
点击上方“蓝色字体”关注我,每天推送“实用有趣的项目”!
最近,西北工业大学、香港大学和微软等团队联合推出了一个非常炫酷的开源项目:Freestyler,一个全新的说唱生成模型。
通过人工智能技术,Freestyler 可以根据歌词和伴奏直接生成自然流畅的说唱人声,甚至模仿指定说唱歌手的音色。
项目介绍
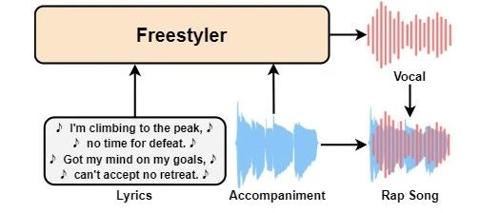
Freestyler 是西北工业大学与微软等团队共同开源的一个说唱(Rap)生成模型。
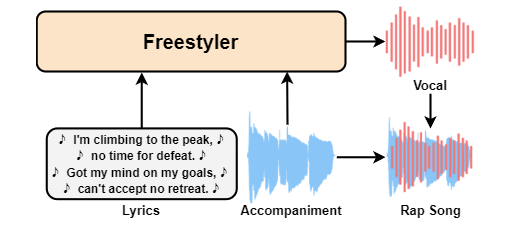
Freestyler 能够将歌词、伴奏音乐和参考人声作为输入,直接输出高质量、节奏感强的说唱人声。
与传统的音乐生成技术不同,Freestyler 不仅在音色上模仿特定说唱歌手,还能在节奏和伴奏的匹配度上表现出色。
核心功能
-
• 节奏与伴奏匹配度高:生成的说唱能与伴奏音乐的节奏完美融合,听感流畅。
-
• 支持模仿音色:通过参考的 3 秒人声样本,Freestyler 可模仿特定说唱歌手的音色,为创作者提供无限可能。
-
• 自然度高:生成的说唱人声不仅语音清晰,还具有自然的情感表达,媲美真实演唱。
主要输入内容
-
• 歌词:提供你的创意文字,Freestyler 会将其转化为充满节奏感的歌词朗读。
-
• 伴奏音乐:Freestyler 根据伴奏调整节奏、情感和演唱风格。
-
• 参考人声:上传短短 3 秒的音色样本,Freestyler 即可模仿该音色进行说唱生成。
技术细节解析
架构特点
Freestyler 的核心技术框架融合了以下关键模块:
1、文本到节奏转换
模型会根据歌词语义和伴奏的节奏分析,将文字分解为符合节拍的音节。
2、音色模仿
通过对参考人声的特征提取,模型能够捕捉特定的音色特质并应用到生成的说唱中。
3、风格适配
根据伴奏的情感、风格等元素调整生成说唱的演唱模式,确保整体一致性。
核心技术优势
-
• 使用先进的深度学习算法,对人声生成的自然度和节奏匹配进行优化;
-
• 数据集训练量大,覆盖多种音乐风格和语音特征,确保模型的泛化能力;
-
• 支持高效推理,在多种计算资源下表现优秀。
RapBank 数据集:AI 说唱的基石
Freestyler 的研发离不开 RapBank 数据集 的支持,这是一个专门为说唱生成任务打造的公开数据集。
RapBank 数据集特点:
-
• 规模丰富:包含大量歌词、伴奏、配套人声文件,覆盖多种说唱风格。
-
• 对齐数据:歌词、伴奏与人声样本的节奏严格对齐,为模型训练提供了高质量样本。
-
• 免费开放:任何开发者都可以在 HuggingFace 上获取数据集,方便社区共同推进技术进步。
潜在应用场景
🎤 音乐创作辅助
为音乐制作人和独立艺术家提供工具,快速生成说唱样本,节省创作时间和成本。
📱 个性化内容生成
结合短视频、社交媒体等平台,Freestyler 可以为用户生成专属的创意说唱内容,提升互动性。
📚 语言学习和教育
通过生成说唱的方式,帮助学生记忆单词或学习语法,用趣味性的方式提升学习效果。
🎮 游戏和虚拟角色语音
在游戏或虚拟现实场景中,生成与情节匹配的说唱台词,为用户带来更沉浸的体验。
写在最后
Freestyler 不仅展示了 AI 在音乐领域的创造力,还为普通用户打开了音乐创作的大门。从模仿偶像歌手到创作个性化内容,这一技术充满了无限可能。
从歌词创作到音色模仿,甚至是节奏调控,都变得轻松又高效。
来源:
GitHub: https://github.com/NZqian/RapBank
论文: https://arxiv.org/abs/2408.15474
Demo: https://nzqian.github.io/Freestyler/
(文:开源星探)