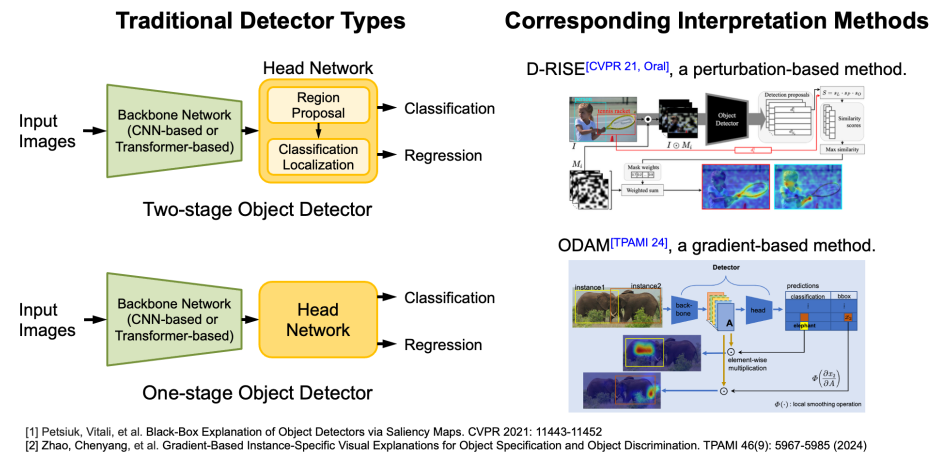
目前,已有方法用于解释目标检测模型,例如来自 Adobe 公司的基于 Perturbation 机理的 D-RISE 方法,以及来自香港城市大学的基于 Gradient 的 ODAM 方法。它们都适用于传统的单阶段以及双阶段目标检测器决策的解释。
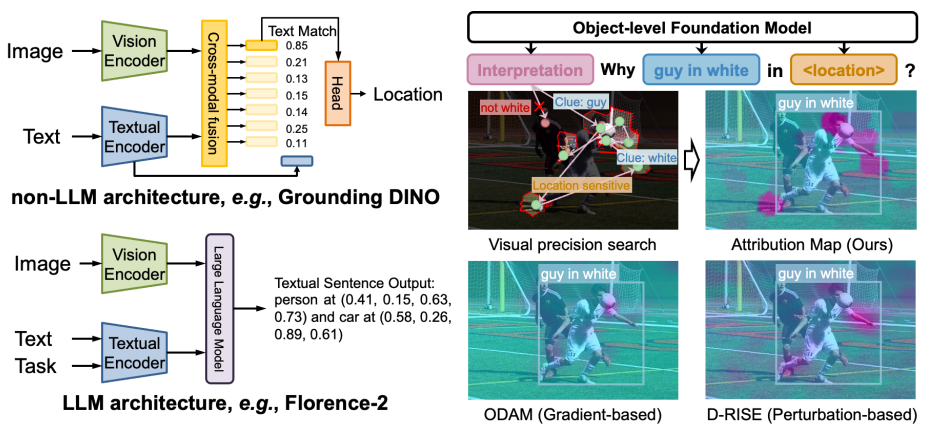
随着多模态预训练技术的发展,物体级基础模型(如 Grounding DINO 和 Florence-2)在视觉定位与目标检测等任务中得到广泛应用。然而,解释此类模型的决策机制变得日益复杂。一方面,模型参数规模不断扩大,另一方面模态数量的增加及其早期融合机制导致模态间交互更加复杂,从而使现有可解释归因方法面临显著挑战:(1)基于梯度的归因方法因视觉与文本的深度融合,难以提供精确的定位信息;(2)基于扰动的方法生成的显著性图中噪声较多,限制了其在细粒度解释任务中的表现。
为应对上述问题,团队提出了一种新的基于搜索的机理——视觉精度搜索(Visual Precision Search,VPS)方法,旨在通过更少的区域生成高精度的归因图。
问题建模
我们的目标是用尽可能少的区域实现更强的解释,因此我们将归因问题建模为基于子模子集选择的搜索问题。具体而言可以将输入稀疏化为有限的子区域集合,并选择其中一个子集,以达到最大化可解释的目的。为了评估子区域的可解释性,定义集合函数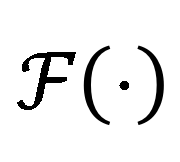 来判断给定区域是否是模型决策的关键因素。因此,目标是:
来判断给定区域是否是模型决策的关键因素。因此,目标是:
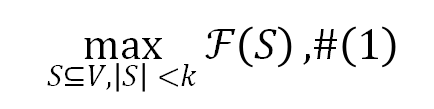
其中 表示子区域的最大数量。因此,问题的关键在于设计集合函数 并优化公式 1。
表示子区域的最大数量。因此,问题的关键在于设计集合函数 并优化公式 1。
方法概览
团队提出了一种用于解释物体级模型的视觉精度搜索方法。首先,需要对输入区域进行稀疏化处理。我们应用 SLICO 超像素分割算法将输入图像划分为 m 个子区域,即 。为了解决式 1 中的一个
。为了解决式 1 中的一个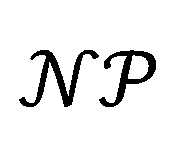 – 难问题,团队采用子模优化。接下来设计一个集合函数来评估可解释性分数,并对物体级任务中可解释区域的重要性进行排序。
– 难问题,团队采用子模优化。接下来设计一个集合函数来评估可解释性分数,并对物体级任务中可解释区域的重要性进行排序。

线索分数:可解释性的一个关键方面是使物体级基础模型能够在使用更少区域的情况下准确定位和识别物体。团队定义了线索分数为:
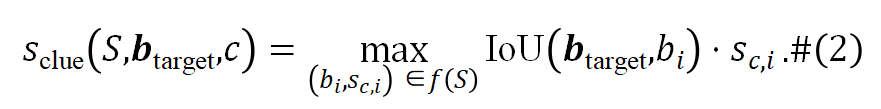
协作分数:部分区域可能具有显著的组合效应,即仅在与多个特定子区域联合时,才能对模型决策产生有效影响。为识别此类高度依赖交互的关键区域,团队引入了协同分数,用于衡量子区域在决策过程中的协同贡献:
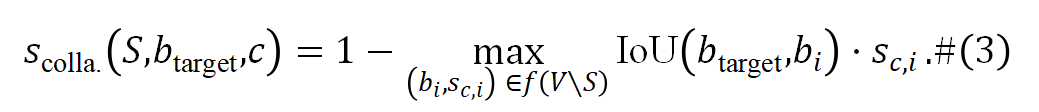
子模方程:上述分数被结合起来构建一个子模函数 ,如下所示:
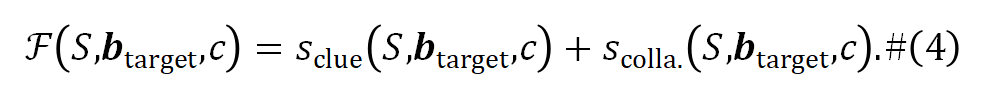
显著图生成:使用上述子模函数,应用贪心搜索算法对 V 中的所有子区域进行排序,得到一个有序子集 S。此外,对子区域进行评分是必要的,以便更好地解释每个子区域的重要性。团队通过边际效应评估两个子区域之间的显著差异,提出的视觉精度搜索算法的详细计算过程在算法 1 中进行了概述。团队也在论文中对方法的其适用性和理论边界进行了理论分析。

主要实验结果
忠实度分析
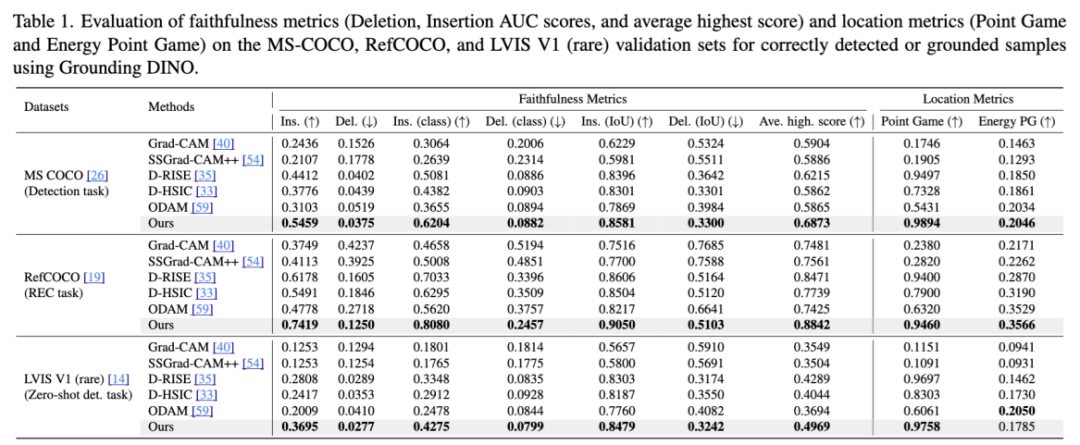
团队在多个物体级任务中验证了所提出的方法,使用 Grounding DINO 进行决策解释。表 1 展示了不同数据集上的可解释性结果,显示出本文方法的优越性能。在 MS COCO 的目标检测任务中,团队在 Insertion、Deletion 和平均最高分上分别超越 D-RISE 方法 23.7%、6.7% 和 10.6%。在 RefCOCO 的指代表达理解任务中,分别提升 20.1%、22.1% 和 4.4%。在 LVIS V1 的零样本目标检测任务中,团队在相应指标上分别提升 31.6%、4.2% 和 15.9%,达到了 SOTA 水平,进一步验证了提出方法极强的泛化能力与通用性。
如图 3 所示,ODAM 的显著性图呈现弥散状,D-RISE 的图则较为嘈杂,而本文的方法则清晰地突出显示了重要的子区域,捕捉到边缘和类别特征,增强了解释性。
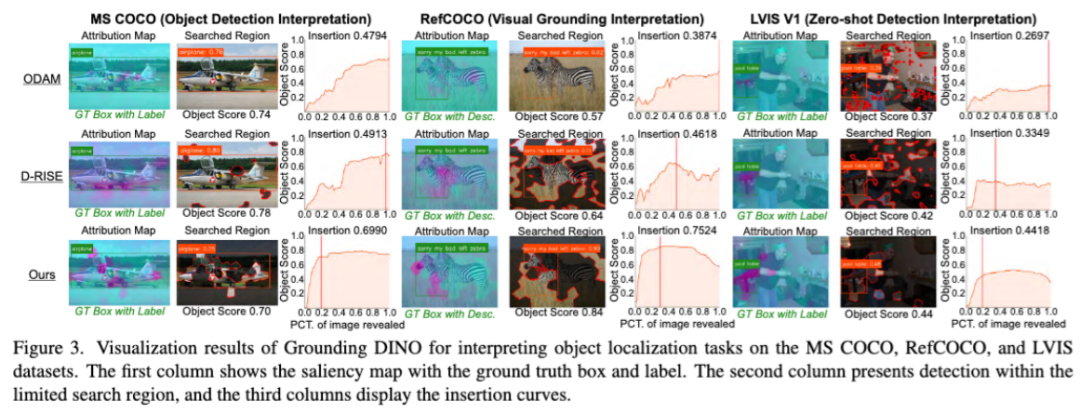
解释模型错误
在已知正确答案的前提下,本文的方法在解释物体级基础模型产生错误预测的原因方面,展现出其他现有方法所不具备的能力。团队在论文中定量的展示了本文方法大幅度超越基线方法,以下为可视化效果展示。
解释 REC 失败案例:图 5 展示了模型错误的解释,其中青色高亮区域表示由于视觉输入干扰导致的决策错误,这使得基础模型偏离了正确的轨迹。

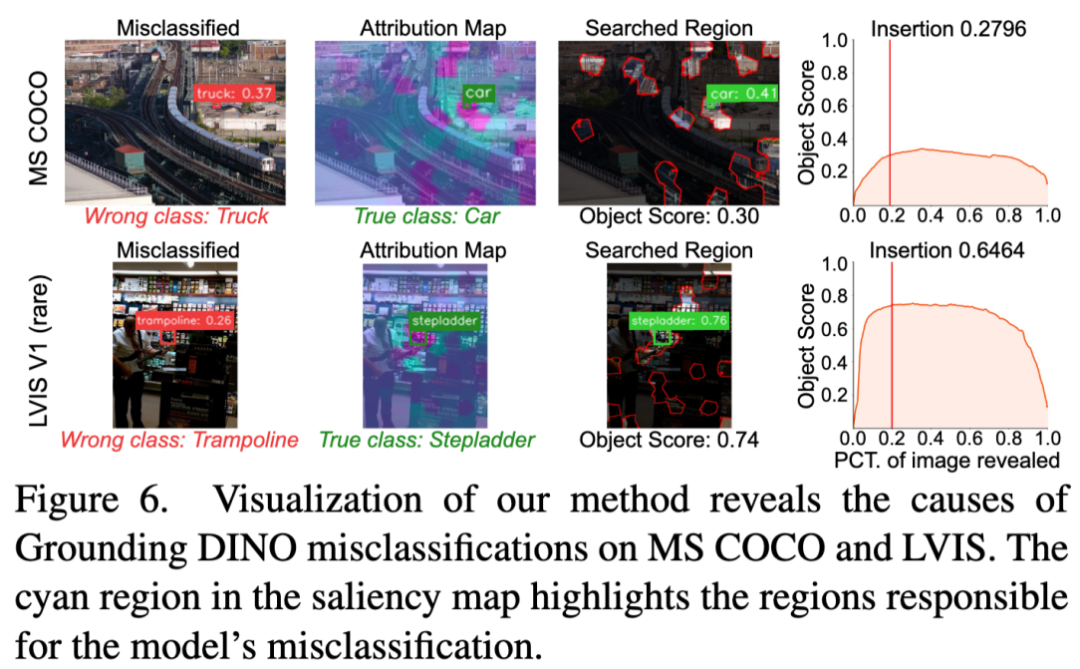
解释检测中分类错误:目标检测任务中常见错误是准确定位物体但分类错误,图 6 显示了物体周围的背景干扰了模型的决策,热力图中的青色区域突出显示了导致模型误分类的区域。通过改善模型并细化前景与背景之间的上下文关系,可能成为一个有前景的方向。
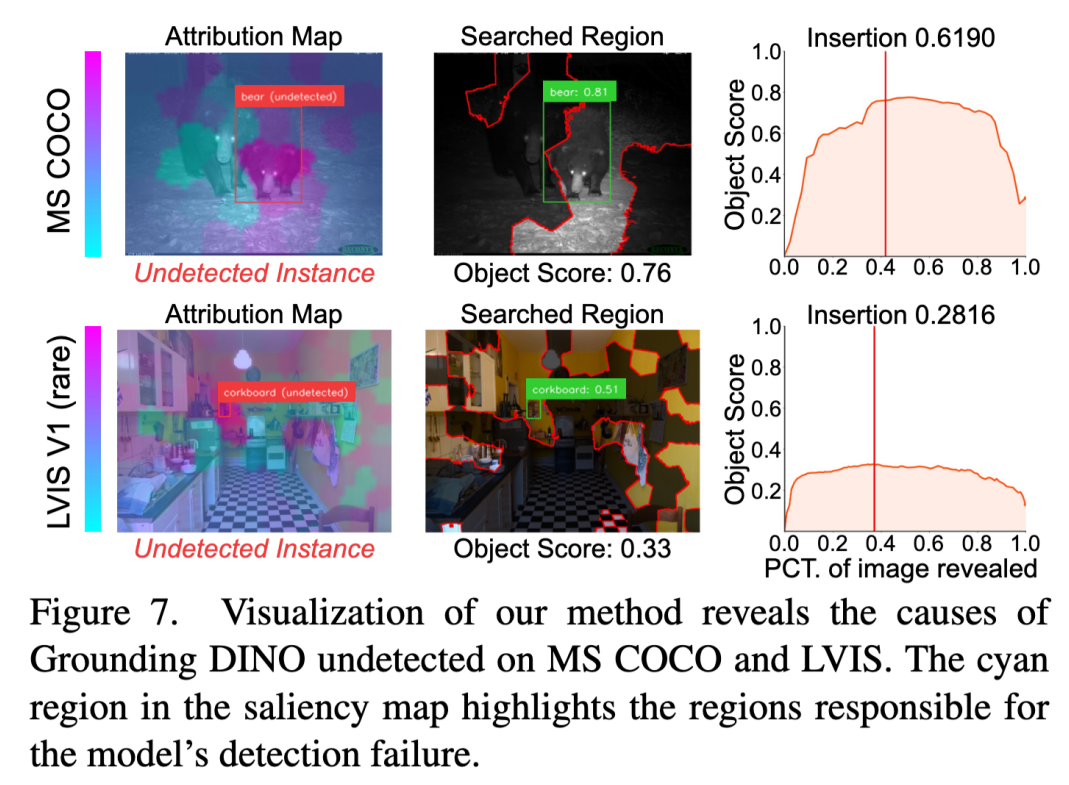
未检测错误解释:目标检测任务另一个常见的错误是对物体的置信度较低从而导致没有检测到物体。低置信度物体可能由模型的特征表示和干扰性输入因素共同导致。图 7 展示了本文方法对漏检样本的解释,揭示了错误可能源自难以区分相似物体(例如第一行的熊)和环境因素对检测的影响(例如第二行的软木板)。这些洞察揭示了当前模型的局限性,并为改进提供了方向。
小结与展望
团队提出了一种专门针对物体级基础模型的可解释归因方法,称为视觉精确搜索方法(Visual Precision Search),该方法引入了一种新的子模机制,结合了线索得分(clue score)和协作得分(collaboration score)。该方法通过搜索尽可能少的区域,增强了可解释性。通过在 RefCOCO、MS COCO 和 LVIS 上的实验,我们的方法在各种评估指标上提升了 Grounding DINO 和 Florence-2 的物体级任务可解释性,超过了现有的最先进方法。此外,我们的方法有效地解释了视觉定位和物体检测任务中的失败情况。
未来,团队将考虑将该可解释机理应用于实际任务,例如模型训练时提升模型决策的合理性;在模型推理时监控模型决策从而进行安全防护,提高模型的可靠性;或用可解释发现关键缺陷,以最小的代价修复模型。

©
(文:机器之心)