

AntResearchNLP团队 投稿
量子位 | 公众号 QbitAI
“边看边画,边画边想”,让大模型掌握空间思考能力,结果直接实现空间推理任务新SOTA。
来自蚂蚁技术研究院自然语言组联合中科院自动化所和香港中文大学开源ViLaSR-7B。

它在包括迷宫导航、静态图像理解和视频空间推理等5个基准上平均提升18.4%。
在李飞飞等知名学者提出的VSI-Bench上更是达到了与Gemini-1.5-Pro相当的45.4%水平,全面超越现有方法。
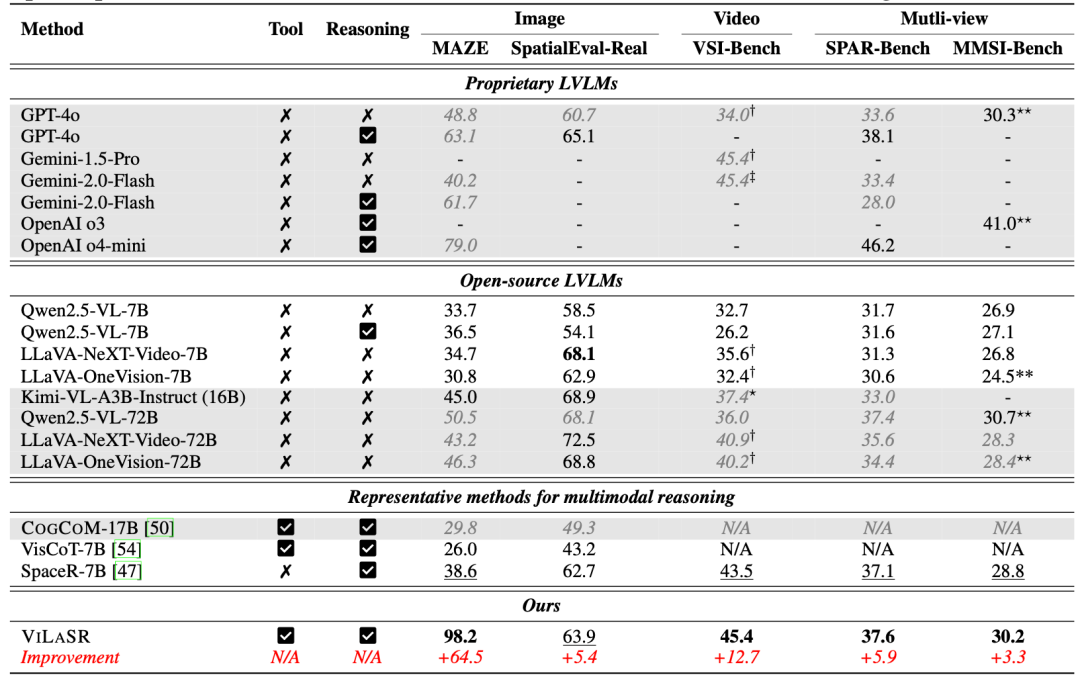
△主实验结果
更重要的是,大量案例研究表明,模型确实掌握了类似人类的空间推理策略和反思能力,朝着真正的视觉智能迈出了重要一步。
他们设计了三阶段训练框架,来训练这种推理能力——
首先通过冷启动训练建立基础的视觉操作能力,继而利用反思拒绝采样筛选高质量的推理路径,最后通过强化学习直接优化任务目标。
具体来看看~
两种推理范式
在文本任务突破后,视觉推理成为当下机器推理的一大热点。视觉推理指的是机器能够像人一样,通过分析单张或多张(连续)图中的物体、场景布局和空间关系来进行视觉理解和逻辑判断。
今年4月,OpenAI发布的o3和o4-mini模型在视觉推理领域取得重大突破。这两个模型采用“Thinking with Images”的推理范式,能够在文本形式的推理过程中主动进行图像操作(如裁剪、缩放、旋转等),并将操作后的图像重新输入模型进行下一步推理。在MMMU等多个视觉推理基准测试中,o3模型的表现大幅超越了此前的最好成绩,显示了这种范式的巨大潜力。
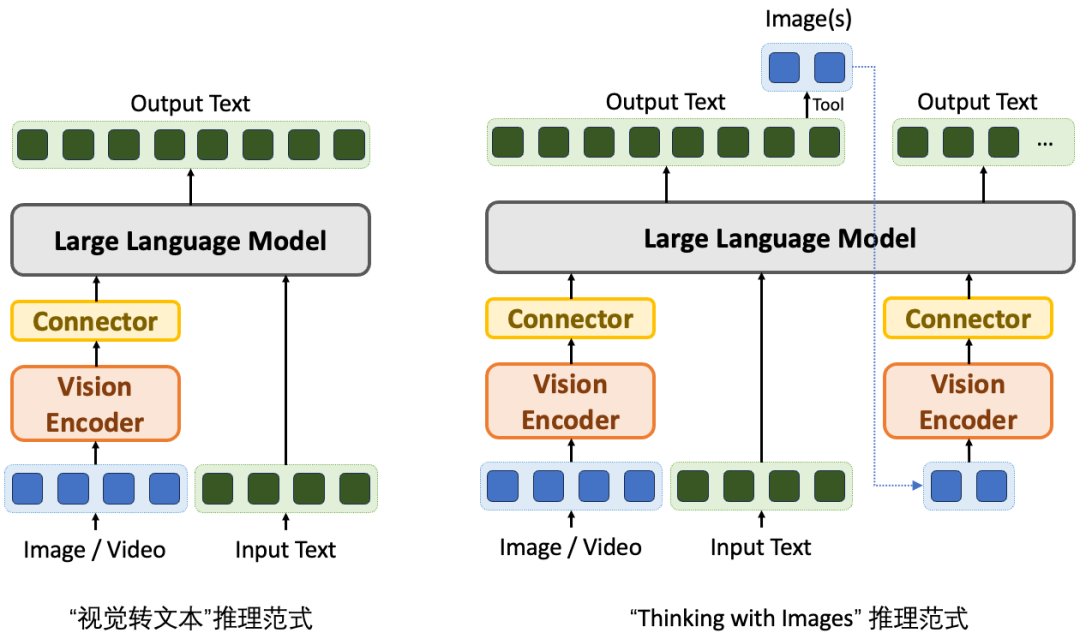
△两种视觉推理范式
视觉推理为什么需要“Thinking with Images”呢?
与o3/o4-mini不同,传统视觉语言模型(Large Vision-Language Models, LVLMs)往往采用“视觉转文本”推理范式。该范式仅仅将图像信息作为辅助输入,通过视觉编码器将其压缩为token序列并对齐到语言空间,随后交由LLM进行纯文本推理。
尽管去年6月份一篇被Ilya点赞的论文《The Platonic Representation Hypothesis》指出视觉和语言表示会随着模型规模扩大而自然地趋于一致,但在实践中这种对齐存在诸多问题。
一方面,由于训练数据的局限性和视觉编码器能力的限制,这种压缩和对齐过程不可避免地会丢失大量关键的细节信息和时空信息。这些信息一旦在初始对齐阶段丢失,就无法在后续的纯文本推理中恢复。
另一方面,视觉数据中往往包含大量与任务无关的背景细节,特别是在视频等多帧场景中存在大量冗余信息。如果盲目增大模型规模来保留更多信息,不仅会耗费大量计算资源去处理这些无关信息,还可能导致模型过度关注噪声而影响推理效果。
如图所示,“视觉转文本”推理范式的局限在具体任务中表现得尤为明显 -在迷宫导航时容易混淆方向、在多视角推理时难以建立物体间的时空关联等。

△“视觉转文本”推理的局限性
当下,视觉推理正经历从“视觉转文本”到“Thinking with Images”的范式转变。
事实上,“Thinking with Images”并非全新概念。
例如,CVPR 2023的最佳论文VisProg就提出了一种无需训练的提示方法,通过让大模型生成Python程序来调用视觉工具,践行了这种用图像思考的理念。蚂蚁技术研究院在EMNLP 2024的VisualReasoner工作也率先提出在推理过程中主动引入视觉操作,通过编辑和生成新的视觉线索来增强模型的感知能力。更重要的是,该工作设计了一种数据合成方法,能自动生成大量包含多步视觉推理过程的训练数据,首次实现了将这种推理能力原生注入到模型参数中。
这些探索为解决传统视觉到文本转换范式中的信息损失问题开辟了新的方向。
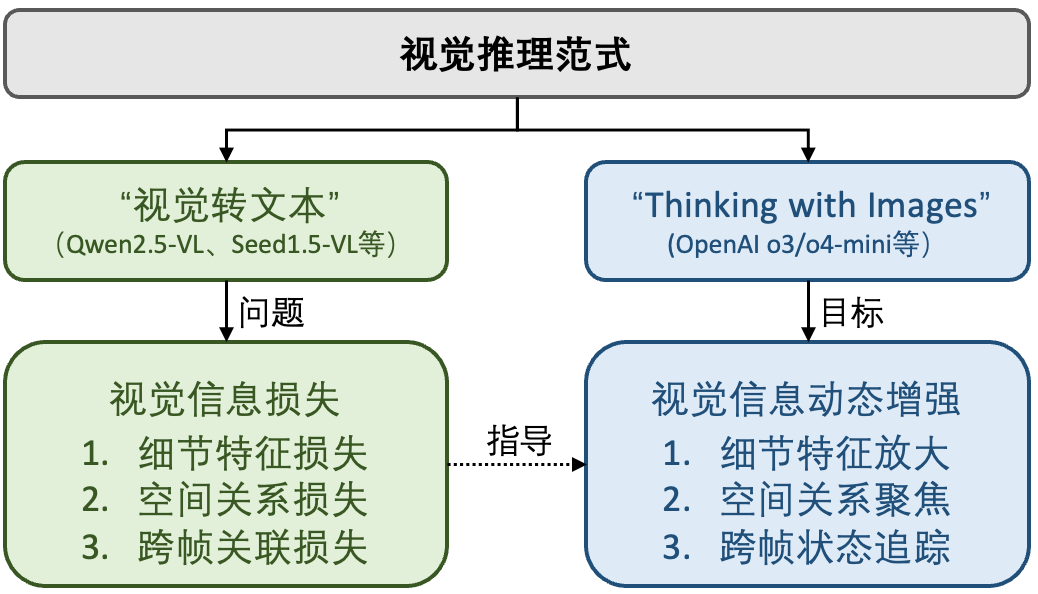
△两种推理范式对比
在“Thinking with Images”的大框架下,蚂蚁技术研究院自然语言组联合中科院自动化所和香港中文大学重点关注视频或多图场景下的空间推理问题,试图解决当下视觉推理工作中空间关系增强不足以及跨帧追踪能力受限等问题。
为此,团队开源了ViLaSR-7B(Vision-Language Model for Spatial Reasoning)模型。该模型通过创新性的“Drawing to Reason in Space”范式,让LVLMs能够像人类一样“边画边想”:通过在视觉空间中绘制辅助标注(如参考线、标记框等),引导视觉编码器捕捉关键的空间关系,从而在视觉token的embedding表征中保留更丰富的空间信息,有效缓解了传统“视觉转文本”推理范式中的信息损失问题。这种交互式的视觉推理方式模拟了人类在解决空间问题时的思维过程,增强了模型的空间感知能力。

△“Drawing to Reason in Space”示例
技术方案:Drawing to Reason in Space
该框架让模型能够在每一步推理中操作单张或多张图像:通过选择关键帧、跨帧比较、绘制边界框和辅助线等方式来构建视觉线索,从而聚焦特定空间区域并动态追踪其在不同图像间的变化关系。
不同于现有方法依赖外部专用认知工具或仅局限于局部细节观察,这种方式不仅保持了模型原生的视觉推理能力,更支持其在多图场景下进行连贯的空间推理,不断更新和优化对空间状态的整体理解,真正实现“边看边画、边画边想”的认知过程。这种机制在处理需要多步骤、长序列的复杂空间推理任务时表现出显著优势,不仅提升了推理效率,更增强了结果的可解释性和可控性。
三阶段训练框架:系统化培养空间推理能力
为了有效提升视觉语言模型在空间推理任务上的表现,ViLaSR 使用了一种系统化的三阶段训练框架。该框架旨在从零开始逐步培养模型的空间理解与推理能力,使其能够像人类一样通过“画图辅助思考”的方式进行多步骤、深层次的空间分析。
第一阶段:冷启动训练(Cold-start Training)
训练的第一步是建立模型对视觉空间的基本认知能力。研究团队利用合成数据构建初始的视觉推理路径,并通过监督学习的方式训练模型执行基本的绘图操作,如标注边界框、绘制辅助线等。这些操作为后续复杂推理打下基础。
第二阶段:反思拒绝采样(Reflective Rejection Sampling)
第二阶段目标是增强其自我修正与反思能力。该阶段引入了反思拒绝采样机制,通过对模型生成的多个推理路径进行评估,筛选出那些展示出反思行为(如修改边界框、辅助线)的高质量样本进行强化训练。这种机制鼓励模型在面对不确定或错误的推理路径时主动识别并调整,并根据反馈动态优化解决方案。
第三阶段:强化学习(Reinforcement Learning)
最后一个阶段采用强化学习策略,进一步优化模型的整体推理能力和绘图操作的使用效率。在此阶段,模型通过结果奖励函数和格式奖励函数,同时关注答案的准确性与推理过程的逻辑性和格式合理性。格式奖励仅当结果奖励大于阈值(此处设置为0)时才获得,保证模型关注结果正确,避免仅优化格式奖励。这一阶段的目标是让模型能够在不同任务中自主选择最优的推理路径,并合理使用绘图工具,避免冗余操作。这一阶段不仅提升了模型的最终性能,也增强了其在多种空间推理场景下的适应能力。
实验表现
1. ViLaSR 在多个空间推理基准测试中表现优异
ViLaSR-7B 在包括迷宫导航(Maze)、静态图像理解(SpatialEval-Real)、视频空间推理(VSI-Bench)、多图像空间推理(SPAR-Bench, MMSI-Bench)五个主要空间推理基准上平均提升了 18.4% 。
这一显著提升表明,引入图像辅助思考机制,显著增强了模型在多类型任务中的泛化与空间推理能力,相较于纯文本推理更具适应性。
其中,在视觉空间理解最具挑战性的基准之一VSI-Bench 上,ViLaSR-7B 达到了45.4% 的平均准确率,显著优于Qwen2.5-VL-7B(+12.7%)。
2. 反思拒绝采样增强自我修正,强化学习优化绘图操作效率
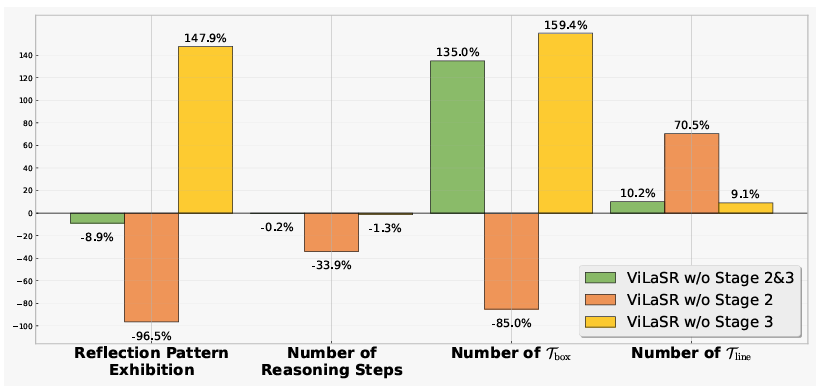
△消融实验。分数为相比于完整ViLaSR模型的关键行为相对提升百分比
通过消融实验发现,冷启动阶段首先帮助模型掌握“画图辅助思考”能力;去除反思拒绝采样阶段会导致:反思行为、推理步骤、绘图操作行为显著减少。这说明反思拒绝采样机制对模型在面对错误路径时的自我识别和修正起到了关键作用。
此外无强化学习版本与ViLaSR-7B相比,在多数子任务上性能下降,且绘图/绘制辅助线使用频率激增(+159.4% / +9.1%),表明强化学习有助于学习更精炼的操作策略。
数值类任务相比于多选任务,性能下降更明显(-9.21% vs. -4.07%),验证了强化学习提供的稠密奖励能更有效促进精确空间推理,相比于监督微调更具优势。
3. 具备类人空间推理策略
深入的案例分析表明,ViLaSR-7B不仅在性能上超越了现有方法,更展现出了类人的空间推理策略。如下图所示,模型掌握了以下关键能力:
1、基于参考物的度量推理:
在测量电话尺寸的任务中,模型展现出了成熟的参考物推理能力。它首先识别到单纯依靠像素测量无法得到准确结果,随后主动寻找具有已知尺寸的参考物(显示器),最终通过比例换算得出电话的实际尺寸。这种推理方式与人类解决实际测量问题的思路高度一致。

△基于参考物的度量推理示例
2、系统性的跨帧对象追踪:
面对需要理解多个画面中物体相对位置关系的任务时,模型采用了系统性的标注策略 – 在不同帧中标记相同物体的位置,并通过这些标记建立起物体之间的空间和时序关联。这种方法不仅确保了推理的准确性,也提高了结果的可解释性。

△系统性的跨帧对象追踪示例
本研究聚焦于空间推理任务,通过“Drawing to Reason in Space”范式,将绘图操作与多模态推理深度融合,使模型在视觉空间中“边画边想”,更有效地理解和推理复杂的时空关系,显著提升了大模型空间感知能力及推理的可解释性与可控性。该范式为机器人导航、虚拟助手等领域的空间智能奠定了基础,未来将继续推动多模态推理向通用性与高效性发展。
该工作的第一作者为中科院自动化所博士生吴俊飞,目前于蚂蚁技术研究院实习,蚂蚁技术研究院副研究员关健为共同第一作者。
论文地址: https://arxiv.org/abs/2506.09965
代码仓库: https://github.com/AntResearchNLP/ViLaSR
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)