

西风 梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
AI大牛梅涛坐镇,全新多模态AI问世!
用法上堪称:全能。

不仅支持图片、视频生成:

奇幻场景、多样视角都能驾驭:

而且唇形同步功能上线,社恐大“i”人也能玩转播客:
划重点:
官方还提供了上百种可直接套用的趣味特效模板,让用户实现“躺平创作”。

像下面这种炫酷转换,操作简单到只需上传一张图:
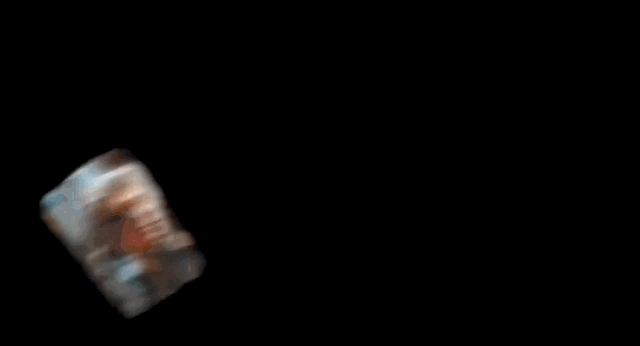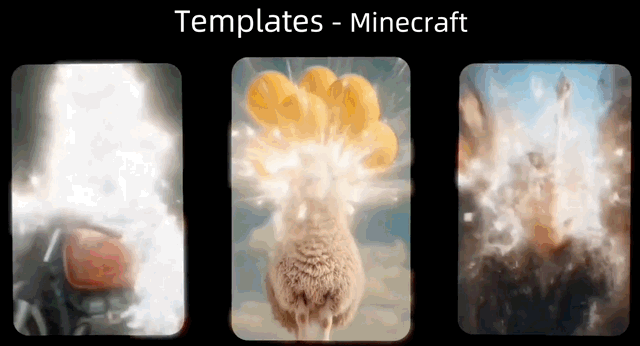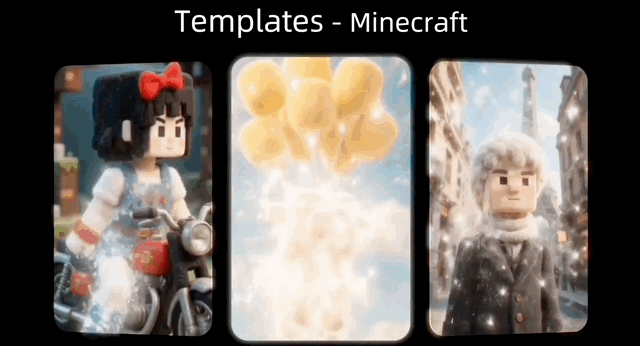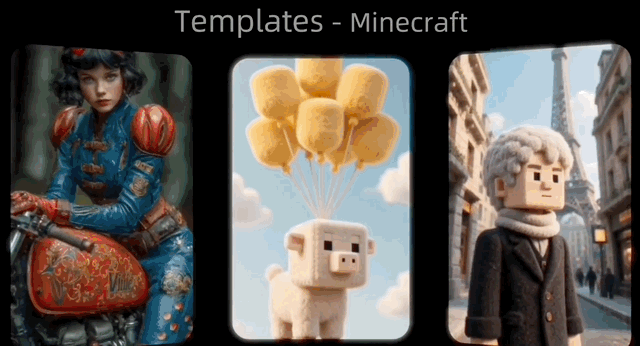
人物、动物、建筑物的“变身”模板通通都有:

另外,生图板块的Image Agent也是官方主打,修图生图只需大白话表述,不会写prompt不是问题,它会自动帮你优化修改。
不卖关子,这个最新创作工具就是vivago2.0(智小象AI)。
打造出它的团队智象未来(HiDream.ai),是圈内鼎鼎有名的大牛——加拿大工程院外籍院士梅涛创立的AI公司,研发团队中挤满了来自中科大的中坚。

前段时间,团队推出的开源模型HiDream-I1曾在文生图模型竞技场一鸣惊人,开源24小时就拿下了排行榜榜首,在国内一众开源大模型中率先跻身第一梯队。

当时,就连Recraft(曾神秘刷屏的小熊猫“red_hat”背后团队)也连夜加载,全球创作者竞相加入工作流。

有意思的是,vivago2.0其实结合了HiDream-I1的能力。

目前,vivago2.0已在Web端与App全球同步上线,有此等新玩具量子位自然不能错过,第一时间上手体验了一波。
同时我们也对其背后的模型来了个大揭秘。

全新多模态神器食用指南
vivago2.0主打六大玩法:图片生成、图片转视频、AI播客、特效模板、创意社区、话题。
下面我们逐一来看。
图片、视频、播客生成一套搞定
先看图片生成玩法,支持文本生图和“文本+参考图”生图。
纯文本生图中,vivago2.0解决了大伙儿不会写提示词的问题。
可以看到提示词输入框右下角有一个“提示词机器人”按钮:
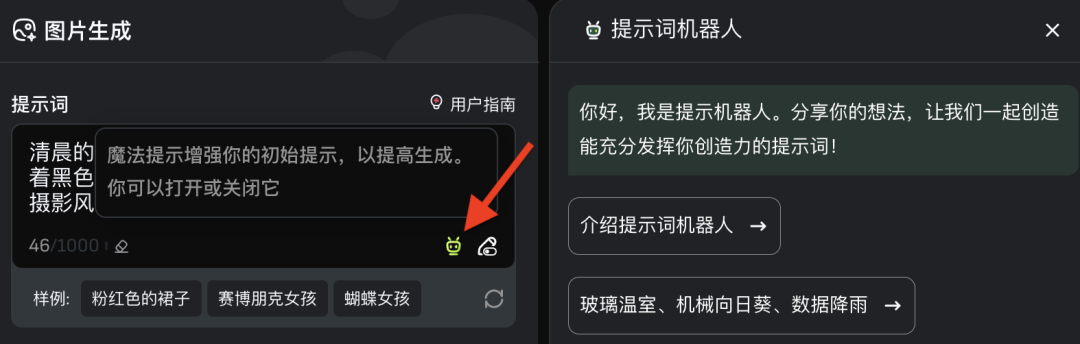
点开后,只需输入你脑海中的几个词,它就能帮你自动组织成具有创造力的完整提示词。可以点击“使用提示词”自动导入到提示词输入框中,也可以选择“引用”对其进一步修改。
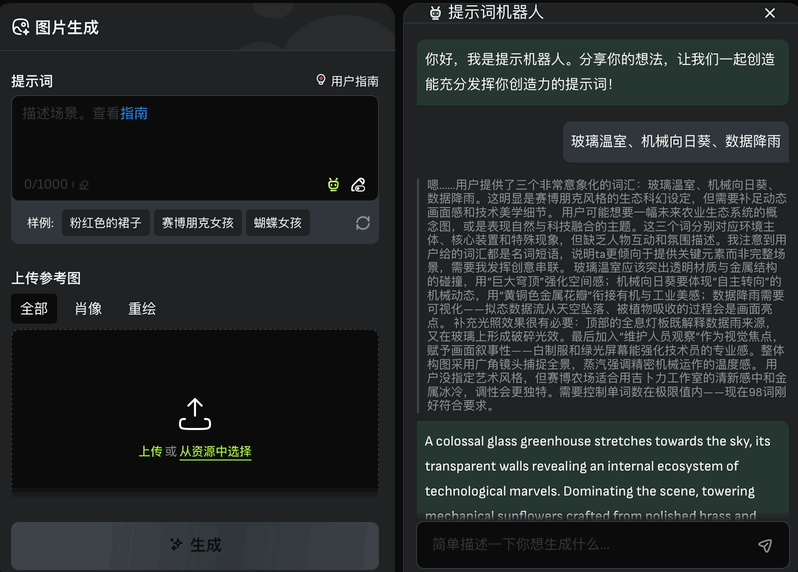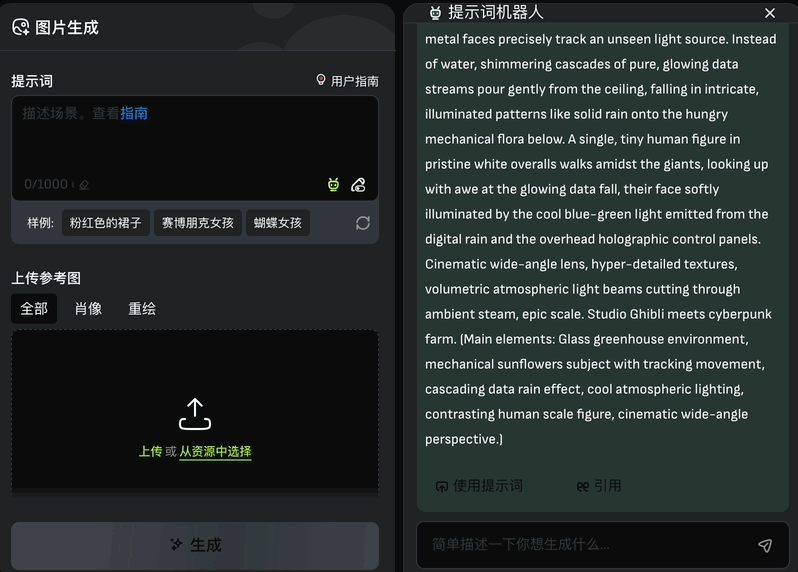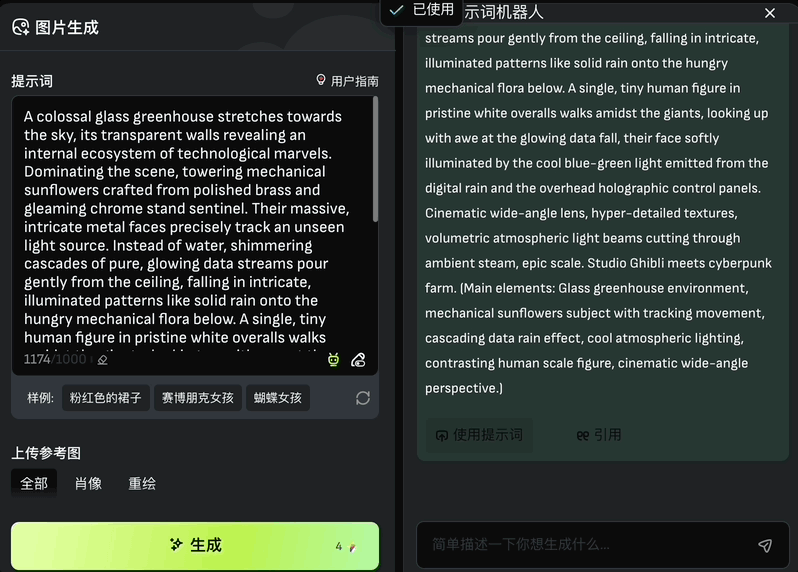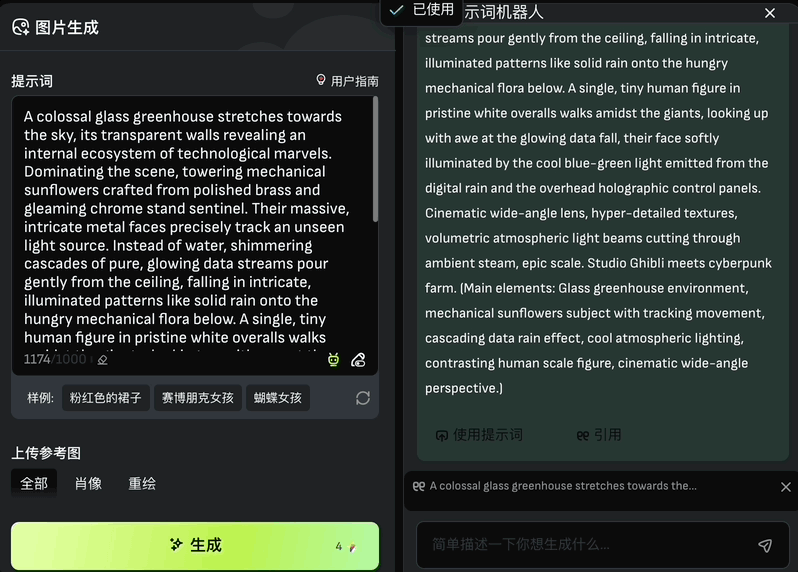
另外生成图片的数量、图片尺寸、负向提示词等也都能设置:

话不多说,来看效果。
生成一杯柠檬气泡水,几乎看不出AI痕迹,细节感十足:

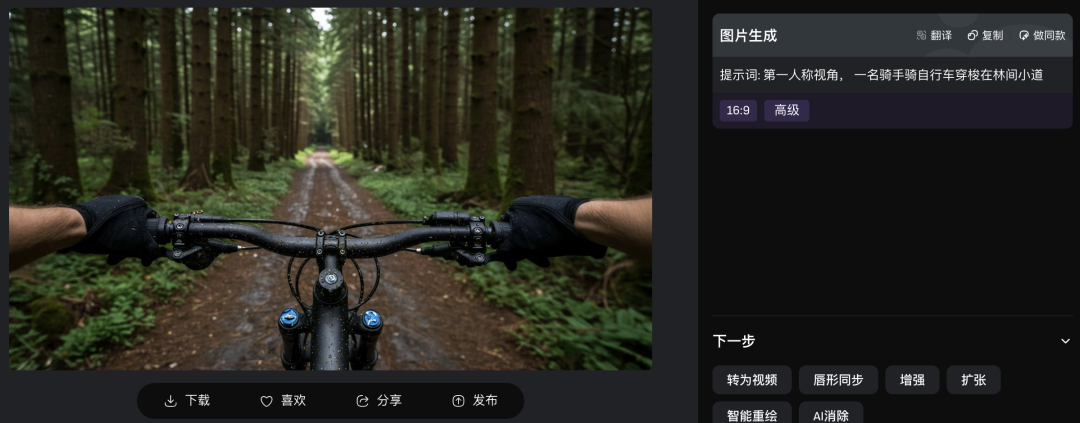
第一人称视角生图也可以,be like:
而文本+图像生图,也就是上传参考图的玩法,有全部、肖像、重绘三种设置。
全部即自动参考整张图生成;肖像即自动提取人物面部特征,生成面貌一致的不同风格图片;重绘则是将原图重新绘制成不同风格的图片。
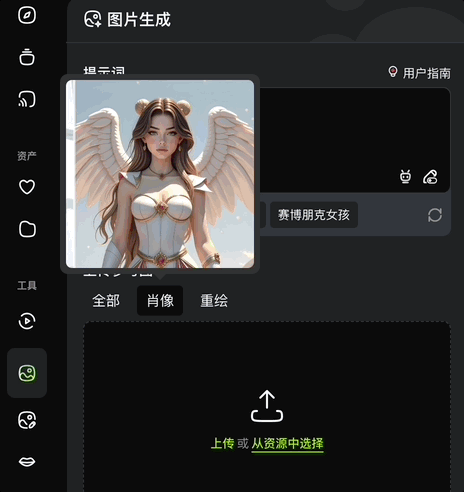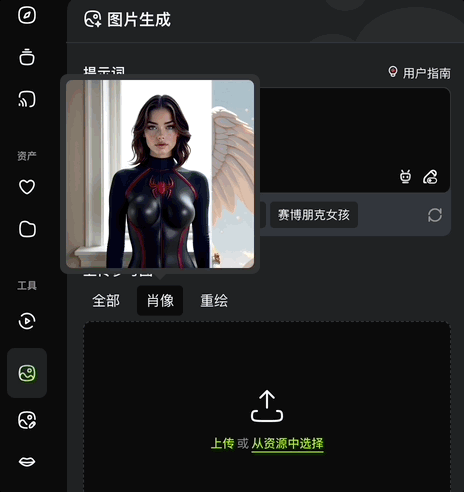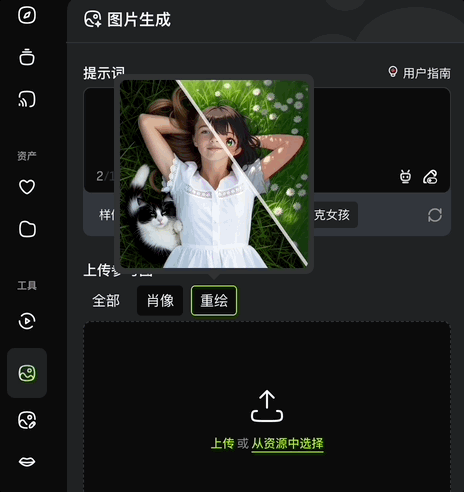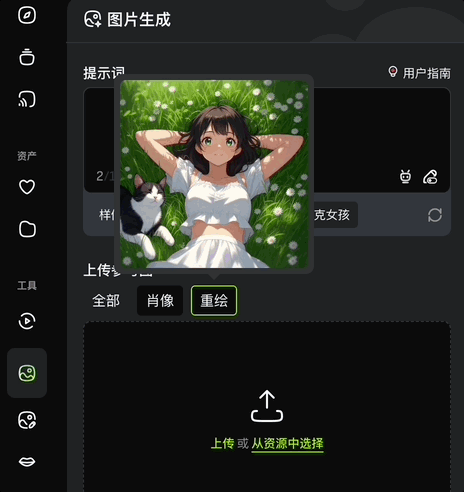
写实、插画、皮克斯、3D,各种风格通通拿捏:

△左边参考图,右边转赛博朋克风格
生图方面最重磅当属Image Agent,它提供了一种全新的图片生成交互形式。
就在一个聊天框中,用户可天马行空随意表达需求,不论是修图还是生图,Agent会基于上下文信息,准确判断理解用户意图。
生图和修图都可以批量完成。
例如生成小狗在草地追逐飞盘玩的图像,然后让它修改成像素风,vivago2.0可以四张图同时修改,并且和原图其它元素保持一致性。
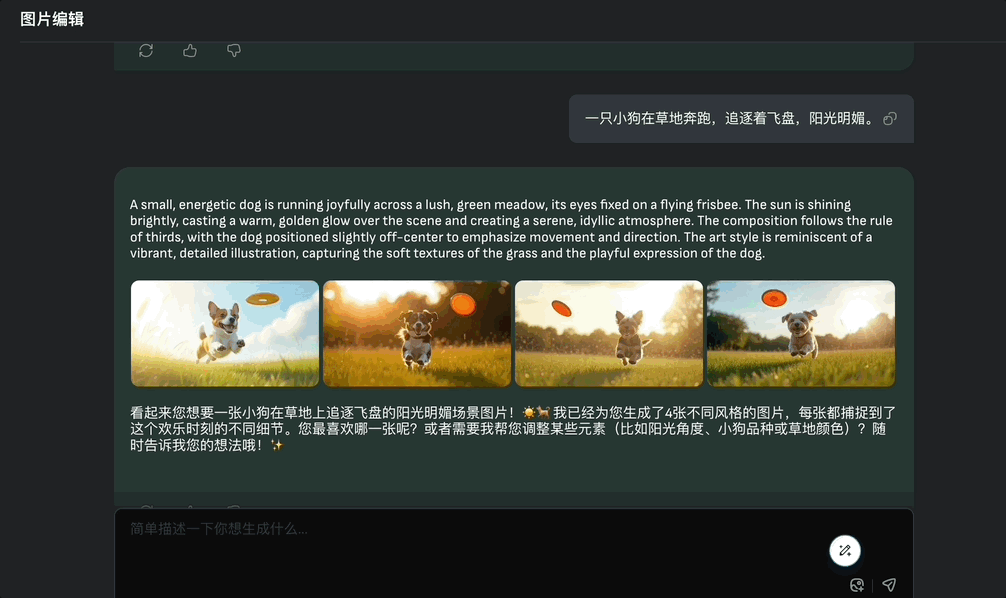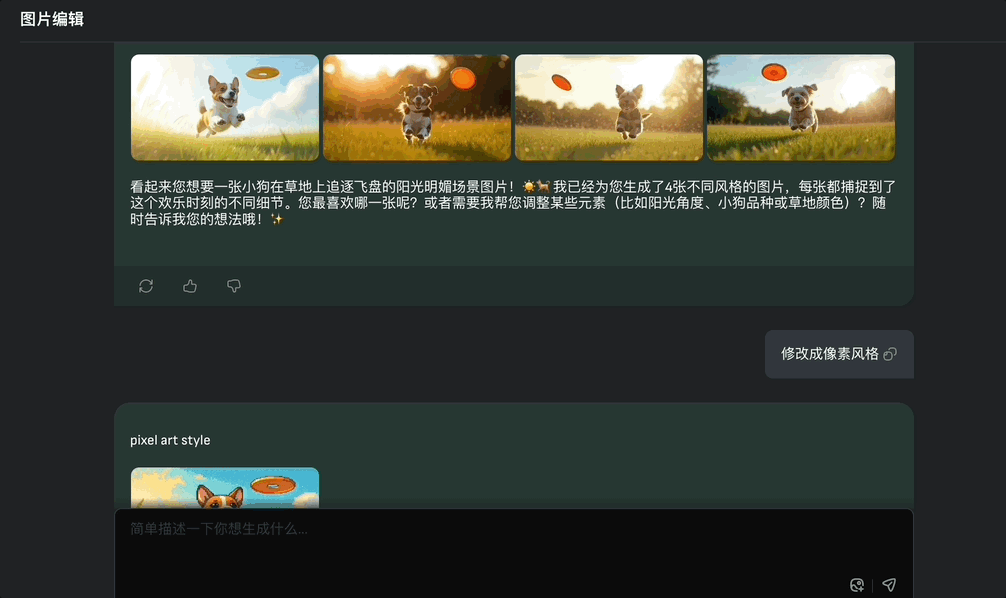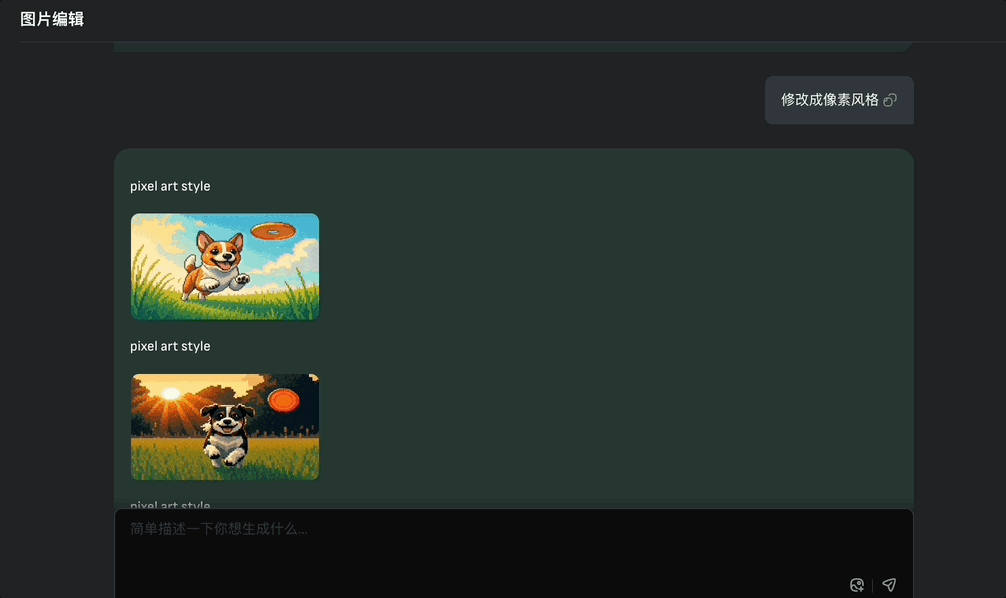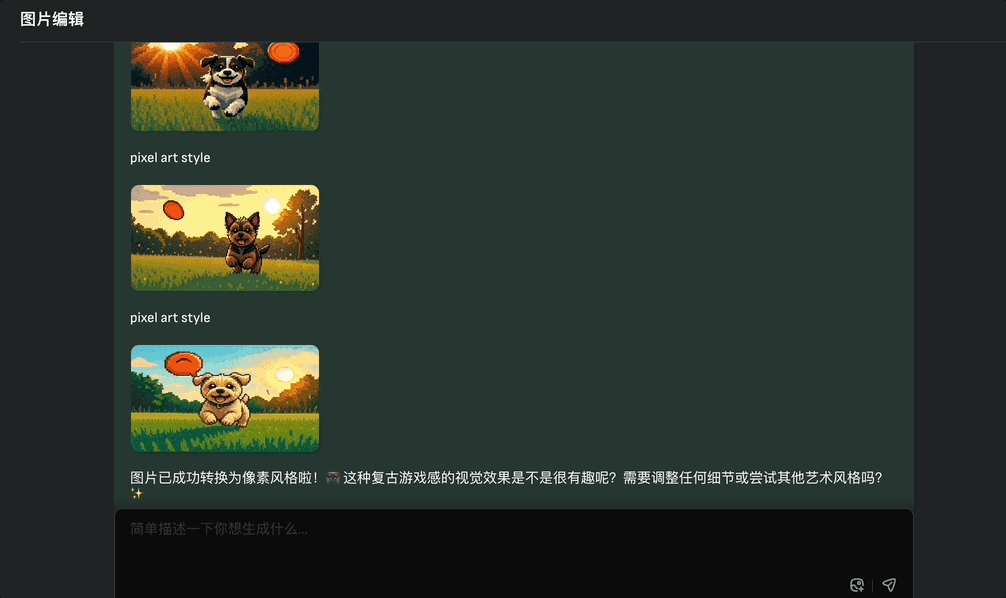
Image Agent还提供了“重写”、“帮我写”prompt的功能,创作点什么用户只需会用大白话表达就行。

接下来视频生成方面,同样是有图片生成视频和文字生成视频两种玩法。
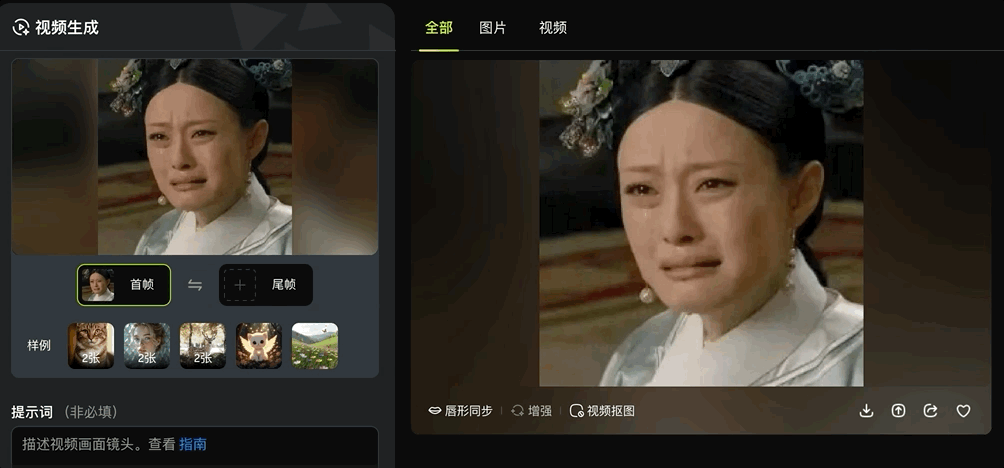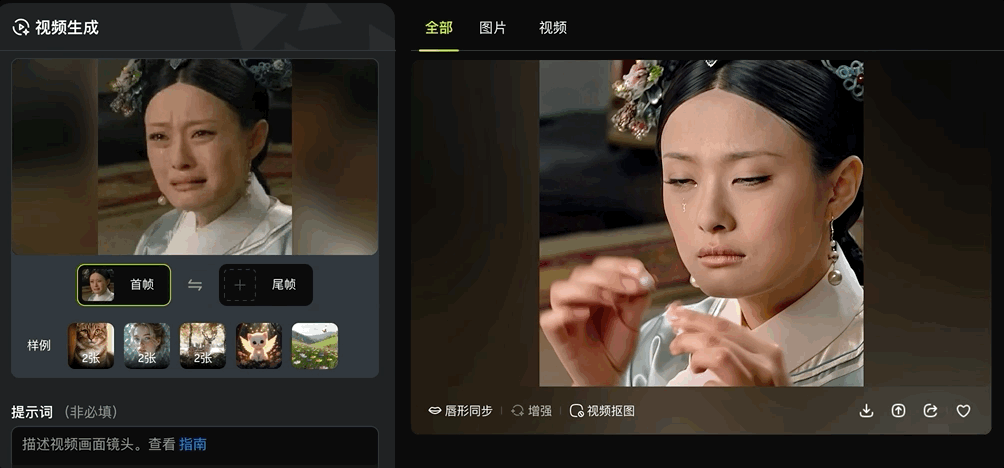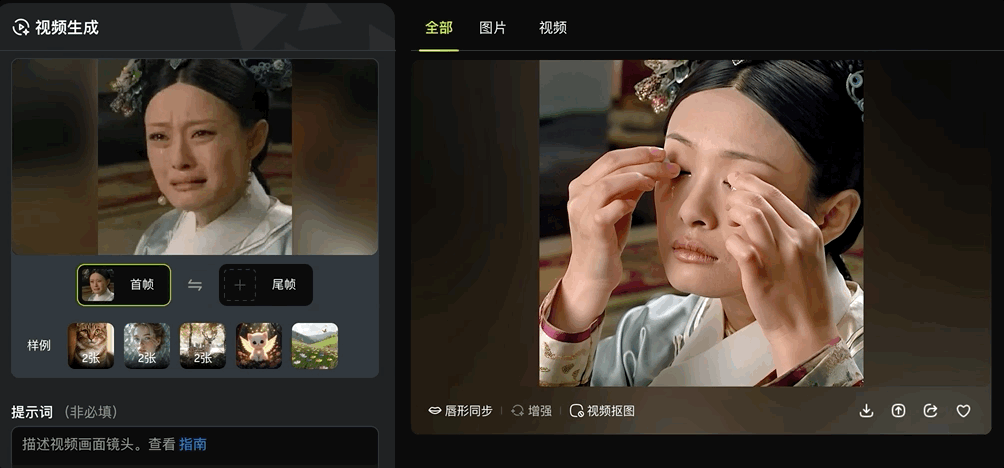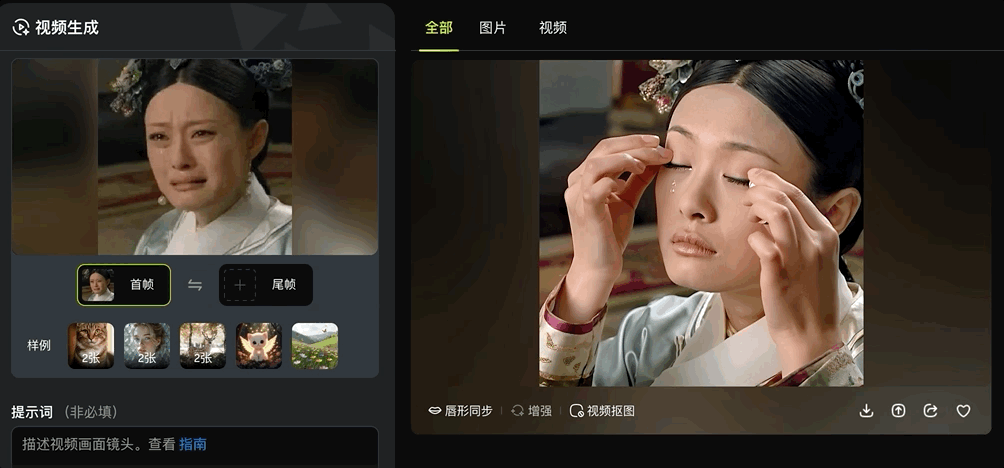
图片生成视频可以基于一张图生成,也能基于两张图设置首尾帧。
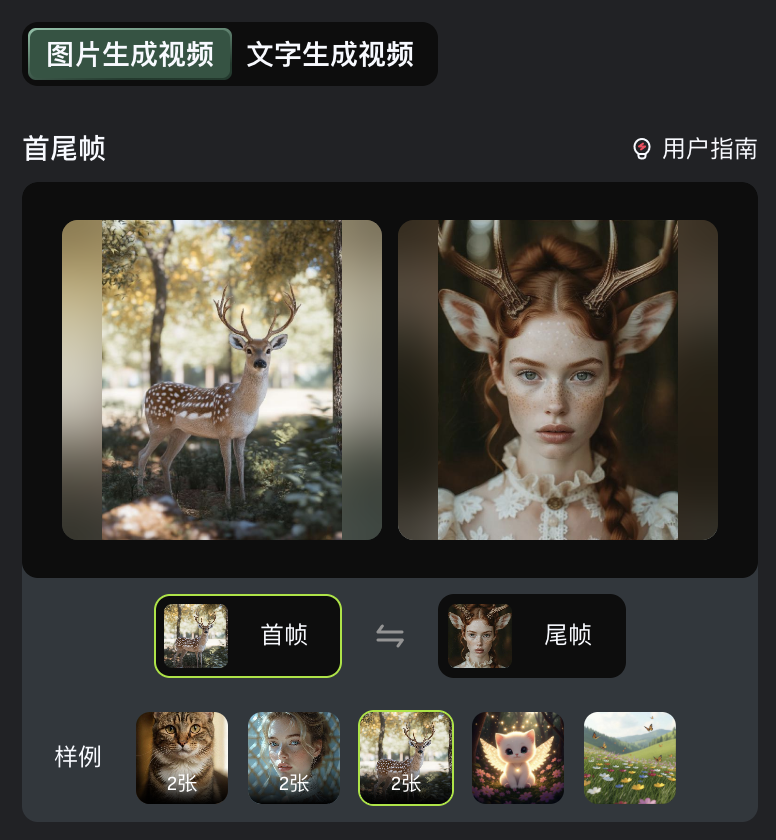
通过设置首尾两张关键帧,即可一键生成“变身”式连贯视频效果。

各种场景都能丝滑转换:

vivago2.0还有一个更为方便快捷的设计。
在图片生成界面,其实可以直接点击生成好的图片上的按钮,进行转视频等一系列操作。
于是乎,我们前面生成的骑自行车的图片,一键动了起来:
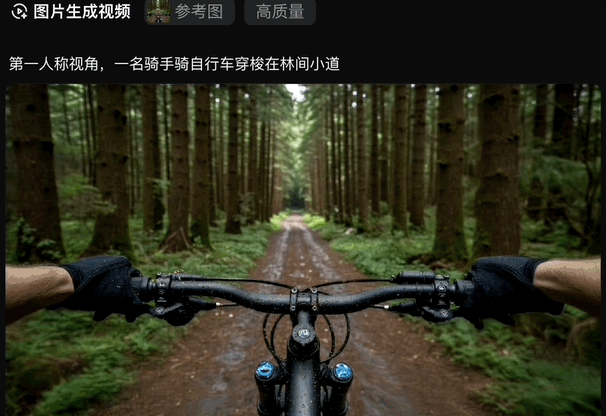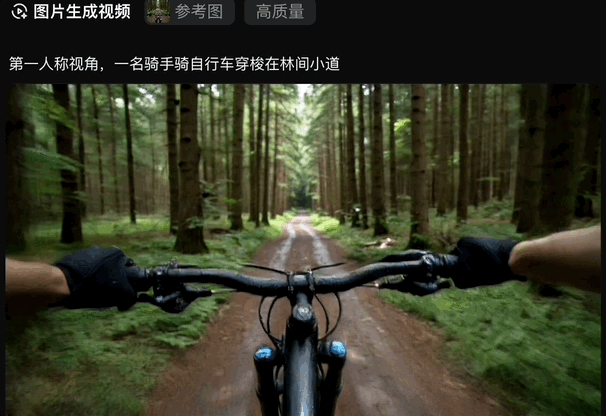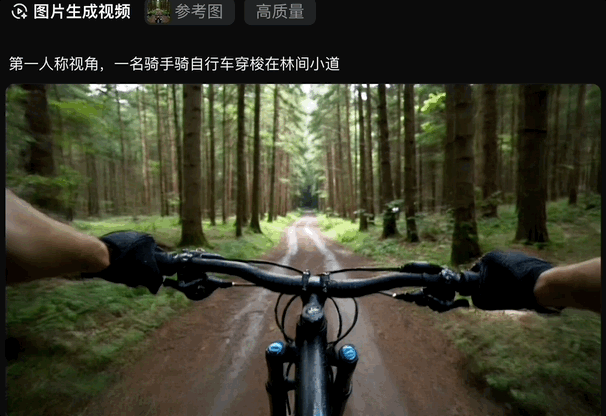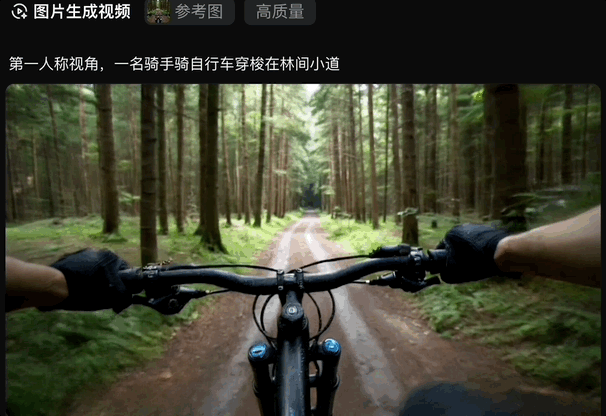
无论是写实风格的场景,还是充满想象力的奇幻画面,只需一句话,vivago2.0即可将其转化为动态视频呈现。
比如一只在海上冲浪的狗子:

再比如魔改静态表情包(我哭了,但眼泪是清凉油熏出来的),vivago2.0还会自动提升画质。
图片、视频看过后,再来看看AI播客功能。
AI播客制作功能也就是👄唇形同步,自己配音或者是写一段文本让AI配音都行。
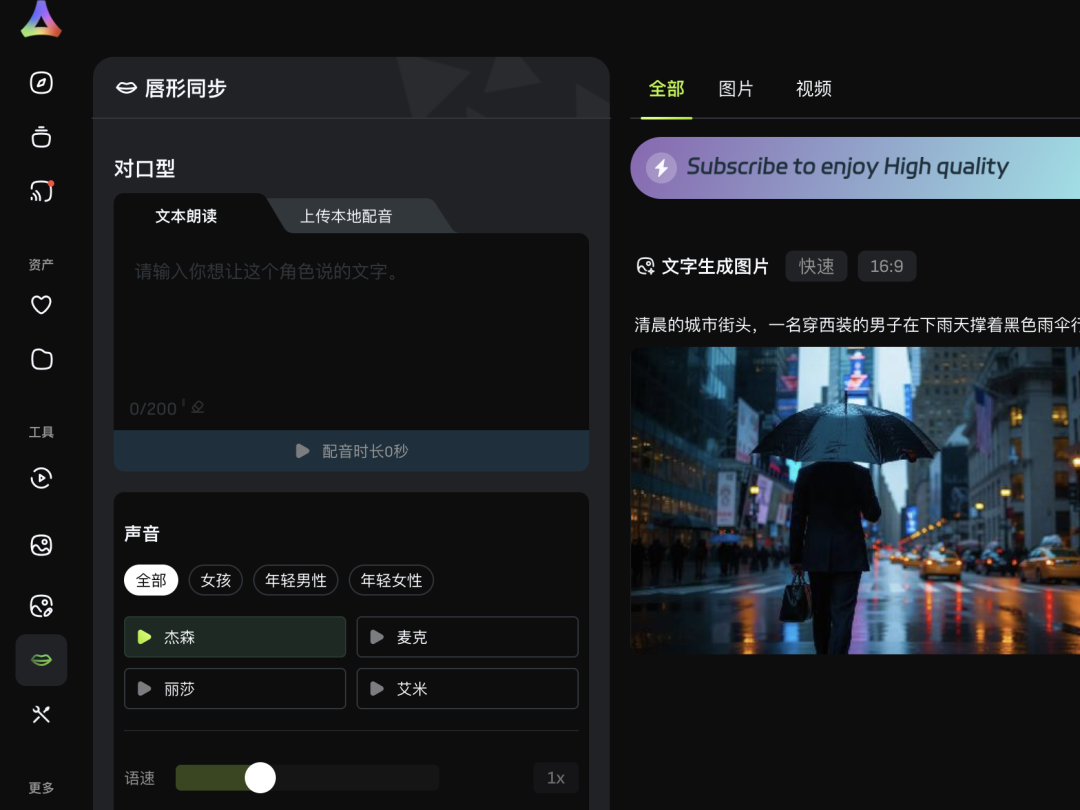
同样可以在生成的图片、视频基础上,直接生成。
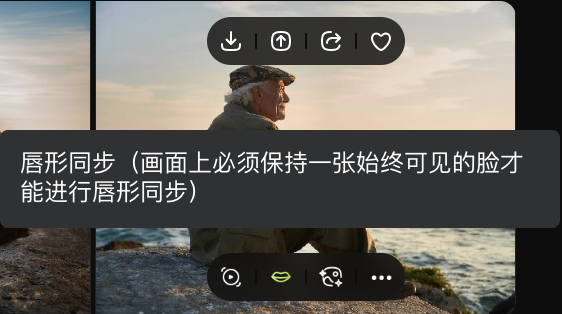
当输入文字 “Life is like a box of chocolates. You never know what you’re gonna get” 时,图片中的人物能根据文本自然地完成口型同步。
与此同时,人物的肢体动作也会随着话语同步变化。
我们特意挑选了一张侧脸人物图,口型同步依旧比较流畅自然。
vivago2.0还有更多社交、开放性玩法。
更多玩法,百种特效任你挑
首先要提的就是特效模板,官方提供了300+款花式模板,用户可以一键套用,小白也能秒变特效大师。
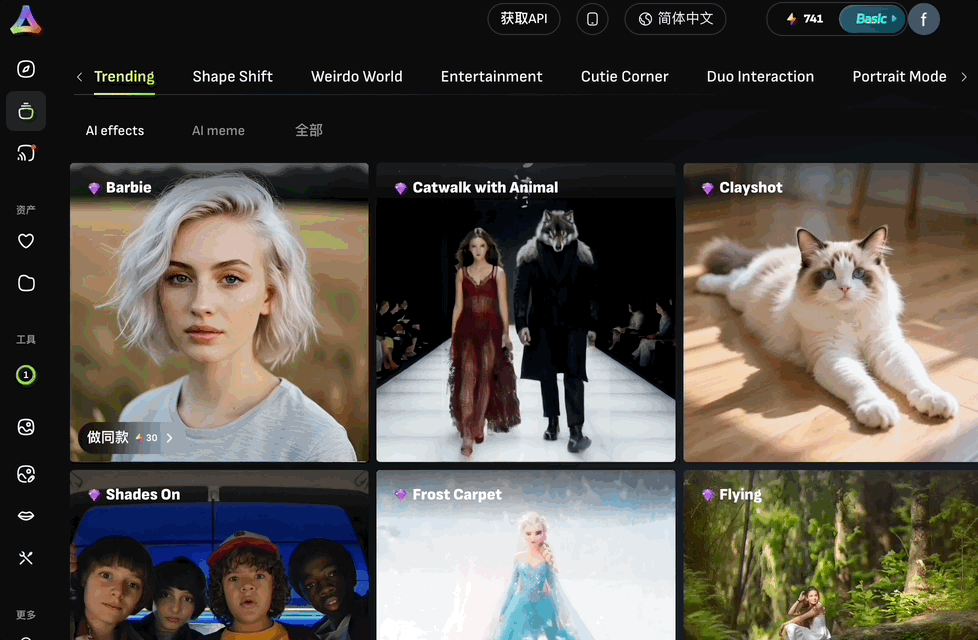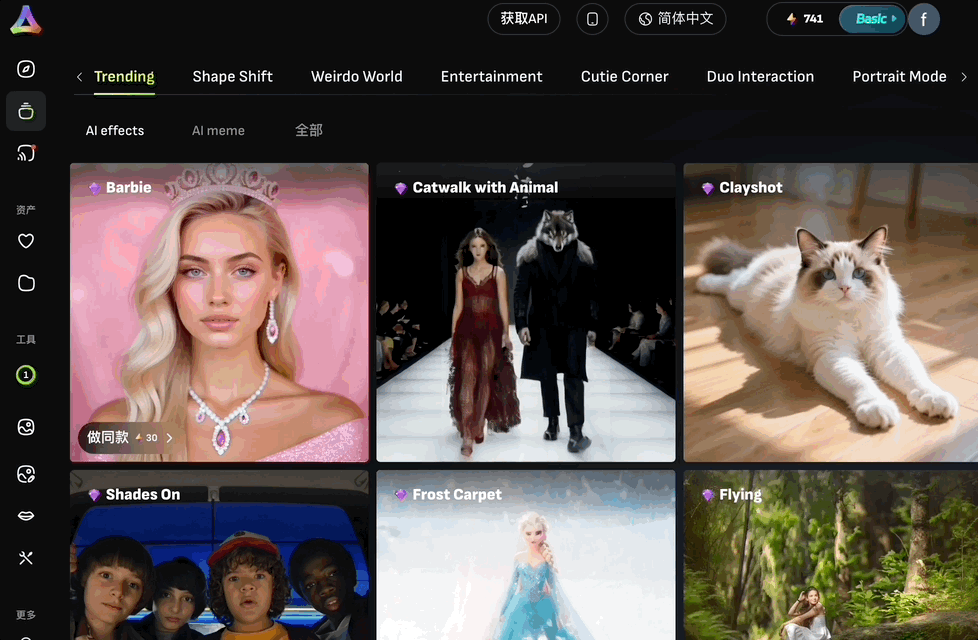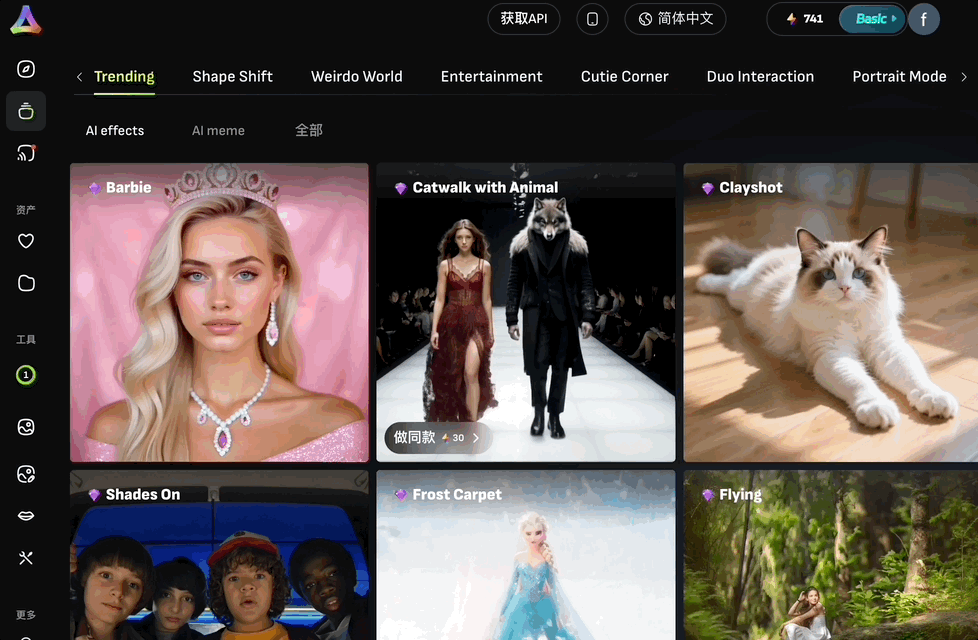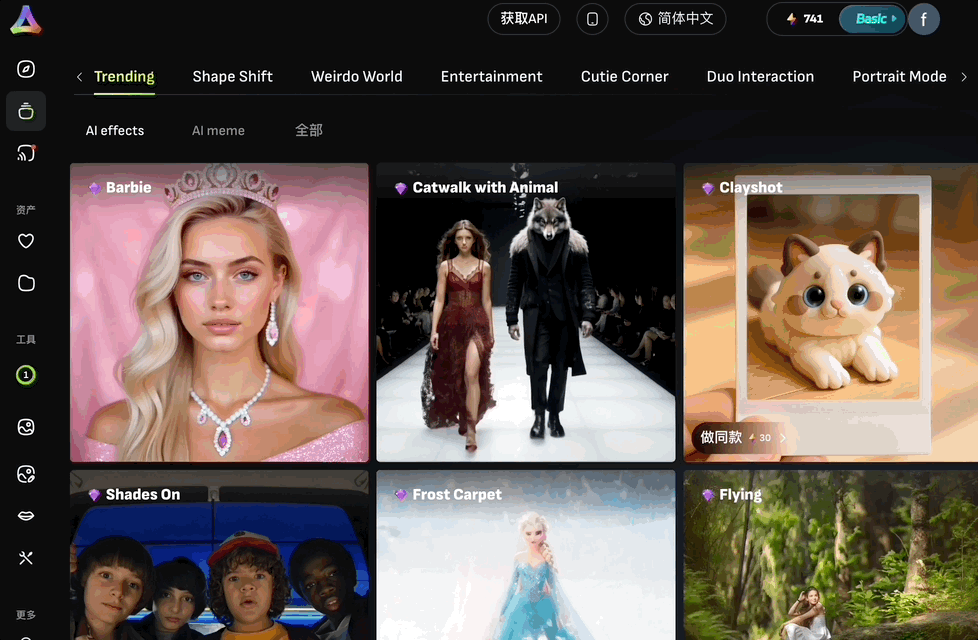
我们选择了一个特效后,然后上传一张AI生成的小女孩图片。
“啪”的一下小女孩丝滑换装:

创意社区也是个寻找灵感的好地方,创作者百万脑洞任你“借鉴”,可以直接使用同款prompt。
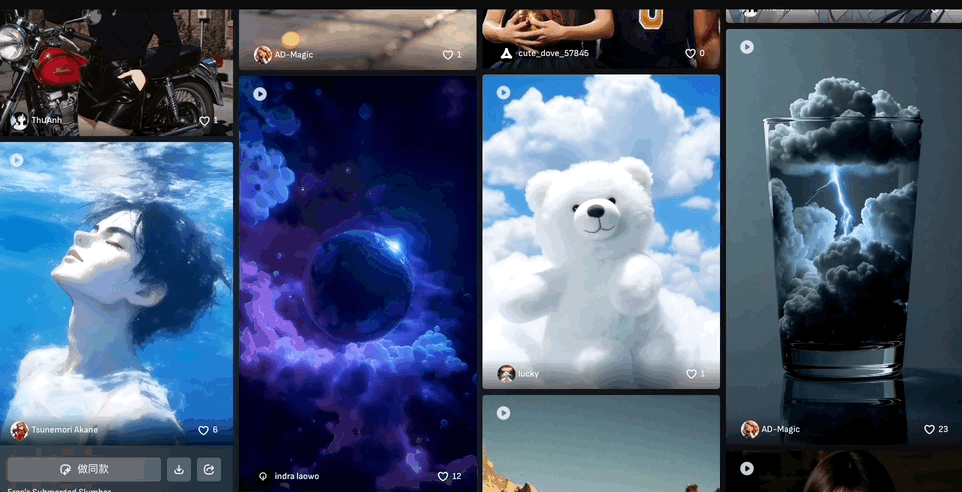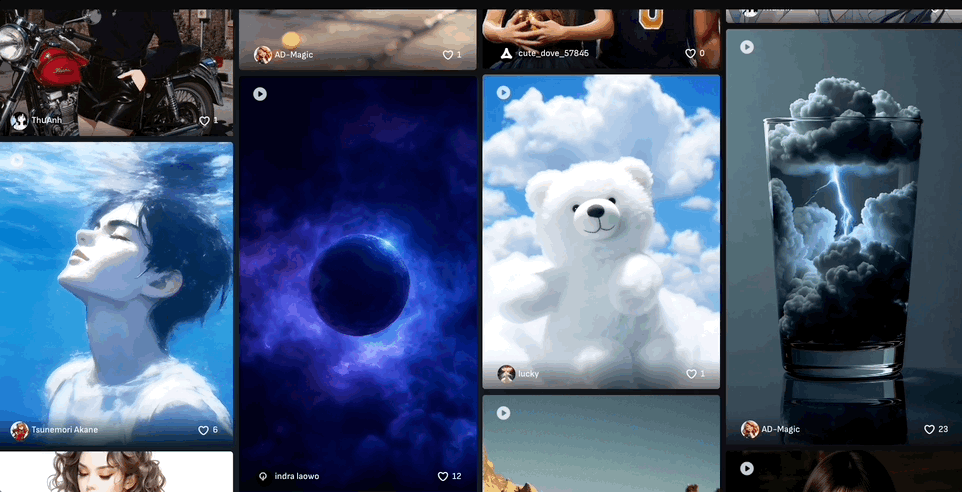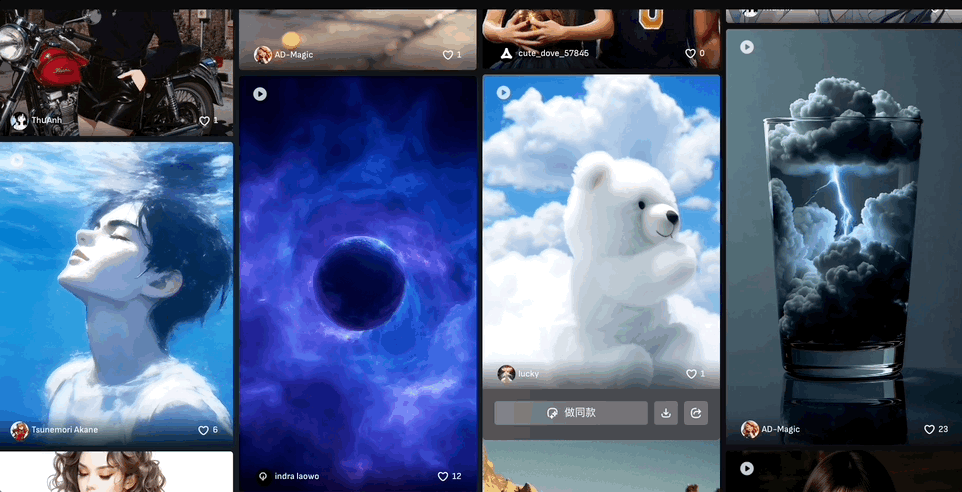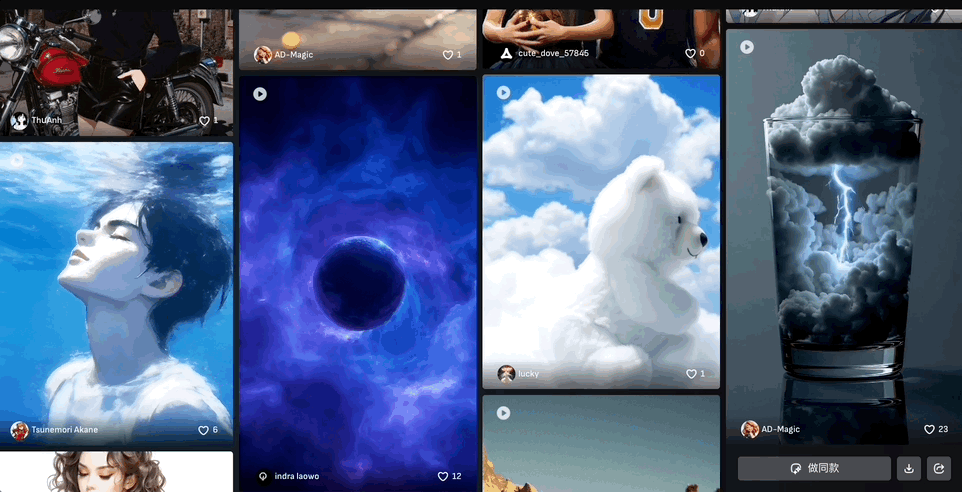
来看社区里更多的优秀案例:

除此之外,团队还即将上线话题功能,用户可以参与热门话题,提升自己作品的曝光度,目前该功能内测资格限量开放。
在vivago2.0的AI工具箱中,还涵盖着功能多元的工具模块,包括3D生成、AI试衣、视频抠图等等:
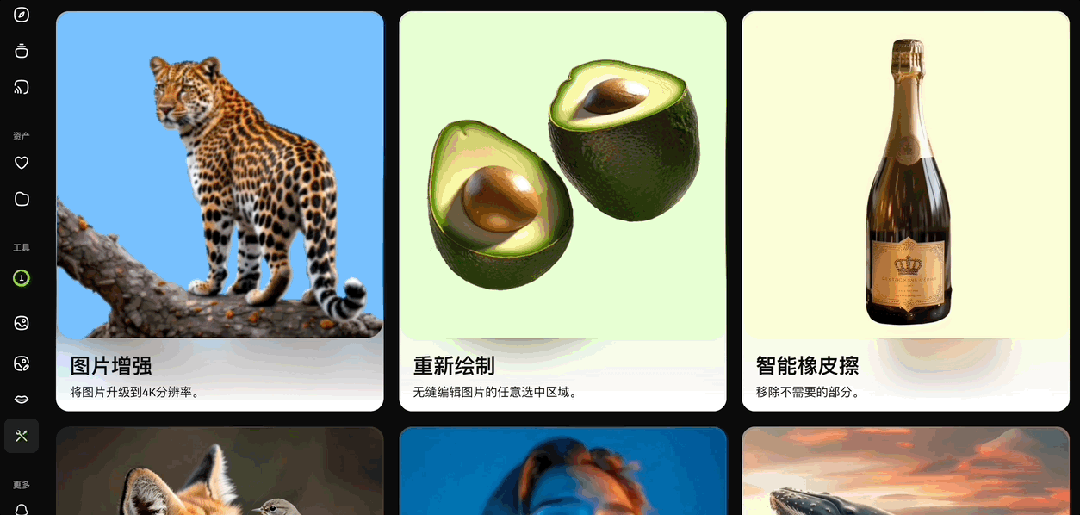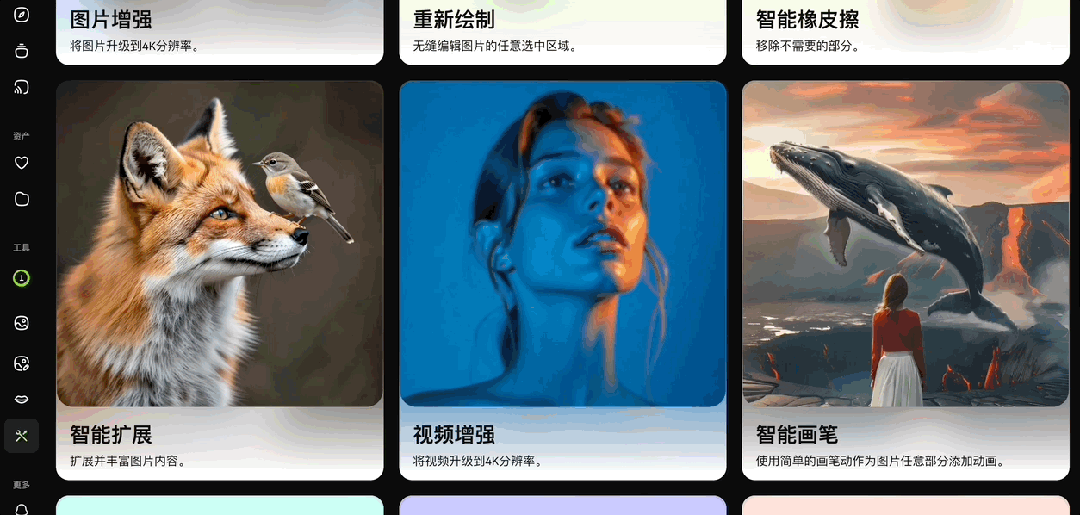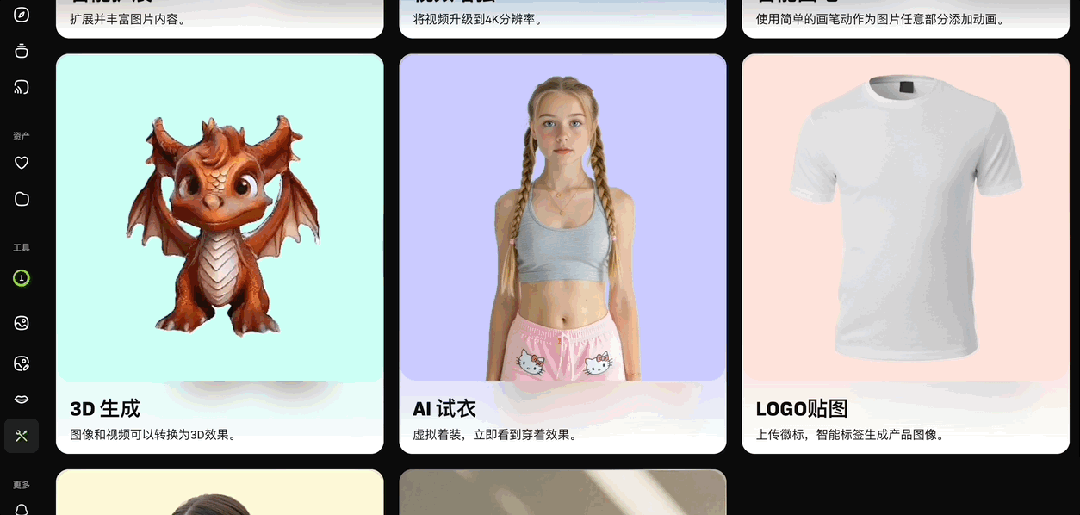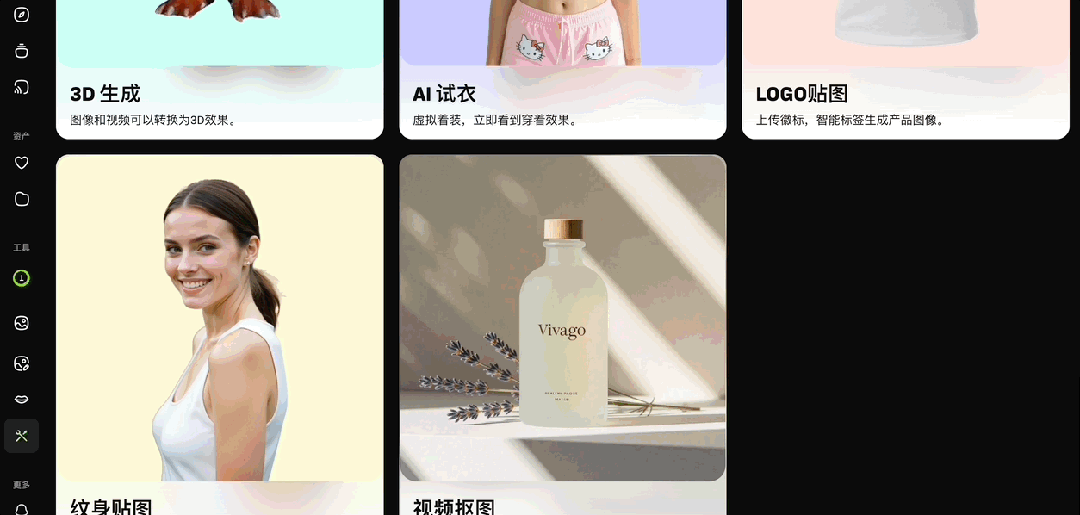
感兴趣的童鞋可以自己亲自上手探索一下。
By the way,vivago2.0推出后着实有点火,有时还会出现服务器拥堵的大状态。

开源SOTA的再进阶版
技术方面,vivago2.0新能力背后依托的全新图像Agent——HiDream-A1。
HiDream-A1结合了开源模型HiDream-I1、HiDream-E1的进阶版闭源模型(HiDream-I1.1、HiDream-E1.1)。
HiDream-I1是图像生成基础模型,参数170亿,总共开源三个版本:完整版HiDream-I1-Full、蒸馏加速版HiDream-I1-Dev、蒸馏极速版HiDream-I1-Fast。
HiDream-I1-Full是完整版本,需要50多步扩散步骤,追求的是极致画质。这个版本适合那些“慢工出细活”的创作场景,比如商业海报设计或艺术创作。
HiDream-I1-Dev是经过引导蒸馏的版本,将步数压缩到28步,在质量和速度之间找到了黄金平衡点。
而HiDream-I1-Fast则是极速版,仅需14步就能生成高质量图像,简直是为实时应用量身定制。
其中HiDream-I1-Dev开源不到24小时,就登顶Artificial Analysis图片生成竞技场。
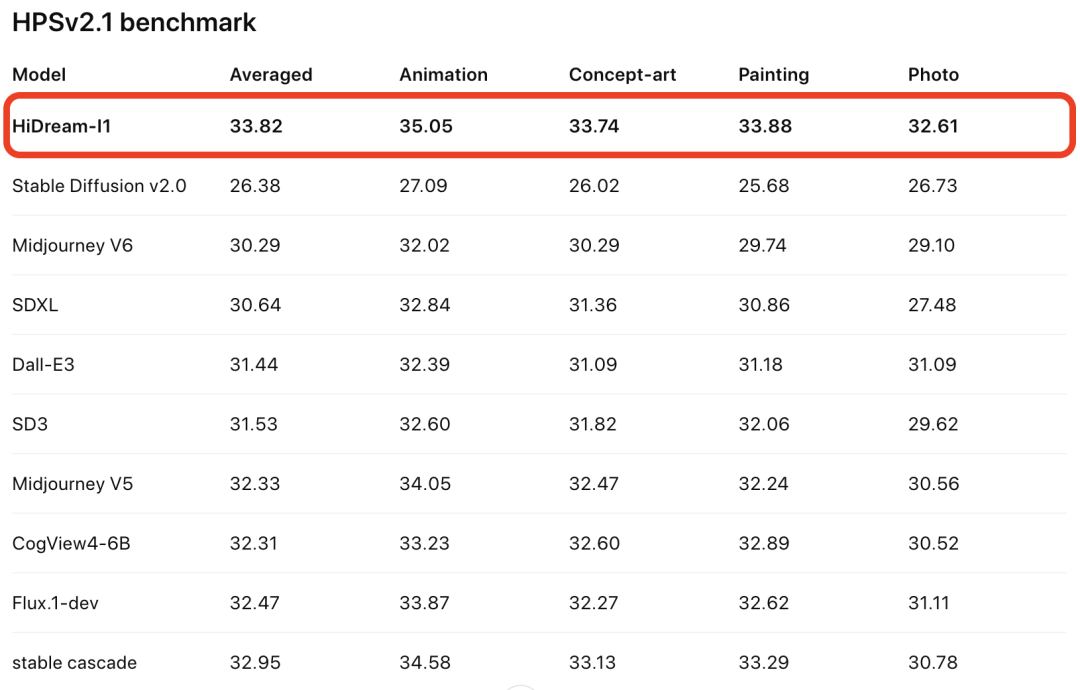
HiDream-I1在HPS(综合评测生成图像的语义相关性、画质和美感)基准上拿下SOTA:
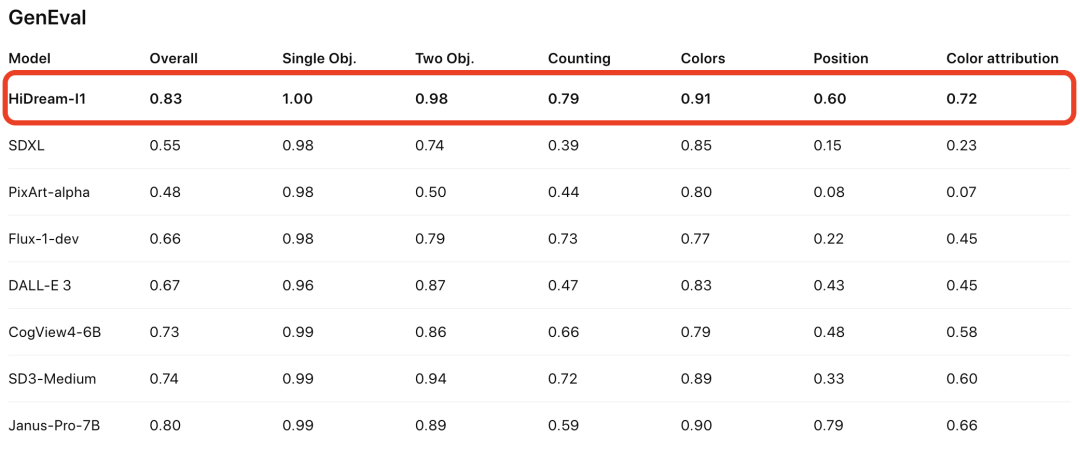
同时在GenEval和DPG-Bench(评测生成图像和输入文本的语义相关性)基准上,评测结果同样是SOTA:
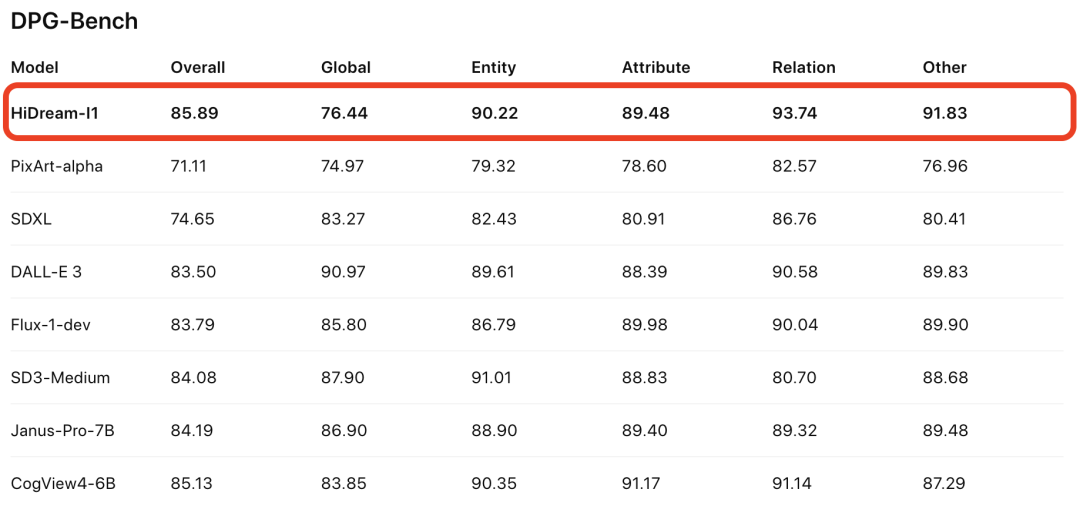
HiDream-E1是交互式图像编辑开源大模型,主打功能就是最近GPT-4o爆火的用嘴改图功能。
HiDream-I1+HiDream-E1可以称得上是开源版GPT-4o。
HiDream-I1的核心创新,是把稀疏混合专家(Sparse MoE)技术巧妙地融入到了扩散Transformer架构中。
他们设计了一个双流-单流混合的稀疏DiT结构。
具体来说,模型先用双流DiT分别处理图像和文本token,就像左右手各司其职。在这个阶段,每个模态都有自己的专属通道,可以充分提取各自的特征。随后,模型切换到单流DiT架构,让两种模态实现深度融合。
最妙的是,无论是双流还是单流阶段,团队都引入了动态MoE架构。这就像给模型装上了智能路由器,每个输入token都会被动态分配给最擅长处理它的专家模块。
在文本编码方面,HiDream-I1采用了“四管齐下”的混合策略:
长上下文CLIP提供视觉语义对齐,T5编码器负责解析复杂文本结构,Llama 3.1则贡献深层语义理解,而且还特意从LLM的多个中间层提取特征,避免了最终层输出中细节信息的流失。这种“集大成”的做法,让模型对文本提示的理解能力大幅提升。
训练策略上,团队采用了渐进式分辨率训练,从256×256开始,逐步提升到512×512,最终达到1024×1024。
智像未来团队并没有止步于文生图。他们还通过“上下文学习”方法,将HiDream-I1扩展成了指令式图像编辑模型HiDream-E1。用户只需要提供原图和编辑指令,模型就能精准地完成修改任务。
最终,团队将文生图的HiDream-I1和图像编辑的HiDream-E1整合,推出了综合性图像智能体HiDream-A1。
这个智能体就像是一个“全能图像助手”,既能根据描述生成图像,又能按照指令编辑图像,还能进行多轮对话式的创作和修改。让用户可以像和ChatGPT聊天一样,通过自然语言完成复杂的图像创作任务。
背后团队:AI大牛梅涛坐镇
智象未来成立于2023年3月,名字算新,但背后创始人,AI圈内无人不知——梅涛,加拿大工程院外籍院士,同时也是IEEE/IAPR/CAAI Fellow,是人工智能、计算机视觉和多媒体领域的世界级专家。
而智象未来的核心团队成员则来自微软、百度、腾讯、华为、京东、字节跳动等全球500强公司的核心技术团队,团队中博士、硕士占比超过90%,据说不少来自中科大。
团队成员多为AI视频技术出身,早在2017年,他们在ACM Multimedia大会发表了论文“To Create What You Tell: Generating Videos from Captions”。
现在看来这是学术界第一批研究文本生成视频的技术论文之一,只不过当时该研究方向还被称为Caption-to-Video。

虽然今天看来,当年他们用GAN(生成对抗网络)做出来的视频生成远谈不上完善,但不可否认其前瞻性。
而且正是因为在视频生成领域的坚持,让他们在AIGC方向的爆发时凭借技术积累再次取得突破:全球首个上线开放使用的图像和视频生成Diffusion Transformer(DiT)架构模型。
相较于大型科技公司动辄上万卡的超大规模投入,智象未来选择了一条更加务实的发展道路——技术上聚焦视觉多模态基础模型,产品上则表现为贴近商业化的可控图/视频生成。
而这一策略显然赢得了懂技术的投资人的青睐。
从2023年4月获得阿尔法公社、中喝大种子一号基金的种子轮融资,到2024年上半年完成敦鸿资本领投的近亿元Pre-A轮融资,再到2024年后续完成的以合肥产投为主的国资基金领投的A轮融资,智象未来的融资历程可谓顺风顺水。据了解,A轮融资规模已达数亿人民币,跟投方还包括安徽省人工智能母基金、湖北省长江电影集团有限公司等机构。
不论是融资速度还是规模,都能管窥资本市场对智象未来技术实力和商业化前景的认可。
梅涛对此也有着清晰的见解:“大语言模型需要大量的算力和融资,2023年需要千卡,2024年需要万卡,这是一个赢者通吃的领域。对于中国的创业公司来说,筹集这么一大笔资金有一定难度,要跟上大厂的竞争步伐也有难度。视频行业这个赛道不需要太大投入,规模可控,而且离商业化进展最近。”
而这一判断似乎也得到了市场的验证——2023年,全球AIGC约200亿美金的收入中,50%-60%来自视频和图像,其中Midjourney在这方面的收入已达2亿美金,已经验证了产品市场契合度(PMF)。
自2023年3月成立以来,智象未来在视觉多模态基础模型及应用领域不断深耕,发布了一系列令人瞩目的成果。
划重点了,智象多模态大模型,模型参数规模超百亿,实现对文本、图像、视频、3D的联合建模,并已通过模型和算法双备案。
基于此构建的“智象AI”系列产品,具备图像生成编辑、4K高清画面、全局/局部可控、剧本多镜头视频生成等功能,在AIGC技术和数字创意领域商业化方面优势显著。
2024年,智象未来的战略合作动作频频:与慈文传媒进行战略合作签约;和上影集团联合发布“AI+”合作计划;与中国移动咪咕联合发布首个国民级AIGC视频彩铃应用“AI一语成片”;还与寒武纪在北京签订战略合作协议。
到了2024年12月28日,智象未来在安徽人工智能产业先导区启动仪式中,全球首发智象多模态生成大模型3.0与智象多模态理解大模型1.0。
其中,智象多模态生成大模型3.0实现图像和视频生成能力全面升级,包括画面质量与相关性提升、镜头运动和画面运动更可控,以及多场景驱动的优化。
而智象多模态理解大模型1.0版,则通过对物体级别的画面建模以及事件级别的时空建模,达成更精细、准确的图像与视频内容理解。

创业不易,尤其是在AIGC这个千帆竞发的赛道上。但梅涛的目标不仅仅是商业上的成功,还有着更为宏大的使命感。
“我创业不是代表一个人创业,是代表中国的科技型专家创业,投身到一个新的时代,要趟出一条路。如果我的技术和商业化能够打通,那么我的故事应该被复制,启发更多的人做这件事”,梅涛如是说。
下一步,智象未来将重点聚焦多模态大模型的应用与商业化。
在2023-2025年期间,智象未来的商业模式经历了显著演进。
2023年,以MaaS模式提供基础模型能力,初步建立起技术基础,为后续发展筑牢根基。2024年,转向SaaS模式,推出工具化产品,在专业场景中验证了应用价值,进一步明确了商业方向。到2025年,开启新战略,聚焦“IP二创+C端下沉”,旨在构建规模化商业生态,整合上下游资源,实现商业价值的最大化。
这也符合AIGC产品的普遍发展路径——先满足专业用户的高要求,再逐步简化操作门槛,实现产品的大众化应用。
从MaaS到SaaS,再到RaaS,智象未来不再卖工具,而是直接交付增长。
毫无疑问,随着多模态AI能力的涌现,2025年注定是属于多模态技术和产品的爆发之年,AIGC视频生成也被视为“抖音”一样的新一代超级平台……但明确的趋势和风口之下,只有真正有技术实力、有产品sense、商业化节奏清晰的团队,才能扶摇直上。
而智象未来,现在正在展现出这样的特质和潜力。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟
(文:量子位)