

L3 级别智能驾驶的关键:大算力、大模型、大数据。
端到端智能驾驶,正在沿着大模型 Scaling Laws 的道路狂奔。
上周三,全球首款 L3 级算力「AI 汽车」小鹏 G7 正式亮相,其首发搭载的三颗自研图灵 AI 芯片,超过 2200TOPS 有效算力,本地部署的 VLA+VLM 模型等特性引发了关注。
基于超高端侧算力,小鹏 G7 行业首发了智驾大脑 + 小脑 VLA-OL 模型,第一次给智能辅助驾驶加入了「运动型大脑」的决策判断能力。

小鹏 G7 同时首发了 VLM(视觉大模型),它可以作为车辆理解世界的 AI 大脑,将会是人与汽车交互的新一代入口。作为车辆行动的中枢,可以指导智能辅助驾驶和智舱等整车能力,未来还可以实现本地聊天、主动服务、多语言等功能。
同样是在上周,美国纳什维尔举行的全球计算机视觉顶会 CVPR 2025 上,小鹏作为唯一受邀的中国车企分享了其自动驾驶基座模型的研发进展。

小鹏自去年 5 月就宣布了量产端到端大模型上车,并构建了从算力、算法到数据的全面体系。今年 4 月,小鹏官宣正在研发下一代自动驾驶基座模型。今年的 CVPR 上,小鹏首次对外晒出了其世界基座模型的技术细节。
小鹏世界基座模型负责人刘先明展示了基座模型在真实城市环境复杂路面的控车能力。在没有任何规则代码托底的情况下,AI 面对复杂路口可以实现正确变道绕行,避开侵入车道的大货车,再避让逆行的自行车:

在经过施工区域前,它能提前绕行避障:

还可以完成一连串的复杂动作:直行道上,前方大车切出后,看到临停车变道绕行;遇到突然横穿马路的电动摩托车,成功避让;左侧忽然有一辆大货车加塞,减速灵活应对。

尽管只是在后装算力的车辆上用早期版本的模型进行测试,小鹏自动驾驶基模已经展现出令人惊叹的智能和拟人水平。
今年的 CVPR 大会上,与小鹏共同登台的是 Waymo、英伟达、UCLA、图宾根大学等工业界、学术界的自动驾驶顶流。看起来,小鹏的智能驾驶已走到了业界领先的位置,其智能驾驶体系开始在主流 AI 圈层「上桌吃饭」。
从端到端到世界模型
开启智能驾驶下一个 Level
过去几年,在智驾和智能座舱上,我们都见证了不少新功能的上线,但不论是城市范围的智能驾驶,还是让汽车有了「人的温度」的座舱语音助手,其进步都往往体现在细节能力的横向扩展,从智能化的高度来看,纵向的提升却不明显。
ChatGPT 引爆的新一轮 AI 技术跃进,让基于端到端的全新技术范式,逐渐成为了驾驶通向 L3、L4 智能驾驶的敲门砖。
整个智能驾驶行业在 L2 阶段已经停留太久。小鹏认为,「大算力 + 大模型」时代的到来,已为整个行业的 L3 进阶铺好了基石。
小鹏汽车董事长何小鹏在前几天的 G7 新车发布会上指出,迈向 L3 级算力 AI 汽车需要满足两个前提条件:本地有效算力大于 2000TOPS,在本地部署 VLA+VLM 大模型。为此,他们很早就开始布局自动驾驶基座模型赛道,并构建了从算力、算法到数据的全面体系,在新方向上一直保持着领先的身位。
在 CVPR 2025 的自动驾驶研讨会 WAD(Workshop on Autonomous Driving)上,刘先明发表了题为《通过大规模基础模型实现自动驾驶的规模化》(Scaling up Autonomous Driving via Large Foudation Models)的演讲,介绍了小鹏自研业界首个超大规模自动驾驶基座模型的历程,还披露了其在模型预训练、强化学习、模型车端部署、AI 基础设施搭建方面的一系列探索。
在发布 G7 时,小鹏表示「大算力 + 物理世界大模型 + 大数据」将共同定义未来「AI 汽车」的能力上限,其中的「物理世界大模型」正是刘先明团队研发的自动驾驶基座模型。
对于自动驾驶来说,如何能够保证行驶的安全、稳定,让 AI 系统在出现「前所未见」情况时能够做出正确决策,一直是技术的最大挑战。基于世界基座模型的新一代架构,为业界带来了希望。
今年 4 月,小鹏汽车首次披露了自身的下一代自动驾驶基座模型。该云端基础模型参数规模达到 720 亿,目前训练数据已超过 2000 万条视频片段(每条时长 30 秒)。它以大语言模型为骨干,使用海量优质多模态驾驶数据进行训练,具备视觉理解、链式推理(CoT)和动作生成能力。通过强化学习(RL)后训练,它可以不断自我进化,逐步发展出了更全面、更拟人的自动驾驶技术。
世界基座模型的一大优势是具备 CoT 能力。就像 DeepSeek R1 在回答问题时展示的「强推理」过程一样,自动驾驶的 AI 模型也能在充分理解现实世界规律的基础上,像人类一样进行相对复杂的常识推理,做出行动决策,如输出打方向盘、刹车等控制信号,实现与物理世界的交互。
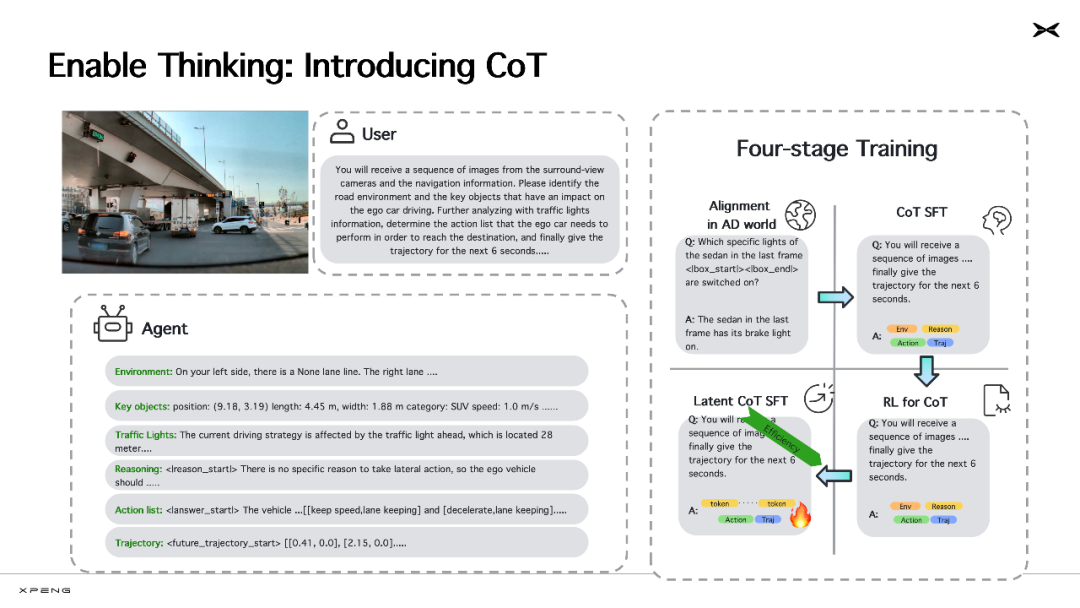
这大幅提升了自动驾驶的能力。现在 AI 在遇到复杂、危险或特别少见(训练时未见过)的场景时,能够进行条理清晰的逻辑推理,正确分析道路交通环境,关注到对自车行为有影响的关键目标、交通信号灯等指示,并对自身下一步决策作出推理,随后形成动作规划,生成下一步的轨迹。
如果说传统的自动驾驶模型是负责「开车」这项运动的「小脑」,基于大语言模型和海量优质数据训练的新一代基座模型,则是同时具备开车和思考能力的「大脑」—— 它能像人类一样主动思考并理解世界,丝滑地处理训练数据中未见过的长尾场景(corner case),相比上代基于大量内嵌规则的智能驾驶更加安全,更具可解释性,驾驶风格也更加拟人化。
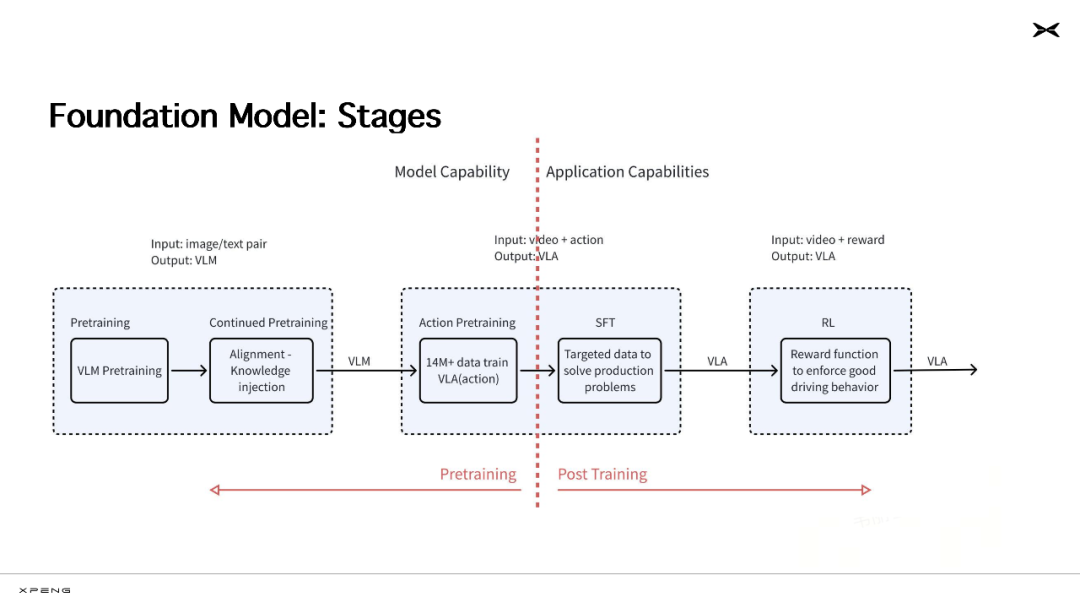
有了「云端超级大脑」,接下来的挑战,就是让它在车辆端侧高效运行。
由于车端算力的限制,能够部署上车的 AI 模型必须经过剪枝、蒸馏等方法进行压缩,目前业界主流的车端模型参数一般在几百万到十亿级别。如果比照车端算力的容量直接训练小模型,模型的性能上限会受到极大限制,更无从实现 CoT 等能力。
小鹏选择了蒸馏的技术路线,先在云端「不计成本」地训练大规模基座模型,再通过蒸馏的方式压缩以适配车端算力,通过知识迁移的方式最大限度保留基模核心能力,帮助车端模型提升性能。
「云端基座模型 + 强化学习的组合,是让模型性能突破的最好方法。云端基座模型好比一个人天生的智商,强化学习好比能力激化器,用来激发云端基座模型的智力潜能,提高基模的泛化能力,」刘先明表示。
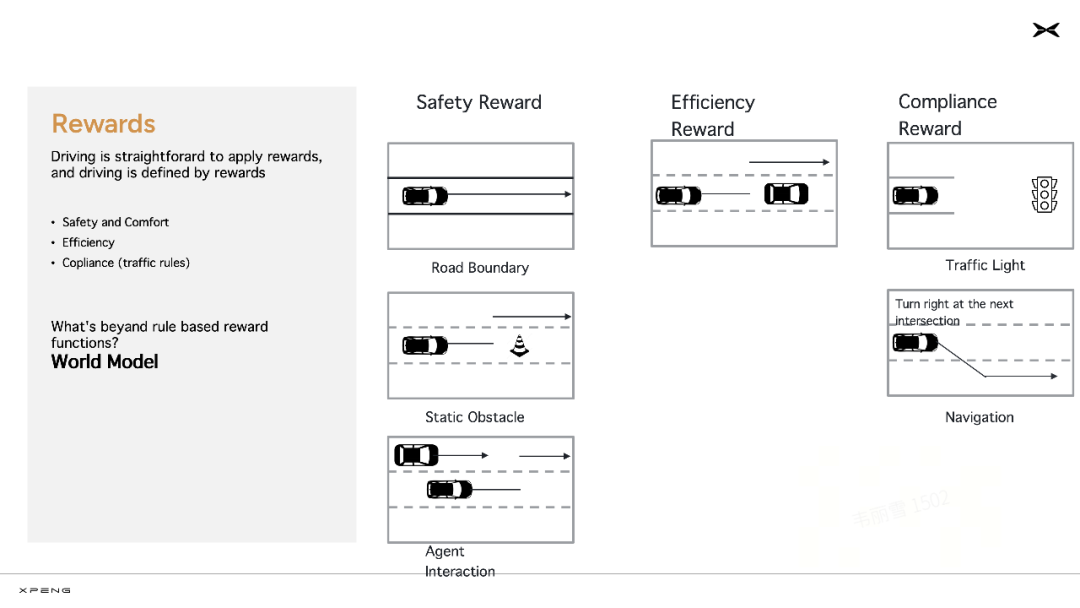
在基座模型完成预训练、监督精调(SFT)之后,模型会进入强化训练阶段。小鹏开发了自己的强化学习奖励模型(Reward Model),主要从安全、效率、合规三个方向提升模型能力。
「这也是人类驾驶行为中的几个核心原则,遇到不认识的障碍物要绕行,这是为了安全;路上遇到特别慢的车,适时变道超车,可以提高效率;按照红绿灯、车道线、道路标牌的指示开车,这是合规,」刘先明表示。
在这个阶段,小鹏以往辅助驾驶能力的研发经验也被用于设计强化学习的奖励函数,转化成了新的生产力。
为了进一步提升自动驾驶的能力,提升泛化性,自动驾驶系统还需要接入世界模型。
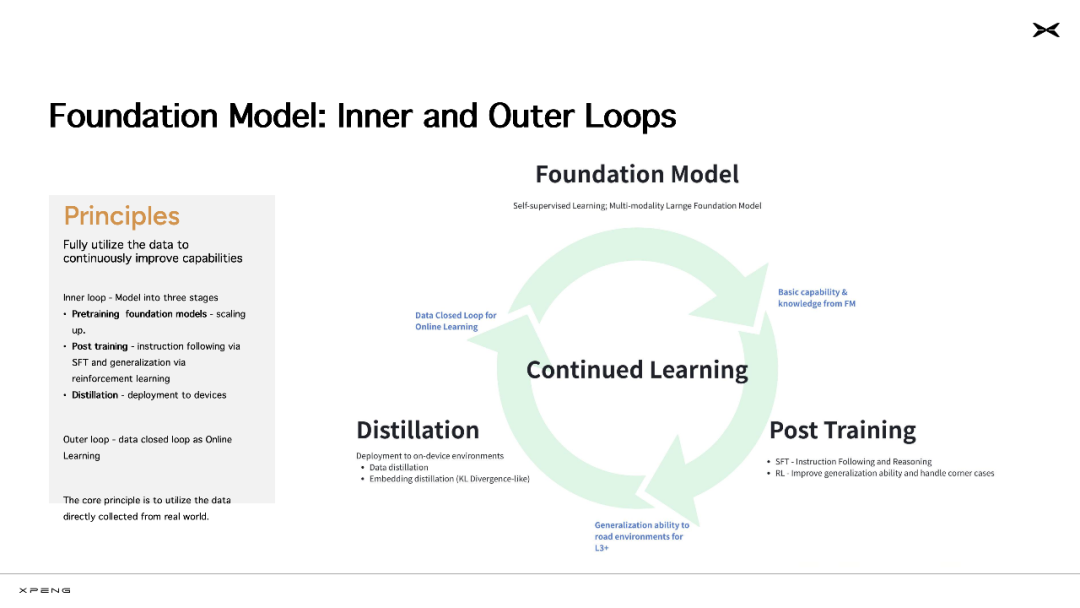
小鹏自动驾驶团队正在开发世界模型(World Model),未来计划将其用作一种实时建模和反馈系统,基于动作信号模拟出真实环境状态,渲染场景,并生成场景内其他智能体(也即交通参与者)的响应,从而构建一个闭环的反馈网络,帮助基座模型进行强化学习等训练。
也就是说,小鹏训练好之后的基座模型并不是静态的,它会持续学习、不断迭代提升。
小鹏汽车的基座模型迭代过程分成内、外两个循环,内循环是指包含预训练、后训练(包括监督精调 SFT 和强化学习 RL)和蒸馏部署的模型训练过程;外循环,是指模型在车端部署之后,持续获取新的驾驶数据和用户反馈,数据回流云端,继续用于云端基模的训练。
说到世界模型,最近越来越多的 AI 研究者已经把它摆在了「通向 AGI 方向」的位置。图灵奖得主 Yann LeCun 认为,世界模型是 AI 系统用于模拟和理解外部世界运作方式的内部模型。基于世界模型,AI 系统可以不断适应新的动态环境,并高效地学习新技能。
Google DeepMind 近日提交的一份研究甚至证明:如果一个大模型智能体能够处理复杂、长期的任务,那么它就一定学习过一个内部世界模型,越是通用的 AI,就学习得越精确。大模型和世界模型的发展,或许是殊途同归。
小鹏在智能驾驶上的实践,可以说提前判断到了正确方向。未来,小鹏还将用这套技术赋能 AI 机器人、飞行汽车等设备。
转型 AI 公司
验证自动驾驶的 Scaling Laws
如果说端到端、世界模型是智能驾驶通向下一阶段的方向,那么 AI 规模的扩展则可以说是验证这一路线的核心标尺。
过去两年半时间里,AI 性能的提升很大程度上得益于规模的扩展。大模型第一性原理扩展定律(Scaling Laws)不断获得验证,已经让 AI 在很多领域中获得了接近甚至超越人类的能力。
进入大模型时代的自动驾驶又是如何?
近日,Waymo 使用大量内部数据进行了一项全面的研究,发现与大语言模型(LLM)类似,自动驾驶过程中 AI 对于运动预测的质量也遵循训练计算的幂律 —— 模型参数规模扩大、训练数据量的扩展、大规模的并行计算对于提高模型处理更具挑战性的驾驶场景的能力来说至关重要。

图片来自 Waymo。
其实小鹏此前在构建智驾系统时,也清晰地观察到了 Scaling Laws 显现。他们是大模型浪潮以来,行业内首个基于大规模量产车队和海量真实用户数据,对自动驾驶 Scaling Laws 做出验证的研发团队。
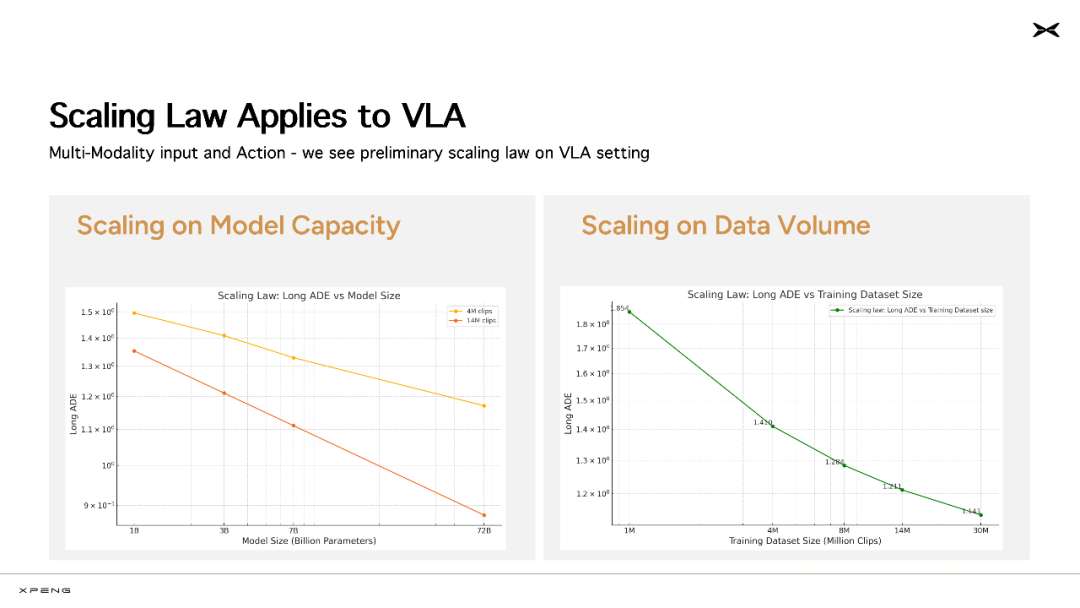
事实上,小鹏很早就启动了向 AI 公司转型的进程。
小鹏自 2024 年开始布局 AI 基础设施,建成了国内汽车行业首个万卡智算集群,用以支持基座模型的预训练、后训练、模型蒸馏、车端模型训练等任务。这套从云到端的生产流程被称为「云端模型工厂」,拥有 10 EFLOPS 的算力,集群运行效率常年保持在 90% 以上,全链路迭代周期可快至平均五天一次。
如此算力规模和运营效率,堪比头部 AI 企业。
从行业的视角看,我们或许可以从特斯拉 FSD 领先的能力中窥见大规模 AI 基础设施的重要性。但在造车新旧势力中,目前拥抱 AI、敢于投入大量资源的玩家尚不多见。
这其中有机遇,必然也意味着挑战。刘先明表示,比起大语言模型,自动驾驶基座模型的研发更复杂、更具挑战性。自动驾驶的训练数据模态更多、信息量多出几个数量级,对于自动驾驶任务来说,所有技术都要基于对物理世界的认知进行从头验证。
敢于转型 AI 公司的玩家,必须要做到长期大规模投入,并发展出完善、高效率的技术栈。
在 CVPR 大会现场,小鹏揭秘了两个核心数据:
-
小鹏的云上基模在训练过程中已处理超过 40 万小时的视频数据;
-
其流式多处理器的利用率(streaming multiprocessor utilization)已达到 85%。
前者验证了小鹏的数据处理能力,后者是指 GPU 的核心计算单元的运行效率,是评判计算资源使用效率的重要指标。据业内人士评估,85% 的利用率数字基本摸到了行业天花板,在大模型圈内也属于顶尖水平。
刘先明透露,小鹏对标业内领先 AI 公司的标准,从头搭建了自己的数据和 AI 基础设施,有充分的信心做到行业前列。他从云端模型训练和车端模型部署两个层面,分别介绍了自动驾驶团队提升模型训练效率的方法。
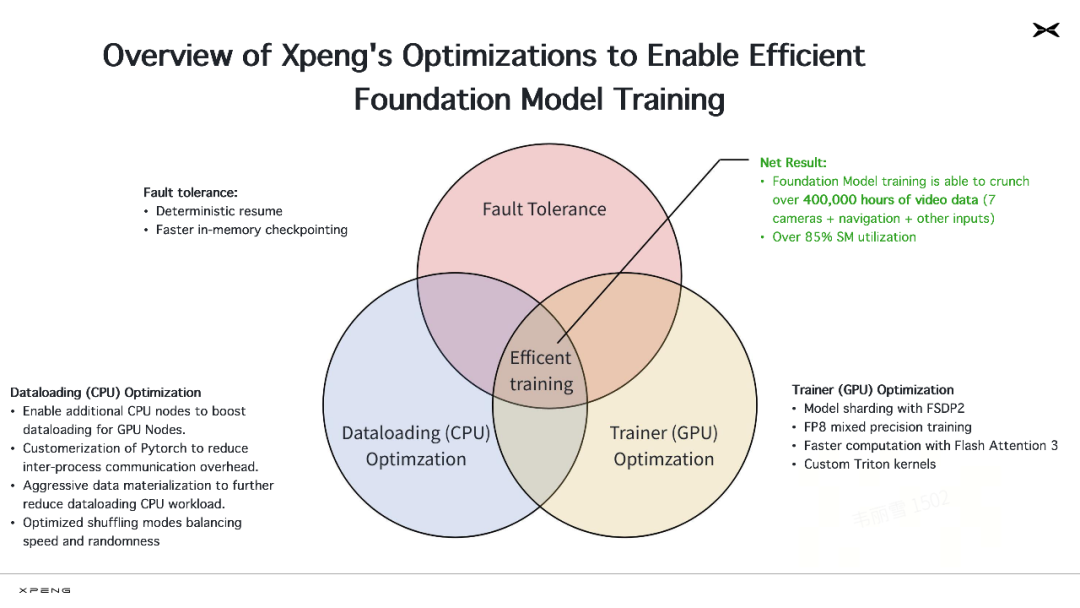
在模型训练层面,研发团队分别对 CPU、GPU 的效率、容错性等方面进行联合优化,着重解决数据加载、并行通信等瓶颈问题。在 CPU 的利用上,团队启用了额外 CPU 节点提升数据加载能力,对 PyTorch 进行定制化,采取了激进的数据物化策略,并通过优化打乱模式,在速度与随机性之间取得了平衡。
在 GPU 计算资源的利用上,研发团队使用 FSDP 2 实现了模型分片,使用 FP8 混合精度进行训练,自定义了 Triton 内核,并引入了 Flash Attention 3 加快计算速度。
到了模型部署层面,小鹏为 AI 大模型定制的「图灵 AI 芯片」、全链路调优的优势进一步显现。在 G7 新车落地的过程中,模型、编译器、芯片团队针对下一代模型开展联合研发,比如定制 AI 编译器以最大化执行效率,协同设计硬件、量化友好的模型架构,确保软硬件充分耦合,最终「榨干」了车端算力。
「车端计算负载的重要来源是输入 token 数量。以配备 7 个摄像头的 VLA 模型为例,每输入约两秒视频就会产生超过 5000 token。我们一方面要压缩输入中的冗余信息,降低计算延迟。另一方面要确保输入视频的长度,以获得更丰富的上下文信息,」刘先明介绍道。
小鹏团队为此专门设计了针对 VLA 模型的 token 压缩方法,可在不影响上下文长度的情况下,将车端芯片的 token 处理量压缩 70%。
从「软件开发汽车」走向「AI 开发汽车」
从 AI 基础设施做起,进行全链路优化,打造高度自研的体系,这条路线或许会成为未来自动驾驶技术向上突破的范式。
更长远地看,在转型成为 AI 公司之后,逐渐理解世界的通用化模型不仅能服务自动驾驶,也能够为更多全新的自动化能力打开想象空间。或许正如黄仁勋所说的,在不远的未来,AI 芯片的集群将不再是芯片,而会化身为「思考机器」,实现自我思考、自我进化。
小鹏 G7 发布时,何小鹏就透露道,就在今年内,G7 还会拥有「极其重大」的新功能。
期待 AI 进化的下一个节点。
©
(文:机器之心)